- 2021年12月19日,春蕾教育集团团建活动感受——黄晓丹
黄错错加油
感受:1.从陌生到熟悉的过程。游戏环节让我们在轻松的氛围中得到了锻炼,也增长了不少知识。2.游戏过程中,我们贡献的是个人力量,展现的是团队的力量。它磨合的往往不止是工作的熟悉,更是观念上契合度的贴近。3.这和工作是一样的道理。在各自的岗位上,每个人摆正自己的位置、各司其职充分发挥才能,并团结一致劲往一处使,才能实现最大的成功。新知:1.团队精神需要不断地创新。过去,人们把创新看作是冒风险,现在人们
- Pyecharts数据可视化大屏:打造沉浸式数据分析体验
我的运维人生
信息可视化数据分析数据挖掘运维开发技术共享
Pyecharts数据可视化大屏:打造沉浸式数据分析体验在当今这个数据驱动的时代,如何将海量数据以直观、生动的方式展现出来,成为了数据分析师和企业决策者关注的焦点。Pyecharts,作为一款基于Python的开源数据可视化库,凭借其丰富的图表类型、灵活的配置选项以及高度的定制化能力,成为了构建数据可视化大屏的理想选择。本文将深入探讨如何利用Pyecharts打造数据可视化大屏,并通过实际代码案例
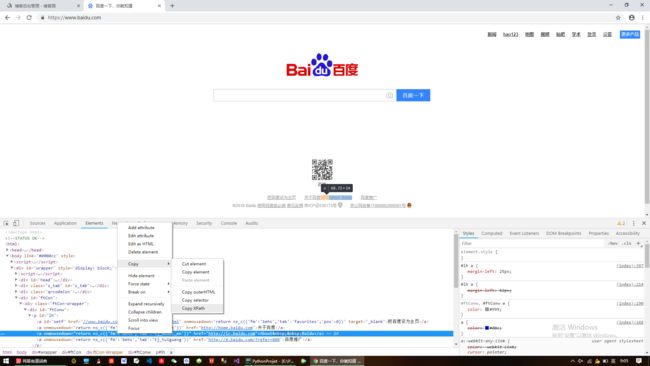
- Python教程:一文了解使用Python处理XPath
旦莫
Python进阶python开发语言
目录1.环境准备1.1安装lxml1.2验证安装2.XPath基础2.1什么是XPath?2.2XPath语法2.3示例XML文档3.使用lxml解析XML3.1解析XML文档3.2查看解析结果4.XPath查询4.1基本路径查询4.2使用属性查询4.3查询多个节点5.XPath的高级用法5.1使用逻辑运算符5.2使用函数6.实战案例6.1从网页抓取数据6.1.1安装Requests库6.1.2代
- Google earth studio 简介
陟彼高冈yu
旅游
GoogleEarthStudio是一个基于Web的动画工具,专为创作使用GoogleEarth数据的动画和视频而设计。它利用了GoogleEarth强大的三维地图和卫星影像数据库,使用户能够轻松地创建逼真的地球动画、航拍视频和动态地图可视化。网址为https://www.google.com/earth/studio/。GoogleEarthStudio是一个基于Web的动画工具,专为创作使用G
- 从鸡肉高汤到记忆的魔法再到有效提示的艺术
步子哥
人工智能
还记得小时候那些天马行空的白日梦吗?也许只要按下键盘上的某个神奇组合,电脑就会发出滴滴的声响,一个隐藏的世界突然在你眼前展开,让你获得超凡的能力,摆脱平凡的生活。这听起来像是玩过太多电子游戏的幻想,但实际上,间隔重复系统给人的感觉惊人地相似。在最佳状态下,这些系统就像魔法一样神奇。本文将以一个看似平凡的鸡肉高汤食谱为例,深入浅出地探讨如何编写有效的间隔重复提示,让你像掌握烹饪技巧一样轻松地掌握记忆
- 如果做到轻松在股市赚钱?只要坚持这三个原则。
履霜之人
大A股里向来就有七亏二平一赚的说法,能赚钱的都是少数人。否则股市就成了慈善机构,人人都有钱赚,谁还要上班?所以说亏钱是正常的,或者说是应该的。那么那些赚钱的人又是如何做到的呢?普通人能不能找到捷径去分一杯羹呢?方法是有的,但要做到需要你有极高的自律。第一,控制仓位,散户最大的问题是追涨杀跌,只要涨起来,就把钱往股票上砸,然后被套,隔天跌的受不了,又一刀切,全部割肉。来来回回间,遍体鳞伤。所以散户首
- 探索OpenAI和LangChain的适配器集成:轻松切换模型提供商
nseejrukjhad
langchaineasyui前端python
#探索OpenAI和LangChain的适配器集成:轻松切换模型提供商##引言在人工智能和自然语言处理的世界中,OpenAI的模型提供了强大的能力。然而,随着技术的发展,许多人开始探索其他模型以满足特定需求。LangChain作为一个强大的工具,集成了多种模型提供商,通过提供适配器,简化了不同模型之间的转换。本篇文章将介绍如何使用LangChain的适配器与OpenAI集成,以便轻松切换模型提供商
- 利用Requests Toolkit轻松完成HTTP请求
nseejrukjhad
http网络协议网络python
