2019独角兽企业重金招聘Python工程师标准>>> 
架构图解
架构解读
第一层:数据采集层
第二层:数据缓冲层
第三层:数据转发层
第四层:数据持久化存储层
第五层:数据检索、展示层
部署方案
角色设计
搭建部署
一、安装JDK 1.8
二、调整系统参数
三、elasticsearch集群
1.部署ES yum源
2.配置验证KEY:
3.安装ES server
4.安装head、bigdesk、kopf插件
1.安装head插件
2.安装bigdesk插件
3.安装kopf插件
四、Zookeeper集群
1.安装Zookeeper
2.创建myid
3.启动服务 & 查看状态
五、Kafka集群
1.安装Kfaka
2.修改配置文件
3.配置对应IP解析
4.启动kafka
六、Logstash
1.安装logstash
2.配置logstash
3.启动logstash
4.测试logstash正常运行
4.配置logstash收集nginx日志
七、Filebeat
1.安装filebeat
2.配置filbeat
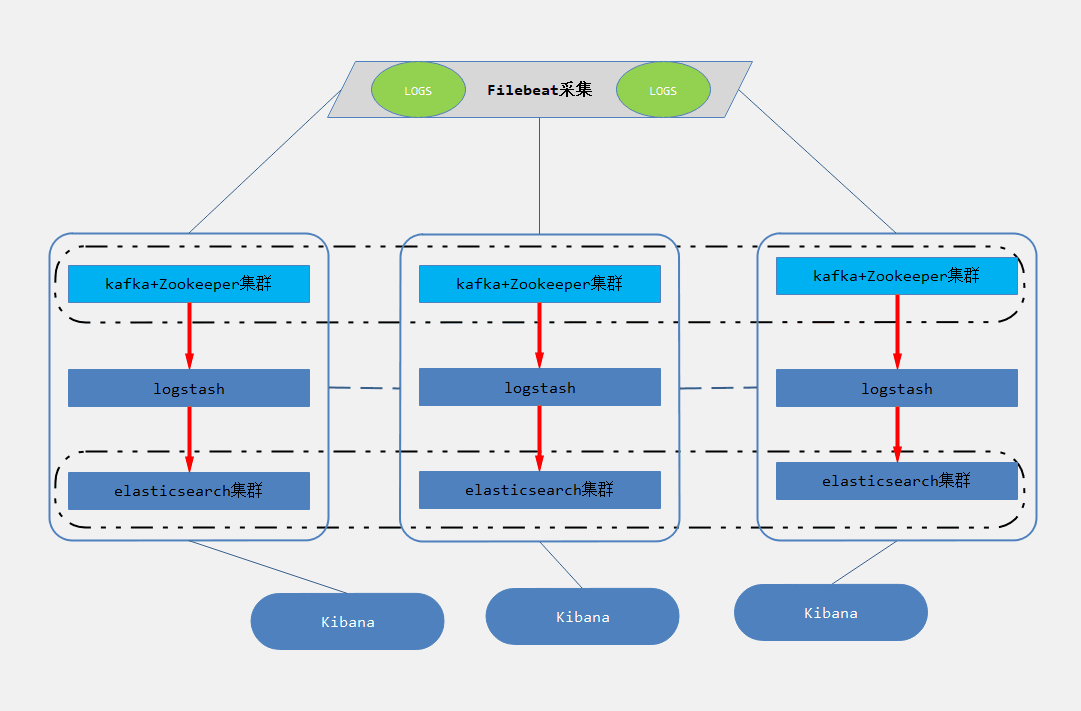
为什么要做日志分析平台,随着业务量的增大,单个日志文件大小达到几个GB,这时候,我们发现用系统自带的工具,cat/grep/awk/tail越来越显得力不从心,除了操作系统日志,还有应用系统日志,分布在各个服务器上,分析工作异常繁琐。所以为了解决现状,接下来我们将构建这个日志分析平台,具体内容如上:
架构解读
第一层:数据采集层
LOGS层:业务应用服务器集群,使用filebeat对应用服务器的日志进行采集。
第二层:数据缓冲层
zookeeper+kafka层:日志采集客户端采集来的数据,转存到kafka+zookeeper集群中,做一个消息队列,让数据有一定的缓冲
第三层:数据转发层
logstash层:这个单独的Logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode。
第四层:数据持久化存储层
ES层:会把收到的数据,写磁盘,建索引库。
第五层:数据检索、展示层
Kibana层: 主要协调ES集群,处理数据检索请求,数据展示。
部署方案
角色设计
| IP | 角色 | 所属集群 |
|---|---|---|
| 10.10.10.151 | 应用服务器+filebeat | 业务系统 |
| 10.10.10.121 | Logstash+Kafka+ZooKeeper | kafka broker集群 |
| 10.10.10.123 | Logstash+Kafka+ZooKeeper | kafka broker集群 |
| 10.10.10.125 | Logstash+Kafka+ZooKeeper | kafka broker集群 |
| 10.10.10.202 | elasticsearch+logstash | es 集群 |
| 10.10.10.200 | elasticsearch+kibana | es 集群 |
搭建部署
为了节约服务器资源,所以把一下角色合并到一台服务器中去。
系统环境:Centos6.5 + JDK
一、安装JDK 1.8
yum install java# 这里直接采用yum安装,为了节省时间
二、调整系统参数
# 配置系统最大打开文件描述符数vim /etc/sysctl.conffs.file-max=65535# 配置进程最大打开文件描述符vim /etc/security/limits.conf# End of file* soft nofile 65535* hard nofile 65535# 配置 JVM内存(可选)vim /etc/sysconfig/elasticsearchES_HEAP_SIZE=16g# 机器的可用内存为32G
三、elasticsearch集群
1.部署ES yum源
这里采用rpm安装方式,安装的方式看个人喜好去选择,这里就不过多强调了,根据官网的安装方式进行安装。
需要编辑/etc/yum.repos.d/elasticsearch.repo内容如下:
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
2.配置验证KEY:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearc
3.安装ES server
yum install -y elasticsearch
配置Es 配置文件,RPM安装的配置文件默认路径为 /etc/elasticsearch/elasticsearch.yml
# 配置ES配置文件vim /etc/elasticsearch/elasticsearch.yml# 内容如下:grep -Ev '(^$|#)' /etc/elasticsearch/elasticsearch.ymlcluster.name: YL-Cluster # 集群名称node.name: es-node01 # 节点IDpath.data: /data/es/data # ES数据路径path.logs: /data/es/logs # ES日志路径network.host: 10.10.10.202 # 主机地址,可以是IP,也可以主机名,你开心就好http.port: 9200 # 服务监听端口,保持默认即可discovery.zen.ping.unicast.hosts: ["10.10.10.202", "10.10.10.200"]discovery.zen.minimum_master_nodes: 1bootstrap.system_call_filter: falsehttp.cors.enabled: truehttp.cors.allow-origin: "*"
另外一台ES的配置文件和上述相同,要注意的是修改一下:
node.name: es-node02network.host: 10.10.10.200
注: path.data、path.logs 这两个参数指定的路径,如果没有需要自己创建,还要赋予权限给elasticsearch用户。ES nodes都是一样的。
启动方式这里说一下,采用RPM安装,会自动在/etc/init.d/目录下生成elasticsearch的启动文件所以启动方式如下:
