【深度学习卡住了】技术缺陷根本无法解决,算法领域没有重大突破
我们被卡住了,或者至少我们处于瓶颈期。
谁还记得算法、芯片或数据处理领域上一次整整一年都没有重大、显著的进步是啥时候?几周前我参加Strata圣何塞大会,却没有看到引人注目的新进展,这太不同寻常了。
我之前报道过,我们似乎进入了成熟期,现在我们的主要精力是确保所有强大的新技术很好地协同工作(融合平台),或者从那些大规模的风险投资获得回报。
并非只有我一人注意到了这个问题。几位与会者和参展商的看法与我非常相似。有一天我收到了几位知名研究人员发来的研究纪要,他们一直在评估不同高级分析平台的相对优点,得出的结论是,没有任何不一样的地方值得报告。

我们现在的处境实际上并非很糟糕。在过去的两三年,我们取得的进展都在深度学习和强化学习这个领域。深度学习在处理语音、文本、图像和视频方面为我们带来了出色的功能。加上强化学习,我们在游戏、自动驾驶汽车笔机器人等方面取得了重大进展。
我们现处在基于这些技术的商业爆炸式发展的最初阶段,比如通过聊天机器人大大简化客户互动、新的个人便利应用(比如个人助理和Alexa),以及私家车中的二级自动化(比如自适应巡航控制、避免事故制动和车道维护)。
Tensorflow、Keras及其他深度学习平台比以往更易于使用,而且得益于GPU,比以往更高效。
然而,已知的一系列缺点根本没有解决掉。
-
需要太多标注的训练数据。
-
模型需要花太长的时间或太多的昂贵资源来训练,但仍有可能根本无法训练。
-
尤其是节点和层方面的超参数依然很神秘。自动化或甚至被广泛接受的经验法则仍遥遥无期。
-
迁移学习只意味着从复杂迁移到简单,而不是从一个逻辑系统迁移到另一个逻辑系统。
我确信问题还有更多。我们卡就卡在了解决这些主要的缺点上。
什么让我们止步不前?以深度神经网络(DNN)为例,眼下的传统观点认为,如果我们继续推进、继续投入,那么这些缺点就会被克服。比如说,从上世纪80年代到2000年代,我们知道如何使DNN工作,但根本没有相应的硬件。一旦克服了这个难题,DNN结合新的开源理念就会打破这个新领域的瓶颈。
各种类型的研究都有自己的发展势头,尤其是,一旦你往某个特定的方向投入了大量的时间和财力,会一直往这个方向前进。如果你已花费数年来开发这些技能方面的专业知识,不会轻易改弦易辙。
即使并不完全确信什么是正确的方向,也要改变方向有时候我们需要改变方向,即使我们并不确切知道新的方向是什么。最近领先的加拿大和美国AI研究人员就是这么做的。他们认为自己被误导了,需要实质上重新开始。

去年秋天,杰弗里•辛顿(Geoffrey Hinton)以实际行动诠释了这番感悟,他因上世纪80年代在DNN领域的开创性工作而名声大噪。辛顿现在是多伦多大学名誉教授和谷歌研究员,他表示,现在他对DNN的基础方法:反向传播“极其怀疑”。辛顿观察到人脑不需要所有那些标记的数据就能得出结论,说“我的观点是,扔掉反向传播,从头开始。”
考虑到这一点,下面简单地调查一下新方向,它们有的很靠谱,有的不太现实,但都不是对我们所知道的深度神经网络所作的渐进式改进。
描述的内容有意简短,无疑会引导您进一步阅读以求充分理解。