RequestsToolkit的力量:轻松构建HTTP请求Agent在现代软件开发中,API请求是与外部服务交互的核心。RequestsToolkit提供了一种便捷的方式,帮助开发者构建自动化的HTTP请求Agent。本文旨在详细介绍RequestsToolkit的设置、使用和潜在挑战。引言RequestsToolkit是一个强大的工具包,可用于构建执行HTTP请求的智能代理。这对于想要自动化与外
- 利用LangChain的StackExchange组件实现智能问答系统
nseejrukjhad
langchainmicrosoft数据库python
利用LangChain的StackExchange组件实现智能问答系统引言在当今的软件开发世界中,StackOverflow已经成为程序员解决问题的首选平台之一。而LangChain作为一个强大的AI应用开发框架,提供了StackExchange组件,使我们能够轻松地将StackOverflow的海量知识库集成到我们的应用中。本文将详细介绍如何使用LangChain的StackExchange组件
- GitHub上克隆项目
bigbig猩猩
github
从GitHub上克隆项目是一个简单且直接的过程,它允许你将远程仓库中的项目复制到你的本地计算机上,以便进行进一步的开发、测试或学习。以下是一个详细的步骤指南,帮助你从GitHub上克隆项目。一、准备工作1.安装Git在克隆GitHub项目之前,你需要在你的计算机上安装Git工具。Git是一个开源的分布式版本控制系统,用于跟踪和管理代码变更。你可以从Git的官方网站(https://git-scm.
- Python爬虫解析工具之xpath使用详解
eqa11
python爬虫开发语言
文章目录Python爬虫解析工具之xpath使用详解一、引言二、环境准备1、插件安装2、依赖库安装三、xpath语法详解1、路径表达式2、通配符3、谓语4、常用函数四、xpath在Python代码中的使用1、文档树的创建2、使用xpath表达式3、获取元素内容和属性五、总结Python爬虫解析工具之xpath使用详解一、引言在Python爬虫开发中,数据提取是一个至关重要的环节。xpath作为一门
- 01-Git初识
Meereen
Gitgit
01-Git初识概念:一个免费开源,分布式的代码版本控制系统,帮助开发团队维护代码作用:记录代码内容。切换代码版本,多人开发时高效合并代码内容如何学:个人本机使用:Git基础命令和概念多人共享使用:团队开发同一个项目的代码版本管理Git配置用户信息配置:用户名和邮箱,应用在每次提交代码版本时表明自己的身份命令:查看git版本号git-v配置用户名gitconfig--globaluser.name
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 提高教师信息素养,提高道德与法治课教学效益
长白159宋彦红
提高教师信息素养,提高道德与法治课教学效益随着经济和社会的发展,信息技术已经运用到课堂教学中,为课堂教学展示了一个崭新的天地。的确,信息技术形象、生动、直观性强,能够将课本中的一些抽想的概念直接展示在学生面前,从而调动学生的眼、耳、脑,让他们兴奋起来,变被动学习为主动学习,充分发挥教师的教育引导作用,创造一个可以使学生积极参与的场景。在制作、使用信息技术的实践过程中,本文拟就教师提升信息素养的必要
- 一文掌握python常用的list(列表)操作
程序员neil
pythonpython开发语言
目录一、创建列表1.直接创建列表:2.使用list()构造器3.使用列表推导式4.创建空列表二、访问列表元素1.列表支持通过索引访问元素,索引从0开始:2.还可以使用切片操作访问列表的一部分:三、修改列表元素四、添加元素1.append():在末尾添加元素2.insert():在指定位置插入元素五、删除元素1.del:删除指定位置的元素2.remove():删除指定值的第一个匹配项3.pop():
- 过了放弃的半生,很想偿偿坚持后的结果
乐安河
这一阵子又迷茫了,找不到生活的目标,失去了坚持的意义,放弃太简单了,不想了,不看了,不写了,不做了,就行了。放弃的剎那,仿佛全身获得了解救,不再跟自己较劲,真轻松,真爽。短暂的惬意过后,是被抛弃的痛苦,是本该可以的不甘,是悔不当初的懊恼。我的前半生就是一次次的放弃过后的自我放逐。不愿努力,只好说平凡可贵,我们都是普通人,为什么非要整出仙人。不愿意轰轰烈烈,只想要现世安稳。只是,到最后发现,安稳变得
- 开启你的思维成长之路
希思维
