针对Oracle 11g 之前版本的行列转换,之前整理过一篇文档:
Oracle 行列转换 总结
http://blog.csdn.net/tianlesoftware/article/details/4704858
在Oracle 11g中,Oracle 又增加了2个查询:pivot 和 unpivot。
pivot:行转列
unpivot:列转行
在官网上有一点介绍这两个函数的使用文档:
http://docs.oracle.com/cd/E11882_01/server.112/e26088/statements_10002.htm#SQLRF01702
不过也不详细,google 一下,网上有一篇比较详细的文档:
http://www.oracle-developer.net/display.php?id=506
根据以上链接的内容重新测试整理一下。
一.Pivot 和 unpivot语法说明
1.1 pivot 语法

语法如下:
SELECT ...
FROM ...
PIVOT [XML]
(pivot_clause
pivot_for_clause
pivot_in_clause )
WHERE ...
In addition tothe new PIVOT keyword, we can see three new pivot clauses, described below.
--在上面的语法中有3个clause:
(1)pivot_clause: definesthe columns to be aggregated (pivot is an aggregate operation);
--这个是指定我们的聚合函数,有关聚合函数参考:
Oracle 聚合函数(Aggregate Functions)说明
http://blog.csdn.net/tianlesoftware/article/details/7057249
(2)pivot_for_clause: definesthe columns to be grouped and pivoted;
--指定我们需要将行转成列的字段
(3)pivot_in_clause: definesthe filter for the column(s) in the pivot_for_clause (i.e. the range of valuesto limit the results to). The aggregations for each value in thepivot_in_clause will be transposed into a separate column (where appropriate).
--对pivot_for_clause 指定的列进行过滤,只将指定的行转成列。
如:
SQL> WITH pivot_data AS (
2 SELECT deptno, job, sal
3 FROM emp
4 )
5 SELECT *
6 FROM pivot_data
7 PIVOT (
8 SUM(sal) --<-- pivot_clause
9 FOR deptno --<-- pivot_for_clause
10 IN (10,20,30,40) --<-- pivot_in_clause
11 );
JOB 10 20 30 40
--------- ---------- ---------- --------------------
CLERK 1430 2090 1045
SALESMAN 6160
PRESIDENT 5500
MANAGER 2695 3272.5 3135
ANALYST 6600
5 rows selected.
The pivot_clause letsyou write cross-tabulation queries that rotate rows into columns, aggregatingdata in the process of the rotation. The output of a pivot operation typicallyincludes more columns and fewer rows than the starting data set.The pivot_clause performs the following steps:
--pivot 通过交叉查询将行转成列,将指定的行转换成列,转换时执行以下步骤:
1.The pivot_clause computesthe aggregation functions specified at the beginning of the clause. Aggregationfunctions must specify a GROUP BY clause to return multiplevalues, yet the pivot_clause does not contain anexplicit GROUP BY clause. Instead,the pivot_clause performs an implicit GROUP BY. Theimplicit grouping is based on all the columns not referred to inthe pivot_clause, along with the set of values specified inthe pivot_in_clause.).
2.The groupingcolumns and aggregated values calculated in Step 1 are configured to producethe following cross-tabular output:
(1)All theimplicit grouping columns not referred to in the pivot_clause, followed by
(2)New columnscorresponding to values in the pivot_in_clause Each aggregated valueis transposed to the appropriate new column in the cross-tabulation. If youspecify the XML keyword, then the result is a single new column thatexpresses the data as an XML string.
The subclauses ofthe pivot_clause have the following semantics:
--pivot 有如下子句:
(1)XML
The optional XML keyword generates XML output for the query.The XML keyword permits the pivot_in_clause to containeither a subquery or the wildcard keyword ANY. Subqueriesand ANY wildcards are useful whenthe pivot_in_clause values are not known in advance. With XML output,the values of the pivot column are evaluated at execution time. You cannotspecify XML when you specify explicit pivot values using expressionsin the pivot_in_clause.
When XML outputis generated, the aggregate function is applied to each distinct pivot value,and the database returns a column of XMLType containing an XML stringfor all value and measure pairs.
--XML 将结果以XML 输出。使用XML后,在pivot_in_clause 选项中可以使用subquery 或者 ANY 通配符。 如果我们在pivot_in_clause中指定了pivot的具体值,就不能使用XML。
(2)expr
For expr,specify an expression that evaluates to a constant value of a pivot column. Youcan optionally provide an alias for each pivot column value. If there is noalias, the column heading becomes a quoted identifier.
--这个就是前面说的具体的值,根据这些值转换成pivot column。
(3)subquery
A subquery isused only in conjunction with the XML keyword. When you specify asubquery, all values found by the subquery are used for pivoting. The output isnot the same cross-tabular format returned by non-XML pivot queries. Instead ofmultiple columns specified in the pivot_in_clause, the subquery produces asingle XML string column. The XML string for each row holds aggregated datacorresponding to the implicit GROUP BY value of that row. TheXML string for each output row includes all pivot values found by the subquery,even if there are no corresponding rows in the input data.
The subquerymust return a list of unique values at the execution time of the pivot query.If the subquery does not return a unique value, then Oracle Database raises arun-time error. Use the DISTINCT keyword in the subquery if you arenot sure the query will return unique values.
--仅在XML 中使用,如:
SQL> SELECT *
2 FROM pivot_data
3 PIVOT XML
4 (SUM(sal) AS salaries FOR deptno IN (SELECTdeptno FROM dept));
(4)ANY
The ANY keywordis used only in conjunction with the XML keyword.The ANY keyword acts as a wildcard and is similar in effectto subquery. The output is not the same cross-tabular format returned bynon-XML pivot queries. Instead of multiple columns specified inthe pivot_in_clause, the ANY keyword produces a single XMLstring column. The XML string for each row holds aggregated data correspondingto the implicit GROUP BY value of that row. However, in contrastto the behavior when you specify subquery, the ANY wildcardproduces an XML string for each output row that includes only the pivot valuesfound in the input data corresponding to that row.
--ANY 仅在XML 中使用。如:
SQL> SELECT job
2 , deptno_xml AS alias_for_deptno_xml
3 FROM pivot_data
4 PIVOT XML
5 (SUM(sal) AS salaries FOR deptno IN (ANY));
1.2 unpivot 语法