看起来像DNN、但实则不是的技术有一系列研究力挺辛顿抨击反向传播的观点,认为节点和层的基本结构有用,但连接和计算的方法需要大幅修改。
胶囊网络(CapsNet)
我们先从辛顿自己目前的研究新方向CapsNet开始说起。这与CNN的图像分类有关;简单地说,问题是卷积神经网络(CNN)对于对象的姿态(pose)并不敏感。也就是说,如果识别同一对象,但是位置、大小、方向、变形、速度、反射率、色调和纹理等方面有所不同,就需要为这每一种情况添加训练数据。
在CNN中,这是通过大量增加训练数据及/或增加可以泛化的最大池化层来处理的,但完全丢失了实际信息。

下列描述来自CapsNets方面众多出色的技术描述之一,这个来自Hackernoon。
胶囊是一组嵌套的神经层。所以在普通的神经网络中,你不断增加更多的层。在CapsNet中,你会在一个层里面添加更多层。或者换句话说,将一个神经层嵌套在另一个神经层里面。胶囊内神经元的状态捕获图像内一个实体的上述属性。胶囊输出一个向量,表示实体的存在。向量的方向代表实体的属性。该向量被发送给神经网络中所有可能的父节点(parent)。预测向量则通过自身权重和权重矩阵相乘来计算。无论哪个父节点有最大的标量预测向量乘积,都会加大胶囊键(capsule bond),其余父节点减小胶囊键。这种采用协议路由机制(routing by agreement)的方法优于当前像最大池化这样的机制。
CapsNet极大地减小了所需的训练集,在早期测试中表明:在图像分类方面,性能更胜一筹。
gcForest
今年2月,我们介绍了南京大学新软件技术国家重点实验室的周志华和冯霁的研究成果,他们展示了一种名为gcForest的技术。他们的研究报论文显示,gcForest在文本分类和图像分类方面都经常胜过CNN和RNN。优点相当明显。
-
只需要一小部分训练数据。
-
在普通的台式机CPU设备上就可以运行,无需GPU。
-
训练速度一样快,在许多情况下甚至更快,适合于分布式处理。
-
超参数少得多,在默认设置下表现良好。
-
依赖易于理解的随机森林,而不是完全不透明的深度神经网络。
简而言之,gcForest(多粒度级联森林)是一种决策树集成方法,深度网络的级联结构保留下来,但不透明的边缘和节点神经元被与完全随机的树森林配对的随机森林组取而代之。请了解gcForest的更多信息,请参与我们的这篇原始文章(https://www.datasciencecentral.com/profiles/blogs/off-the-beaten-path-using-deep-forests-to-outperform-cnns-and-rnn)。
Pyro和Edward
Pyro和Edward是两种新的编程语言,将深度学习框架与概率编程融合在一起。Pyro是优步和谷歌的杰作,而Edward脱胎于哥伦比亚大学,得到了美国国防高级研究计划局(DARPA)的资助。结果是,框架让深度学习系统可以测量它们对于预测或决策的信心有多大。
在经典的预测分析中,我们可能使用对数损失作为拟合函数,并惩罚自信但错误的预测(误报),以此处理这个问题。到目前为止,对于深度学习而言没有必然的结果。(So far there’s been no corollary for deep learning.)