图片发自App很多时候我们都羡慕别人家的孩子思维敏捷,记忆超强,脑回路清晰等,认为那些都是天生的能力,而自己要达到那样的境界几乎不可能,殊不知每个人都有一个强大的小宇宙,就看你是否找到了开启你思维小宇宙的方法。我们每个人的大脑都具有无限潜能,大部分人只开发出10-20%,还有很多潜力深埋于冰山底,而如何找到自己思维的动力呢?首先就是要了解我们神奇的大脑,从大脑神经元素,到神经回路的形成,知晓大脑思
- Java面试题精选:消息队列(二)
芒果不是芒
Java面试题精选javakafka
一、Kafka的特性1.消息持久化:消息存储在磁盘,所以消息不会丢失2.高吞吐量:可以轻松实现单机百万级别的并发3.扩展性:扩展性强,还是动态扩展4.多客户端支持:支持多种语言(Java、C、C++、GO、)5.KafkaStreams(一个天生的流处理):在双十一或者销售大屏就会用到这种流处理。使用KafkaStreams可以快速的把销售额统计出来6.安全机制:Kafka进行生产或者消费的时候会
- 2023.5.10 周三 早7:38
努力逆流而上
榜样的力量前一段时间追一个《一生一世》的电视剧,脑残剧,但居中的周生辰,稳重。润玉一般的性格,坚持着10年如一日的自律习惯,养成的性格也是这样温文尔雅,虽然是剧中塑造,但我感觉现实中一定是有的,让我觉得人生就是这样的修行,自律不是强迫自己,是形成的习惯,坚持的习惯!结果五一回家,太无聊,看了韩剧的《继承者》让孩子也跟着一起看手机,昨天跑了步,但发现没有很快乐,不知道起的太晚还是怎么着,7点的大街上
- 【347】脊梁式普通教师——《教育的100种可能(上)》(5)
向日葵_1f86
用心是一节课,敷衍也是一节课,但是我们的尽心与否,很可能会改变一个孩子的人生轨迹。——李镇西学生张春银李镇西老师说:张春银不是“全国劳模”“特级教师”,但他真正代表了绝大多数的平凡教师、普通劳动者,这就是我要写张春银的原因。张春银老师是乡村教育的默默守望者,用他的爱守护着每一个孩子,上好每一堂课,用自己的青春去呵护孩子们的快乐成长。因为教育行走,我们也听到了更多乡村教师的故事,他们也都是用自己的爱
- 看不懂的秋天
騎黑馬的東北漢
金风玉露,秋高气爽,咋一看欲冷还暖,初秋不知何时悄悄来到了我们身边,遍野金涂,层林墨染。虽然少了几分绚丽的花飞蝶舞,却多了一抹简约的秋水长天,艳阳当空高照,满月亲人团圆,每个人情不自禁走进了秋,不带一丝残花落叶的凄凉,只多了一种喜悦期盼的情愫。图片发自App每个人都有自己喜欢的季节,在自己的内心里也会有着对季节的诠释。然而我却看不懂,说实话我不太喜欢秋,即使秋天是收获的季节。图片发自App连续几年
- 趁吾身未老
逍遥书生111
趁吾身未老池非2020年,一场突如其来的新冠脑炎疫情,打破了原有的状态。工作与生活的轨迹发生了不确定的变化。01因为隔离防疫,正常的教学不能进行,线上网课成为教学的新形式,年过五十的我面对新的教学形式有些应不暇。只得退而求次,不再负责高考班级的课程。这样,就不用上网课做直播了。感觉很轻松很闲的同时,也感觉到了英雄迟暮。不得不承认,老了。该交班了。因为不能出门,整天呆在家里,一开始还很兴奋,终于可以
- Kafka是如何保证数据的安全性、可靠性和分区的
喜欢猪猪
kafka分布式
Kafka作为一个高性能、可扩展的分布式流处理平台,通过多种机制来确保数据的安全性、可靠性和分区的有效管理。以下是关于Kafka如何保证数据安全性、可靠性和分区的详细解析:一、数据安全性SSL/TLS加密:Kafka支持SSL/TLS协议,通过配置SSL证书和密钥来加密数据传输,确保数据在传输过程中不会被窃取或篡改。这一机制有效防止了中间人攻击,保护了数据的安全性。SASL认证:Kafka支持多种
- Java爬虫框架(一)--架构设计
狼图腾-狼之传说
java框架java任务html解析器存储电子商务
一、架构图那里搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容数据库:存储商品信息索引:商品的全文搜索索引Task队列:需要爬取的网页列表Visited表:已经爬取过的网页列表爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。二、爬虫1.流程1)Scheduler启动爬虫器,TaskMast
- Java:爬虫框架
dingcho
Javajava爬虫