具体语法:
SELECT ...
FROM ...
UNPIVOT [INCLUDE|EXCLUDE NULLS]
(unpivot_clause
unpivot_for_clause
unpivot_in_clause )
WHERE ...
The unpivot_clause rotatescolumns into rows.
(1)The INCLUDE | EXCLUDE NULLS clausegives you the option of including or excluding null-valued rows. INCLUDE NULLS causesthe unpivot operation to include null-valued rows; EXCLUDE NULLS eliminatesnull-values rows from the return set. If you omit this clause, then the unpivotoperation excludes nulls.
--这个选项用来控制unpivot 是否包含null 的记录,默认是不包含nulls的。
(2)unpivot_clause: this clause specifies a name for a column to represent the unpivotedmeasure values.
-- 对应的具体值
(3)Inthe pivot_for_clause, specify a name for eachoutput column that will hold descriptor values, such as quarter or product.
--对应转换后列的名称
(4)Inthe unpivot_in_clause, specify the input datacolumns whose names will become values in the output columns of the pivot_for_clause.These input data columns have names specifying a category value, such as Q1,Q2, Q3, Q4. The optional AS clause lets you map the input data columnnames to the specified literal values in the output columns.
--具体列到行的列名
如:
SQL> SELECT *
2 FROM pivoted_data
3 UNPIVOT (
4 deptsal --<-- unpivot_clause
5 FORsaldesc --<-- unpivot_for_clause
6 IN (d10_sal, d20_sal, d30_sal, d40_sal) --<-- unpivot_in_clause
7 );
JOB SALDESC DEPTSAL
---------- ---------- ----------
CLERK D10_SAL 1430
CLERK D20_SAL 2090
CLERK D30_SAL 1045
SALESMAN D30_SAL 6160
PRESIDENT D10_SAL 5500
MANAGER D10_SAL 2695
MANAGER D20_SAL 3272.5
MANAGER D30_SAL 3135
ANALYST D20_SAL 6600
The unpivotoperation turns a set of value columns into one column. Therefore, the datatypes of all the value columns must be in the same data type group, such asnumeric or character.
--unpivot 是将列转换成行,所以所有列的类型必须一致。
(1)If all thevalue columns are CHAR, then the unpivoted column is CHAR. If anyvalue column is VARCHAR2, then the unpivoted column is VARCHAR2.
(2)If all thevalue columns are NUMBER, then the unpivoted column is NUMBER. If anyvalue column is BINARY_DOUBLE, then the unpivoted column is BINARY_DOUBLE.If no value column is BINARY_DOUBLE but any value column is BINARY_FLOAT,then the unpivoted column is BINARY_FLOAT.
二. 示例
2.1 Pivot 示例: 行转列
2.1.1 测试数据:
SQL> select *from scott.emp;

2.1.2 显示不同部门不同岗位的总薪水:
/* Formatted on 2011/12/10 19:46:00(QP5 v5.185.11230.41888) */
SELECT *
FROM (SELECTdeptno, job, sal FROM scott.emp)
PIVOT (SUM (sal) --<-- pivot_clause
FORdeptno --<-- pivot_for_clause
IN (10, 20, 30, 40) --<-- pivot_in_clause
);

