地址:https://docs.influxdata.com/chronograf/v1.6/introduction/getting-started/
开始使用Chronograf
在本页面
- 入门概述
- 要求
- InfluxDB设置
- Kapacitor设置
- Telegraf设置
- Chronograf设置
入门概述
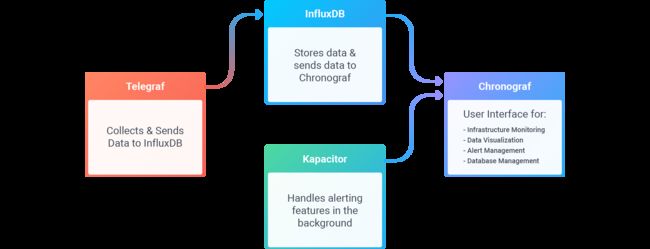
Chronograf是InfluxData的TICK堆栈的用户界面组件。它使您的基础架构的监控和警报易于设置和维护。
接下来的部分将使用尽可能少的配置和代码启动并运行Chronograf。在本文档的最后,您将下载,安装和配置TICK堆栈的所有四个软件包(Telegraf,InfluxDB,Chronograf和Kapacitor),您将全部监控您的基础架构。
要求
本指南介绍如何在Ubuntu 16.04安装上进行设置,适用于大多数Linux版本。在大量操作系统和硬件架构上支持Chronograf和TICK堆栈的其他组件。查看下载页面,获取您选择的二进制文件的链接。
有关安装要求的完整列表,请参阅“ 安装”页面。
InfluxDB安装程序
InfluxDB是时间序列数据库,用作TICK堆栈的数据存储组件。
1.下载并安装InfluxDB
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.4.0_amd64.deb
sudo dpkg -i influxdb_1.4.0_amd64.deb
2.启动InfluxDB
出于本指南的目的,无需编辑InfluxDB的默认配置。只需启动InfluxDB:
sudo systemctl start influxdb
3.验证InfluxDB是否正在运行
使用SHOW DATABASEScurl命令验证InfluxDB是否已启动并正在运行:
curl "http://localhost:8086/query?q=show+databases"
如果InfluxDB正在运行,您应该看到一个包含_internal数据库的对象:
{"results":[{"statement_id":0,"series":[{"name":"databases","columns":["name"],"values":[["_internal"]]}]}]}到现在为止还挺好!您已准备好继续下一部分。请注意,您无需在InfluxDB实例上创建自己的数据库; TICK堆栈的其他组件将为您处理。
Kapacitor设置
Kapacitor是TICK堆栈的数据处理平台。Kapacitor负责在Chronograf中创建和发送警报。
1.下载并安装Kapacitor
wget https://dl.influxdata.com/kapacitor/releases/kapacitor_1.4.0_amd64.deb
sudo dpkg -i kapacitor_1.4.0_amd64.deb
2.启动Kapacitor
sudo systemctl start kapacitor
3.验证Kapacitor是否正在运行
检查taskKapacitor列表:
kapacitor list tasks
如果Kapacitor启动并运行,您应该看到一个空的任务列表:
ID Type Status Executing Databases and Retention Policies
如果出现问题,您将看到错误消息:
Get http://localhost:9092/kapacitor/v1/tasks?dot-view=attributes&fields=type&fields=status&fields=executing&fields=dbrps&limit=100&offset=0&pattern=&replay-id=&script-format=formatted: dial tcp [::1]:9092: getsockopt: connection refused
Telegraf设置
Telegraf是TICK堆栈中的度量收集代理。出于本指南的目的,我们设置Telegraf以收集计算机上的系统统计数据,并将这些指标写入现有的InfluxDB实例。
在生产环境中,Telegraf将安装在您的服务器上,并将输出指向另一台机器上的InfluxDB实例。最终,您将为要监视的每个应用程序配置Telegraf输入插件。
1.下载并安装Telegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.4.3-1_amd64.deb
sudo dpkg -i telegraf_1.4.3-1_amd64.deb
2.启动Telegraf
sudo systemctl start telegraf
3.确认Telegraf正在运行
第2步应创建一个配置文件,其中系统统计信息作为输入插件,InfluxDB作为输出插件。
仔细检查配置文件,/etc/telegraf/telegraf.conf查看相关的输入和输出设置。该OUTPUT PLUGINS部分应具有以下InfluxDB输出设置:
[[outputs.influxdb]]
## The full HTTP or UDP endpoint URL for your InfluxDB instance.
## Multiple urls can be specified as part of the same cluster,
## this means that only ONE of the urls will be written to each interval.
# urls = ["udp://localhost:8089"] # UDP endpoint example
urls = ["http://localhost:8086"] # required
## The target database for metrics (telegraf will create it if not exists).
database = "telegraf" # required
## Retention policy to write to. Empty string writes to the default rp.
retention_policy = ""
## Write consistency (clusters only), can be: "any", "one", "quorum", "all"
write_consistency = "any"
## Write timeout (for the InfluxDB client), formatted as a string.
## If not provided, will default to 5s. 0s means no timeout (not recommended).
timeout = "5s"
# username = "telegraf"
# password = "metricsmetricsmetricsmetrics"
## Set the user agent for HTTP POSTs (can be useful for log differentiation)
# user_agent = "telegraf"
## Set UDP payload size, defaults to InfluxDB UDP Client default (512 bytes)
# udp_payload = 512
接下来,该INPUT PLUGINS部分应具有系统统计信息输入的以下设置:
# Read metrics about cpu usage
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## If true, collect raw CPU time metrics.