一、ApacheNutch2【参考地址】Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎.为了完成这一宏伟的目标,Nutch必须能够做到:每个月取几十亿网页为这些网页维护一个索引对索引文件进行每秒上千次的搜索提供高质量的搜索结果简单来说Nutch支持分
- mac 备份android 手机通讯录导入iphone,iphone如何导出通讯录(轻松教你iPhone备份通讯录的方法)...
weixin_39762838
mac备份android手机通讯录导入iphone
在日新月异的手机更替中,换手机已经成为一个非常稀松平常的事情,但将旧手机上面的通讯录导入到新手机还是让不少小伙伴为难,本篇将给大家详细讲解这方面的知识:“苹果手机通讯录怎么导入到新手机”及“安卓手机通讯录导入到新手机”的方法。一、苹果手机通讯录导入到新手机常用方法(SIM卡导入)在苹果手机主频幕上找到“设置”,单击进入设置菜单,下拉菜单列表,点击“邮件、通讯录、日历”,然后找到“导入SIM卡通讯录
- ARMv8 Debug
__pop_
ARMv8ARM64架构linux运维
内容来自DEN0024A_v8_architecture_PG.pdf本质ARMv8Debug是什么历史在ARMv4开始被引入,并已发展成一系列广泛的调试(debug1)和跟踪(trace)功能ARMv6和ARMv7-a新增了自托管调试(debug2)和性能评测(trace-enhance)ARMv8处理器提供硬件功能侵入式:调试工具能够对核心活动提供显著级别的控制非侵入式:以非侵入性方式收集有关
- 【ARM Cortex-M 系列 2.3 -- Cortex-M7 Debug event 详细介绍】
主公讲 ARM
#ARM系列arm开发debugevent
请阅读【嵌入式开发学习必备专栏】文章目录Cortex-M7DebugeventDebugeventsCortex-M7Debugevent在ARMCortex-M7架构中,调试事件(DebugEvent)是由于调试原因而触发的事件。一个调试事件会导致以下几种情况之一发生:进入调试状态:如果启用了停滞调试(HaltingDebug),一个调试事件会使处理器在调试状态下停滞。通过将DHCSR.C_DE
- C++ lambda闭包消除类成员变量
barbyQAQ
c++c++java算法
原文链接:https://blog.csdn.net/qq_51470638/article/details/142151502一、背景在面向对象编程时,常常要添加类成员变量。然而类成员一旦多了之后,也会带来干扰。拿到一个类,一看成员变量好几十个,就问你怕不怕?二、解决思路可以借助函数式编程思想,来消除一些不必要的类成员变量。三、实例举个例子:classClassA{public:...intfu
- 【Bugs】Python:“ModuleNotFoundError: No module named ‘XXX‘”
系'辞
工具箱pythonbuganaconda
问题描述Python使用库的前提是必须已安装了相应的库,往往利用“命令行指令”实现安装,一般安装解法类似。但,还是具有延伸问题,本博客对此作记录。【1】Nomodulenamed‘seaborn’(1.1):情况1:为Anaconda安装【图1-2】.定位Anaconda路径【图3】.Anaconda路径加入Path>&
- JVM StackMapTable 属性的作用及理解
lijingyao8206
jvm字节码Class文件StackMapTable
在Java 6版本之后JVM引入了栈图(Stack Map Table)概念。为了提高验证过程的效率,在字节码规范中添加了Stack Map Table属性,以下简称栈图,其方法的code属性中存储了局部变量和操作数的类型验证以及字节码的偏移量。也就是一个method需要且仅对应一个Stack Map Table。在Java 7版
- 回调函数调用方法
百合不是茶
java
最近在看大神写的代码时,.发现其中使用了很多的回调 ,以前只是在学习的时候经常用到 ,现在写个笔记 记录一下
代码很简单:
MainDemo :调用方法 得到方法的返回结果
- [时间机器]制造时间机器需要一些材料
comsci
制造
根据我的计算和推测,要完全实现制造一台时间机器,需要某些我们这个世界不存在的物质