2.1.3 查询所有记录
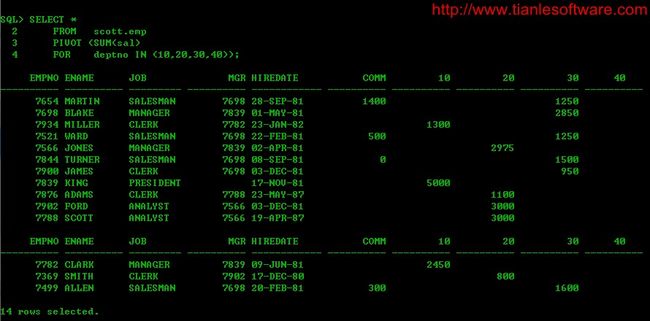
在上面的SQL中,通过子查询限制了返回的结果集,如果不限制,可以直接查询表,那么返回的结果集就会更多:
SELECT *
FROM scott.emp
PIVOT (SUM(sal)
FOR deptno IN (10,20,30,40));
2.1.4 对pivot_clause和 pivot_in_clause 都指定别名:
先创建一个视图,方便我们查询:
SQL> CREATE VIEW pivot_data
2 AS
3 SELECT deptno, job, sal FROMemp;
View created.
SELECT *
FROM scott.pivot_data
PIVOT (SUM(sal) AS salaries
FOR deptno IN (10 AS d10_sal,
20 AS d20_sal,
30 AS d30_sal,
40 AS d40_sal));
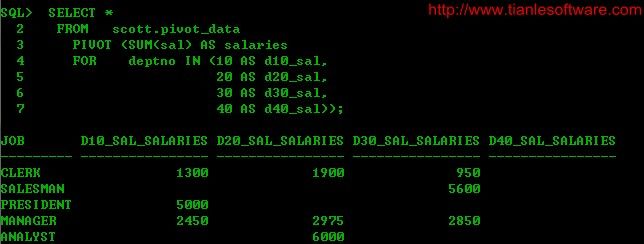
通过查询结果,可以看到最终我们转换后的列名是pivot_in_clause +pivot_clause 的别名。
2.1.5 只指定pivot_clause的别名:
SELECT *
FROM scott.pivot_data
PIVOT (SUM(sal) AS salaries
FOR deptno IN (10, 20, 30, 40));
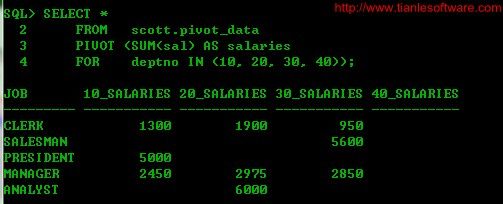
此时最终的别名是最终的pivot_in_clause的列名+pivot_clause 的别名。
2.1.6 只指定pivot_in_clause的别名:
SELECT *
FROM pivot_data
PIVOT (SUM(sal)
FOR deptno IN (10 AS d10_sal,
20 AS d20_sal,
30 AS d30_sal,
40 AS d40_sal));

此时最终的列的名称就是我们pivot_in_clause的别名。
2.1.7 pivot 多列
SELECT *
FROM pivot_data
PIVOT (SUM(sal) AS sum
, COUNT(sal) AS cnt
FOR deptno IN (10 AS d10_sal,
20 AS d20_sal,
30 AS d30_sal,
40 AS d40_sal));
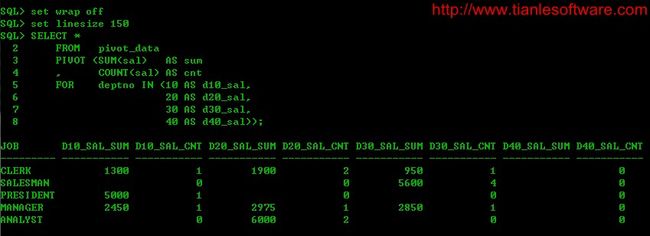
2.1.8 pivot 多列时指定多个字段
SELECT *
FROM pivot_data
PIVOT (SUM(sal) AS sum
, COUNT(sal) AS cnt
FOR (deptno,job) IN ((30, 'SALESMAN') AS d30_sls,
(30, 'MANAGER') AS d30_mgr,
(30, 'CLERK') ASd30_clk));
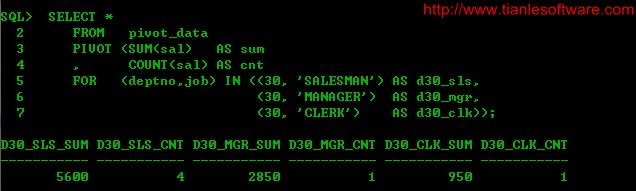
2.1.9 pivot 生成XML,使用ANY
SELECT job,
deptno_xml AS alias_for_deptno_xml
FROM pivot_data
PIVOT XML
(SUM(sal) AS salaries FORdeptno IN (ANY));