/etc/init.d/elasticsearch start或service elasticsearch start# Centos 7使用一下启动方式systemctl start elasticsearch
4.安装head、bigdesk、kopf插件
由于elasticsearch 5.X不再建议支持插件的安装方式,所以推荐使用独立的方式安装head、bigdesk插件。
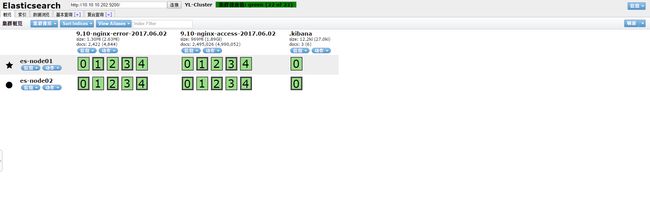
1.安装head插件
插件链接:https://github.com/mobz/elasticsearch-head
# Install && Runninggit clone git://github.com/mobz/elasticsearch-head.gitcd elasticsearch-headnpm installnohub npm run server &# 注意给elasticsearch配置一下两个参数,方便head插件可以访问eshttp.cors.enabled: truehttp.cors.allow-origin: "*"
OK,这里安装结束了,打开你的浏览器访问http://headserverIP:9100,效果如下:
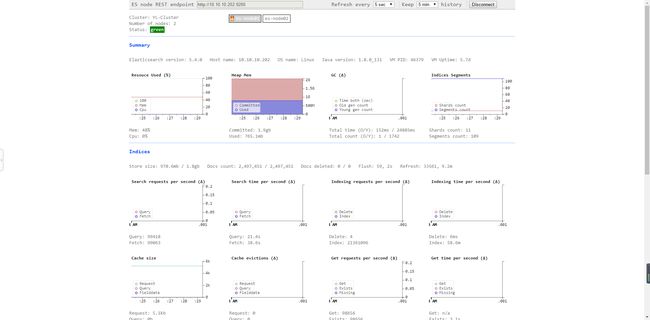
2.安装bigdesk插件
插件链接:https://github.com/hlstudio/bigdesk
# 大致安装步骤如下:git clone https://github.com/hlstudio/bigdeskcd bigdesk/_site/# 启动服务python -m SimpleHTTPServer或nohub python -m SimpleHTTPServer &
bigdesk的默认地址为:http://bigdeskserverip:8000,效果如下:
3.安装kopf插件
四、Zookeeper集群
配置10.10.10.121/10.10.10.123/10.10.10.125的zookeeper集群
1.安装Zookeeper
zookeeper官网: http://zookeeper.apache.org/
这里要注意,请下载XXX版,无需安装解压可用,千万不要下载错了。
# zookeeper依赖于java,前面已经安装了,这里就不在强调了wget# 解压到/usr/local目录下tar -zxvf zookeeper-3.4.9.tar.gz -C /usr/local# 编写配置文件vim /usr/local/zookeeper-3.4.9/conf/zoo.cfggrep -Ev '(^$|#)' /usr/local/zookeeper-3.4.9/conf/zoo.cfgtickTime=2000initLimit=10syncLimit=5dataDir=/usr/local/zookeeper/datadataLogDir=/usr/local/zookeeper/logsclientPort=2181server.1=zk001:2888:2777server.2=zk002:2888:2777server.3=zk003:2888:2777
同步配置文件到其他两台节点,
zookeeper集群,每个节点的配置都是一样的,不需要做任何更改,不熟悉的zookeeper的小伙伴,可以参考:
scp zoo.cfg 10.10.10.123:/usr/local/zookeeper-3.4.9/conf/zoo.cfg
scp zoo.cfg 10.10.10.125:/usr/local/zookeeper-3.4.9/conf/zoo.cfg
2.创建myid
# 10.10.10.121echo 1 >/usr/local/zookeeper-3.4.9/data/myid# 10.10.10.123echo 2 >/usr/local/zookeeper-3.4.9/data/myid# 10.10.10.125echo 3 >/usr/local/zookeeper-3.4.9/data/myid
3.启动服务 & 查看状态
# 10.10.10.121bin/zkServer.sh startbin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfgMode: leader# 10.10.10.123bin/zkServer.sh startbin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfgMode: follower# 10.10.10.125bin/zkServer.sh startbin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfgMode: follower
五、Kafka集群
配置kafka broker集群
Kafka官网: http://kafka.apache.org/
1.安装Kfaka
# 下载免安装版本,Binary 版本,记得自己看清楚wget http://219.238.4.227/files/A180000005766BA1/mirrors.hust.edu.cn/apache/kafka/0.10.2.1/kafka_2.12-0.10.2.1.tgztar -zxvf kafka_2.12-0.10.2.1.tgz -C /usr/local
2.修改配置文件
# 10.10.10.121 节点[root@zk001 config]# grep -Ev '(^$|#)' server.propertiesbroker.id=1delete.topic.enable=truelisteners=PLAINTEXT://10.10.10.121:9092num.network.threads=8num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600log.dirs=/usr/local/kafka/data/kafka-logsnum.partitions=20num.recovery.threads.per.data.dir=1log.retention.hours=72log.segment.bytes=1073741824log.retention.check.interval.ms=300000zookeeper.connect=10.10.10.121:2181,10.10.10.123:2181,10.10.10.125:2181zookeeper.connection.timeout.ms=6000
同步配置文件到10.10.10.123/10.10.10.125,内容基本相同,只需要修改一下broker.id和listeners