和材料...
甚至可以这样说,这种材料和物质,我们在反应堆中也无法获得......
- 开口埋怨不如闭口做事
邓集海
邓集海 做人 做事 工作
“开口埋怨,不如闭口做事。”不是名人名言,而是一个普通父亲对儿子的训导。但是,因为这句训导,这位普通父亲却造就了一个名人儿子。这位普通父亲造就的名人儿子,叫张明正。 张明正出身贫寒,读书时成绩差,常挨老师批评。高中毕业,张明正连普通大学的分数线都没上。高考成绩出来后,平时开口怨这怨那的张明正,不从自身找原因,而是不停地埋怨自己家庭条件不好、埋怨父母没有给他创造良好的学习环境。
- jQuery插件开发全解析,类级别与对象级别开发
IT独行者
jquery开发插件 函数
jQuery插件的开发包括两种: 一种是类级别的插件开发,即给
jQuery添加新的全局函数,相当于给
jQuery类本身添加方法。
jQuery的全局函数就是属于
jQuery命名空间的函数,另一种是对象级别的插件开发,即给
jQuery对象添加方法。下面就两种函数的开发做详细的说明。
1
、类级别的插件开发 类级别的插件开发最直接的理解就是给jQuer
- Rome解析Rss
413277409
Rome解析Rss
import java.net.URL;
import java.util.List;
import org.junit.Test;
import com.sun.syndication.feed.synd.SyndCategory;
import com.sun.syndication.feed.synd.S
- RSA加密解密
无量
加密解密rsa
RSA加密解密代码
代码有待整理
package com.tongbanjie.commons.util;
import java.security.Key;
import java.security.KeyFactory;
import java.security.KeyPair;
import java.security.KeyPairGenerat
- linux 软件安装遇到的问题
aichenglong
linux遇到的问题ftp
1 ftp配置中遇到的问题
500 OOPS: cannot change directory
出现该问题的原因:是SELinux安装机制的问题.只要disable SELinux就可以了
修改方法:1 修改/etc/selinux/config 中SELINUX=disabled
2 source /etc
- 面试心得
alafqq
面试
最近面试了好几家公司。记录下;
支付宝,面试我的人胖胖的,看着人挺好的;博彦外包的职位,面试失败;
阿里金融,面试官人也挺和善,只不过我让他吐血了。。。
由于印象比较深,记录下;
1,自我介绍
2,说下八种基本类型;(算上string。楼主才答了3种,哈哈,string其实不是基本类型,是引用类型)
3,什么是包装类,包装类的优点;
4,平时看过什么书?NND,什么书都没看过。。照样
- java的多态性探讨
百合不是茶
java
java的多态性是指main方法在调用属性的时候类可以对这一属性做出反应的情况
//package 1;
class A{
public void test(){
System.out.println("A");
}
}
class D extends A{
public void test(){
S
- 网络编程基础篇之JavaScript-学习笔记
bijian1013
JavaScript
1.documentWrite
<html>
<head>
<script language="JavaScript">
document.write("这是电脑网络学校");
document.close();
</script>
</h
- 探索JUnit4扩展:深入Rule
bijian1013
JUnitRule单元测试
本文将进一步探究Rule的应用,展示如何使用Rule来替代@BeforeClass,@AfterClass,@Before和@After的功能。
在上一篇中提到,可以使用Rule替代现有的大部分Runner扩展,而且也不提倡对Runner中的withBefores(),withAfte
- [CSS]CSS浮动十五条规则
bit1129
css
这些浮动规则,主要是参考CSS权威指南关于浮动规则的总结,然后添加一些简单的例子以验证和理解这些规则。