collect_cpu_time = false
# Read metrics about disk usage by mount point
[[inputs.disk]]
## By default, telegraf gather stats for all mountpoints.
## Setting mountpoints will restrict the stats to the specified mountpoints.
# mount_points = ["/"]
## Ignore some mountpoints by filesystem type. For example (dev)tmpfs (usually
## present on /run, /var/run, /dev/shm or /dev).
ignore_fs = ["tmpfs", "devtmpfs"]
# Read metrics about disk IO by device
[[inputs.diskio]]
## By default, telegraf will gather stats for all devices including
## disk partitions.
## Setting devices will restrict the stats to the specified devices.
# devices = ["sda", "sdb"]
## Uncomment the following line if you need disk serial numbers.
# skip_serial_number = false
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# no configuration
# Read metrics about memory usage
[[inputs.mem]]
# no configuration
# Get the number of processes and group them by status
[[inputs.processes]]
# no configuration
# Read metrics about swap memory usage
[[inputs.swap]]
# no configuration
# Read metrics about system load & uptime
[[inputs.system]]
# no configuration
Windows主机上的系统统计信息
对于Windows主机, 必须启用
win_perf_countersTelegraf输入插件并将其配置为正确地向InfluxDB报告主机统计信息。
要测试系统统计信息是否正在写入InfluxDB,请运行以下curl命令:
curl "http://localhost:8086/query?q=select+*+from+telegraf..cpu"
如果Telegraf设置正确,您应该会看到很多JSON数据; 如果输出为空则出现问题。
Chronograf设置
现在我们正在使用Telegraf收集数据并使用InfluxDB存储数据,现在是时候安装Chronograf来开始查看和监控数据了。
1.下载并安装Chronograf
wget https://dl.influxdata.com/chronograf/releases/chronograf_1.4.0.0_amd64.deb
sudo dpkg -i chronograf_1.4.0.0_amd64.deb
2.启动Chronograf
sudo systemctl start chronograf
3.连接到Chronograf
假设一切正常,我们应该能够连接并配置Chronograf。将Web浏览器指向http://localhost:8888(localhost如果您没有运行,则替换为服务器的IP localhost)。
你应该看到一个欢迎页面:
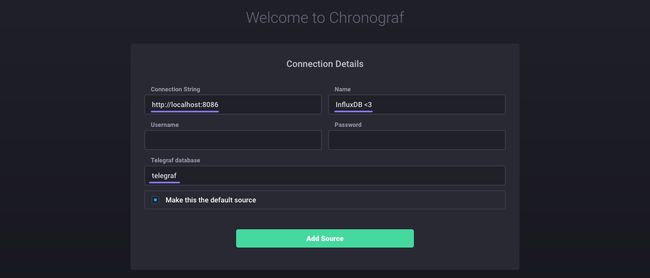
接下来的步骤将Chronograf连接到您的InfluxDB实例。对于Connection String,输入运行InfluxDB的机器的主机名或IP,并确保包含InfluxDB的默认端口:8086。接下来,命名连接字符串; 这可以是你想要的任何东西。无需编辑最后三个输入; 禁用授权在InfluxDB的默认配置,Username并且Password可以保持空白,Telegraf的默认数据库名称为telegraf。
点击Connect New Source进入该HOST LIST页面:
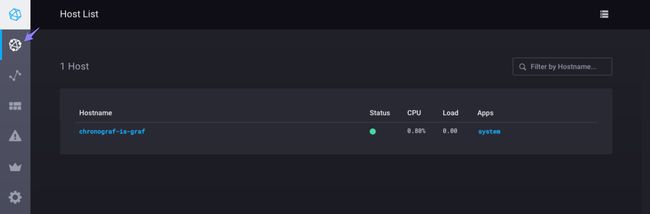
您应该在页面上看到计算机的主机名以及有关其CPU使用率和负载的信息。假设您已配置Telegraf的系统统计信息输入插件,system则应显示在Apps列中。继续并单击主机名以查看有关主机的一系列系统级图表:

4.将Chronograf连接到Kapacitor
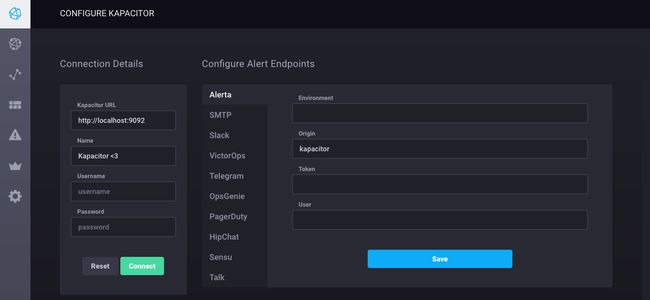
安装过程的最后一步是将Chronograf连接到Kapacitor。导航到配置页面(侧边栏的最后一个项目),然后单击Add Config在Active Kapacitor列。

对于Kapacitor URL,输入运行Kapacitor的计算机的主机名或IP,并确保包含Kapacitor的默认端口:9092。接下来,命名连接字符串; 这可以是你想要的任何东西。由于在Kapacitor的默认配置中禁用了授权,因此无需为Username和Password输入输入任何信息。最后,点击Connect。
当Kapacitor成功连接时,Chronograf会自动打开该Configure Alert Endpoints部分。Kapacitor支持多个警报端点/事件处理程序。有关详细信息,请参阅“ 配置Chronograf警报端点”指南。
而已!您已成功下载,安装和配置TICK堆栈的每个组件。接下来,查看我们的指南,熟悉Chronograf,看看你可以用它做的一切!