比如说,这有望适用于自动驾驶汽车或飞机,好让控制系统在做出重大的决定之前具有某种自信或怀疑的感觉。这当然是你希望优步的自动驾驶车辆在你上车前要知道的。
Pyro和Edward都处于发展的早期阶段。
看起来不像深度网络的方法我经常碰到一些小公司,它们开发的平台其核心使用不同寻常的算法。我发现在大多数情况下,它们一直不愿意提供足够详细的资料,好让我可以为读者描述平台算法的概况。这种保密并不影响它们的效用,但是除非它们提供一些基准数字和一些细节,否则我无法真正告诉你内部发生了什么。
目前,我研究过的最先进的非DNN算法和平台如下:
分层时间记忆(HTM)
分层时间记忆(HTM)使用稀疏分布式表示(SDR)对大脑的神经元进行建模,并执行计算,它在标量预测(商品、能源或股价等方面的未来价值)和异常检测方面的性能比CNN和RNN更胜一筹。
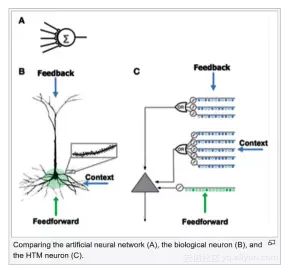
这是以Palm Pilot成名的杰夫•霍金斯(Jeff Hawkins)在其公司Numenta获得的成果。霍金斯致力于搞出一种强大的AI模型,该模型基于针对大脑功能的基础研究,它不是采用DNN中的层和节点那种结构。
HTM的特点是可以非常迅速地发现模式,只需要1000次观测。相比之下,训练CNN或RNN需要观测数十万次、甚至数百万次。
此外,模式识别是无监督的,可以基于不断变化的输入实时识别模式中的变化,并推而广之。因而获得的系统不仅训练起来非常快,还具有自学习和自适应的特点,不会被数据的变化或干扰信息(noise)所困扰。
我们在2月份的文章中介绍了HTM和Numenta,建议不妨阅读一下(https://www.datasciencecentral.com/profiles/blogs/off-the-beaten-path-htm-based-strong-ai-beats-rnns-and-cnns-at-pr)。
值得一提的一些渐进式改进我们力图关注真正改变这个领域的技术,不过渐进式改进方面至少有两个例子值得一提。这些显然仍是典型的CNN和RNN(有着反向传播的要素),但工作起来效果更好。
使用谷歌云AutoML进行网络修剪
谷歌和英伟达的研究人员使用一种名为网络修剪(network pruning)的方法,去除了并不直接影响输出的神经元,让神经网络更小巧、运行起来更高效。最近取得的这一进步缘于谷歌新的AutoML平台在性能上有了重大改进。
Transformer
Transformer是一种新颖的方法,最初在CNN、RNN和LTSM擅长的领域:语言处理(比如语言到语言的翻译)中很有用。去年夏天谷歌Brain和多伦多大学的研究人员发布了Transformer,它已在包括这项英语/德语翻译测试在内的众多测试中表明准确性有了显著提高。
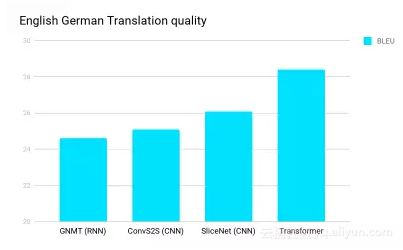
RNN具有顺序处理的特性,因而更难充分发挥GPU等现代快速计算设备的性能,这类设备擅长并行处理而不是顺序处理。CNN的顺序处理特性比RNN弱得多,但在CNN架构中,组合来自输入远端部分的信息所需要的步骤数量仍随距离加大而增多。
准确性方面的突破来自开发出“自注意力功能”(self-attention function),该功能将步骤显著简化为数量不多且恒定的步骤。在每个步骤,它都会运用自注意力机制,直接对句子中所有单词之间的关系建立模型,不管它们各自的位置怎样。
请阅读此处的原始研究论文(https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf)。
结束语:也许是时候转变方向了一个不可忽视的事实是,中国正在大力投资于AI;设定的目标是,在几年内超过美国,成为全球AI领导者。
斯蒂夫•莱文(Steve LeVine)是Axios的未来栏目编辑,并在乔治城大学任教。他在撰写的一篇文章中认为,中国可能在迅速跟随,但恐怕永远赶不上。原因在于,美国和加拿大的研究人员可以随时转变方向、从头开始。制度上受导向的中国人永远没法这么做。以下内容来自莱文的那篇文章:
“在中国,那是无法想象的,”西雅图Outreach.io的首席执行官曼尼•梅迪纳(Manny Medina)说。他表示,像Facebook的雅恩•乐坤(Yann LeCun)和多伦多Vector Institute的杰夫•辛顿(Geoff Hinton)这些AI界的明星“不必征得批准。他们可以开始研究,向前推进工作。”
正如风险投资家们所说,也许是时候转变方向了。
原文发布时间为:2018-03-26
本文作者:云头条
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
原文链接:【深度学习卡住了】技术缺陷根本无法解决,算法领域没有重大突破