# 同步配置文件scp server.properties 10.10.10.123:/usr/local/kafka/kafka_2.11-0.10.0.1/config/scp server.properties 10.10.10.125:/usr/local/kafka/kafka_2.11-0.10.0.1/config/# 修改broker.id和listeners# 10.10.10.123broker.id=2listeners=PLAINTEXT://10.10.10.123:9092# 10.10.10.125broker.id=3listeners=PLAINTEXT://10.10.10.125:9092
3.配置对应IP解析
# 10.10.10.121vim /etc/hosts10.10.10.121 zk00110.10.10.123 zk00210.10.10.125 zk003# 其他两台的的hosts配置也是一样的,记得同步
4.启动kafka
cd /usr/local/kafka/bin./kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties# 其他两个节点的服务启动方式是一样的
到此,kakfa+zookeeper集群搭建完成。
友情赠送:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test # 创建topicbin/kafka-topics.sh --list --zookeeper localhost:2181 # 查看已经创建的topic列表bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test # 查看topic的详细信息bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test # 发送消息, 回车后模拟输入一下消息bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test # 消费消息, 可以换到其他kafka节点, 同步接收生产节点发送的消息bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic test --partitions 6 # 给topic增加分区bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test1 # 删除已经创建的topic, 前提是开了delete.topic.enable=true参数如果还不能删除, 可以到zookeeper中去干掉它cd /usr/local/zookeeper-3.4.9/bin/zkCli.shls /brokers/topics # 查看topicrmr /brokers/topics/test1 # 删除topic
六、Logstash
配置10.10.10.121 节点
1.安装logstash
# yum源elasticsearch.repo中就已经包含logstash了,所以无需配置yum源,直接运行以下命令yum install logstash
注意:
如果你的JDK采用源码安装,那么rpm会无法找到你的JAVA_HOME,也就无法配置启动文件,
根据我的环境,Centos6.5,我在其他机器上,采用yum安装JDK,yum安装logstash,将生成的启动文件拷贝过来,然后修改一下logstash启动文件中的logstash.lib.sh
vim ${logstash_basedir}/bin/logstash.lib.shexport JAVA_HOME=/usr/local/jdk-1.8.0
2.配置logstash
logstash 默认配置文件在/etc/logstash/logstash.yml,通常情况下,不需要做一些改动。
3.启动logstash
==官方给出相关启动方式,根据你的系统可以参考==:运行logstash的三种方式
4.测试logstash正常运行
在终端中运行以下命令:
${logstash_basedir}/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
命令执行后,等待你的输入,没问题,输入hello world,回车看看返回什么结果!
{"message" => "Hello World","@version" => "1","@timestamp" => "2014-08-07T10:30:59.937Z","host" => "raochenlindeMacBook-Air.local",}
如果返回类似以上内容,没错你已经安装OK了,下面只需要根据你的需求进行日志收集了,这里举一个例子,使用logstash收集nginx access日志。
4.配置logstash收集nginx日志
input {path => [ "/usr/local/nginx/logs/access.log" ]type => "nginx_access"}filter {# 这里使用正则过滤,对日志进行清洗,这里就先不详细展示了}output {elasticsearch {hosts => [ "10.10.10.202:9200" ]index => "logstash-%{type}-%{+YYYY.MM.dd}"manage_template => trueflush_size => 50000idle_flush_time => 10workers => 2}stdout {codec => rubydebug }}