1. 所有的页面元素都可以浮动 2. 一个元素浮动后,会成为块级元素,比如<span>,a, strong等都会变成块级元素 3.一个元素左浮动,会向最近的块级父元素的左上角移动,直到浮动元素的左外边界碰到块级父元素的左内边界;如果这个块级父元素已经有浮动元素停靠了
- 【Kafka六】Kafka Producer和Consumer多Broker、多Partition场景
bit1129
partition
0.Kafka服务器配置
3个broker
1个topic,6个partition,副本因子是2
2个consumer,每个consumer三个线程并发读取
1. Producer
package kafka.examples.multibrokers.producers;
import java.util.Properties;
import java.util.
- zabbix_agentd.conf配置文件详解
ronin47
zabbix 配置文件
Aliaskey的别名,例如 Alias=ttlsa.userid:vfs.file.regexp[/etc/passwd,^ttlsa:.:([0-9]+),,,,\1], 或者ttlsa的用户ID。你可以使用key:vfs.file.regexp[/etc/passwd,^ttlsa:.: ([0-9]+),,,,\1],也可以使用ttlsa.userid。备注: 别名不能重复,但是可以有多个
- java--19.用矩阵求Fibonacci数列的第N项
bylijinnan
fibonacci
参考了网上的思路,写了个Java版的:
public class Fibonacci {
final static int[] A={1,1,1,0};
public static void main(String[] args) {
int n=7;
for(int i=0;i<=n;i++){
int f=fibonac
- Netty源码学习-LengthFieldBasedFrameDecoder
bylijinnan
javanetty
先看看LengthFieldBasedFrameDecoder的官方API
http://docs.jboss.org/netty/3.1/api/org/jboss/netty/handler/codec/frame/LengthFieldBasedFrameDecoder.html
API举例说明了LengthFieldBasedFrameDecoder的解析机制,如下:
实
- AES加密解密
chicony
加密解密
AES加解密算法,使用Base64做转码以及辅助加密:
package com.wintv.common;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import sun.misc.BASE64Decod
- 文件编码格式转换
ctrain
编码格式
package com.test;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
- mysql 在linux客户端插入数据中文乱码
daizj
mysql中文乱码
1、查看系统客户端,数据库,连接层的编码
查看方法: http://daizj.iteye.com/blog/2174993
进入mysql,通过如下命令查看数据库编码方式: mysql> show variables like 'character_set_%'; +--------------------------+------
- 好代码是廉价的代码
dcj3sjt126com
程序员读书
长久以来我一直主张:好代码是廉价的代码。
当我跟做开发的同事说出这话时,他们的第一反应是一种惊愕,然后是将近一个星期的嘲笑,把它当作一个笑话来讲。 当他们走近看我的表情、知道我是认真的时,才收敛一点。
当最初的惊愕消退后,他们会用一些这样的话来反驳: “好代码不廉价,好代码是采用经过数十年计算机科学研究和积累得出的最佳实践设计模式和方法论建立起来的精心制作的程序代码。”
我只
- Android网络请求库——android-async-http
dcj3sjt126com
android