2.1.10 生成XML 使用子查询
SELECT *
FROM pivot_data
PIVOT XML
(SUM(sal) AS salaries FORdeptno IN (SELECT deptno FROM dept));

一个小统计:
/* Formatted on 2011/12/10 20:31:27(QP5 v5.185.11230.41888) */ SELECT * FROM (SELECT NVL (wait_class, 'CPU') activity, TRUNC (sample_time, 'MI') time FROM v$active_session_history) PIVOT (COUNT (*) FOR activity IN ('CPU' AS "CPU", 'Concurrency' AS "Concurrency", 'SystemI/O' AS "SystemI/O", 'UserI/O' AS "UserI/O", 'Administrative' AS "Administrative", 'Configuration' AS "Configuration", 'Application' AS "Application", 'Network' AS "Network", 'Commit' AS "Commit", 'Scheduler' AS "Scheduler", 'Cluster' AS "Cluster", 'Queueing' AS "Queueing", 'Other' AS "Other")) WHERE time > SYSDATE - INTERVAL '&last_min' MINUTE ORDER BY time;
2.2 Unpivot 示例: 列转行
2.2.1 创建一个视图,根据这个视图来进行unpivot:
SQL> CREATE VIEW pivoted_data
2 AS
3 SELECT *
4 FROM pivot_data
5 PIVOT (SUM(sal)
6 FOR deptno IN (10 AS d10_sal,
7 20 ASd20_sal,
8 30 ASd30_sal,
9 40 ASd40_sal));
View created.
SQL> select * from pivoted_data;
JOB D10_SAL D20_SAL D30_SAL D40_SAL
--------- ---------- ---------- --------------------
CLERK 1300 1900 950
SALESMAN 5600
PRESIDENT 5000
MANAGER 2450 2975 2850
ANALYST 6000
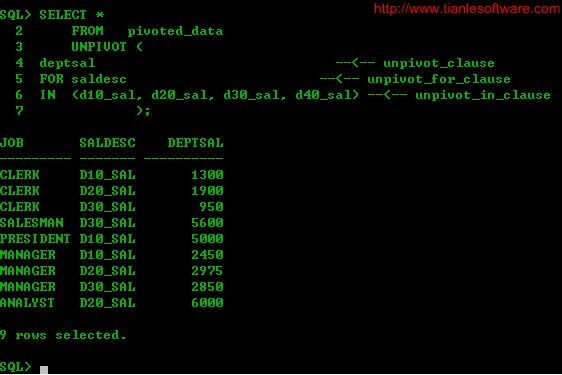
2.2.2 unpivot列转行:
SELECT *
FROM pivoted_data
UNPIVOT (
deptsal --<-- unpivot_clause
FOR saldesc --<-- unpivot_for_clause
IN (d10_sal, d20_sal, d30_sal, d40_sal) --<-- unpivot_in_clause
);
2.2.3 默认是不包含nulls的,我们通过命令处理nulls的结果:
SELECT *
FROM pivoted_data
UNPIVOTINCLUDE NULLS
(deptsal
FOR saldesc IN (d10_sal,
d20_sal,
d30_sal,
d40_sal));

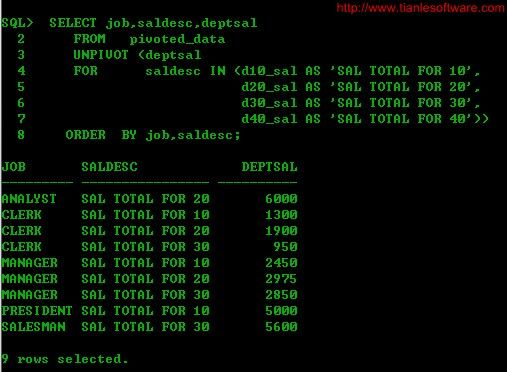
2.2.4 使用别名
SELECT job,saldesc,deptsal
FROM pivoted_data
UNPIVOT (deptsal
FOR saldesc IN (d10_salAS 'SAL TOTAL FOR 10',
d20_sal AS 'SAL TOTAL FOR 20',
d30_sal AS 'SAL TOTAL FOR 30',
d40_sal AS 'SAL TOTAL FOR 40'))
ORDER BY job,saldesc;
更多详细内容参考:
http://www.oracle-developer.net/display.php?id=506
-------------------------------------------------------------------------------------------------------
版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
Blog: http://blog.csdn.net/tianlesoftware
Weibo: http://weibo.com/tianlesoftware
Email: [email protected]
Skype: tianlesoftware
-------加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请----
DBA1 群:62697716(满); DBA2 群:62697977(满) DBA3 群:62697850(满)
DBA 超级群:63306533(满); DBA4 群:83829929(满) DBA5群: 142216823(满)
DBA6 群:158654907(满) DBA7 群:69087192(满)