好了,到这里logstash的基本安装配置就OK了,有关logstash的使用方法,请参考官网:logstash官方文档
七、Filebeat
Filebeat也是elasticsearch的产品,并且软件也包含在elasticsearch YUM源中,可以直接安装
1.安装filebeat
yum install -y filebeat
2.配置filbeat
RPM安装
```bash###################### Filebeat Configuration Example ########################## This file is an example configuration file highlighting only the most common# options. The filebeat.full.yml file from the same directory contains all the# supported options with more comments. You can use it as a reference.## You can find the full configuration reference here:# https://www.elastic.co/guide/en/beats/filebeat/index.html#=========================== Filebeat prospectors =============================filebeat.prospectors:# Each - is a prospector. Most options can be set at the prospector level, so# you can use different prospectors for various configurations.# Below are the prospector specific configurations.# 指定文件的输入类型log(默认)或者stdin。- input_type: log# paths 指定要监控的日志,可以指定具体得文件或者目录paths:- /var/log/*.logdocument_type: syslog#- c:\programdata\elasticsearch\logs\*# Exclude lines. A list of regular expressions to match. It drops the lines that are# matching any regular expression from the list.# 在输入中排除符合正则表达式列表的那些行。exclude_lines: ["^DBG"]# Include lines. A list of regular expressions to match. It exports the lines that are# matching any regular expression from the list.# 包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines执行完毕之后会执行exclude_linesinclude_lines: ["^ERR", "^WARN"]# Exclude files. A list of regular expressions to match. Filebeat drops the files that# are matching any regular expression from the list. By default, no files are dropped.# 忽略掉符合正则表达式列表的文件#exclude_files: [".gz$"]# Optional additional fields. These field can be freely picked# to add additional information to the crawled log files for filtering# 向输出的每一条日志添加额外的信息,比如“level:debug”,方便后续对日志进行分组统计。# 默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,例如fields.level# 这个得意思就是会在es中多添加一个字段,格式为 "filelds":{"level":"debug"}#fields:# level: debug# review: 1### Multiline options# Mutiline can be used for log messages spanning multiple lines. This is common# for Java Stack Traces or C-Line Continuation# 适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [# 多行日志开始的那一行匹配的pattern#multiline.pattern: ^\[# Defines if the pattern set under pattern should be negated or not. Default is false.# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】#multiline.negate: false# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern# that was (not) matched before or after or as long as a pattern is not matched based on negate.