在iOS开发中有大名鼎鼎的ASIHttpRequest库,用来处理网络请求操作,今天要介绍的是一个在Android上同样强大的网络请求库android-async-http,目前非常火的应用Instagram和Pinterest的Android版就是用的这个网络请求库。这个网络请求库是基于Apache HttpClient库之上的一个异步网络请求处理库,网络处理均基于Android的非UI线程,通
- ORACLE 复习笔记之SQL语句的优化
eksliang
SQL优化Oracle sql语句优化SQL语句的优化
转载请出自出处:http://eksliang.iteye.com/blog/2097999
SQL语句的优化总结如下
sql语句的优化可以按照如下六个步骤进行:
合理使用索引
避免或者简化排序
消除对大表的扫描
避免复杂的通配符匹配
调整子查询的性能
EXISTS和IN运算符
下面我就按照上面这六个步骤分别进行总结:
- 浅析:Android 嵌套滑动机制(NestedScrolling)
gg163
android移动开发滑动机制嵌套
谷歌在发布安卓 Lollipop版本之后,为了更好的用户体验,Google为Android的滑动机制提供了NestedScrolling特性
NestedScrolling的特性可以体现在哪里呢?<!--[if !supportLineBreakNewLine]--><!--[endif]-->
比如你使用了Toolbar,下面一个ScrollView,向上滚
- 使用hovertree菜单作为后台导航
hvt
JavaScriptjquery.nethovertreeasp.net
hovertree是一个jquery菜单插件,官方网址:http://keleyi.com/jq/hovertree/ ,可以登录该网址体验效果。
0.1.3版本:http://keleyi.com/jq/hovertree/demo/demo.0.1.3.htm
hovertree插件包含文件:
http://keleyi.com/jq/hovertree/css
- SVG 教程 (二)矩形
天梯梦
svg
SVG <rect> SVG Shapes
SVG有一些预定义的形状元素,可被开发者使用和操作:
矩形 <rect>
圆形 <circle>
椭圆 <ellipse>
线 <line>
折线 <polyline>
多边形 <polygon>
路径 <path>
- 一个简单的队列
luyulong
java数据结构队列
public class MyQueue {
private long[] arr;
private int front;
private int end;
// 有效数据的大小
private int elements;
public MyQueue() {
arr = new long[10];
elements = 0;
front
- 基础数据结构和算法九:Binary Search Tree
sunwinner
Algorithm
A binary search tree (BST) is a binary tree where each node has a Comparable key (and an associated value) and satisfies the restriction that the key in any node is larger than the keys in all
- 项目出现的一些问题和体会
Steven-Walker
DAOWebservlet
第一篇博客不知道要写点什么,就先来点近阶段的感悟吧。
这几天学了servlet和数据库等知识,就参照老方的视频写了一个简单的增删改查的,完成了最简单的一些功能,使用了三层架构。
dao层完成的是对数据库具体的功能实现,service层调用了dao层的实现方法,具体对servlet提供支持。
&
- 高手问答:Java老A带你全面提升Java单兵作战能力!
ITeye管理员
java
本期特邀《Java特种兵》作者:谢宇,CSDN论坛ID: xieyuooo 针对JAVA问题给予大家解答,欢迎网友积极提问,与专家一起讨论!
作者简介:
淘宝网资深Java工程师,CSDN超人气博主,人称“胖哥”。
CSDN博客地址:
http://blog.csdn.net/xieyuooo
作者在进入大学前是一个不折不扣的计算机白痴,曾经被人笑话过不懂鼠标是什么,