# Note: After is the equivalent to previous and before is the equivalent to to next in Logstash# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志#multiline.match: after#================================ General =====================================# The name of the shipper that publishes the network data. It can be used to group# all the transactions sent by a single shipper in the web interface.# 用于发布网络数据的shipper名称. 可以被应用于组# 所有的事务通过一个shipper发送到web接口# 默认使用主机名.#name:# The tags of the shipper are included in their own field with each# transaction published.# shipper的标记包含在自己的field中发表事物,通过不同的tags很容易给服务器逻辑分组#tags: ["service-X", "web-tier"]# Optional fields that you can specify to add additional information to the# output.# 可选字段,您可以指定额外的信息添加到输出。字段可以是标量值,数组,字典,或任何的嵌套组合#fields:# env: staging#================================ Outputs =====================================# Configure what outputs to use when sending the data collected by the beat.# Multiple outputs may be used.#-------------------------- Elasticsearch output ------------------------------# 输出到数据配置.单个实例数据可以输出到elasticsearch、logstash、kafka选择其中一种,注释掉其他的输出配置。# 输出数据到Elasticsearchoutput.elasticsearch:# Array of hosts to connect to.hosts: ["10.10.10.202:9200"]# Optional protocol and basic auth credentials.# 输出认证.#protocol: "https"#username: "elastic"#password: "changeme"#----------------------------- Logstash output --------------------------------output.logstash:# The Logstash hosts# 输出到logstash,由logstash转发给es# 配置logstash的地址,根据个人实际情况而定hosts: ["10.10.10.121:5044"]# Optional SSL. By default is off.# List of root certificates for HTTPS server verifications#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]# Certificate for SSL client authentication#ssl.certificate: "/etc/pki/client/cert.pem"# Client Certificate Key#ssl.key: "/etc/pki/client/cert.key"#----------------------------- Kafka output ----------------------------------output.kafka:# initial brokers for reading cluster metadata# 输出到kafka,由kafka做缓存,然后传输给logstash,配合logstash_to_es.conf# 配置kafka集群地址hosts: ["10.10.10.121:9092", "10.10.10.123:9092", "10.10.10.125:9092"]# message topic selection + partitioningtopic: '%{[type]}'partition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000#================================ Logging =====================================# Sets log level. The default log level is info.# Available log levels are: critical, error, warning, info, debug#logging.level: debug# At debug level, you can selectively enable logging only for some components.# To enable all selectors use ["*"]. Examples of other selectors are "beat",# "publish", "service".#logging.selectors: ["*"]
这里要强调几个filebeat的使用问题:
1.exclude_lines和include_lines,同时配置,会首先执行include_lines,然后再去执行exclude_lines。他们配置没有先后顺序。
2.上面的配置文件,有关输出的部分只是展示一下三种输出方式,输出数据的方向只能选择一种,当你选择一种时,务必要把其他的注释掉。
filebeat的相关配置如上所示,关于它的使用可以参考官方文档:filebeat官方文档