https://blog.csdn.net/xianlingmao/article/details/7891277
https://blog.csdn.net/lfdanding/article/details/50732762
参考文章http://blog.csdn.net/lynnucas/article/details/47947943
转自:http://blog.csdn.net/jteng/article/details/40823675
此处模型选择我们只考虑模型参数数量,不涉及模型结构的选择。
很多参数估计问题均采用似然函数作为目标函数,当训练数据足够多时,可以不断提高模型精度,但是以提高模型复杂度为代价的,同时带来一个机器学习中非常普遍的问题——过拟合。所以,模型选择问题在模型复杂度与模型对数据集描述能力(即似然函数)之间寻求最佳平衡。
人们提出许多信息准则,通过加入模型复杂度的惩罚项来避免过拟合问题,此处我们介绍一下常用的两个模型选择方法——赤池信息准则(Akaike Information Criterion,AIC)和贝叶斯信息准则(Bayesian Information Criterion,BIC)。
AIC是衡量统计模型拟合优良性的一种标准,由日本统计学家赤池弘次在1974年提出,它建立在熵的概念上,提供了权衡估计模型复杂度和拟合数据优良性的标准。
通常情况下,AIC定义为:
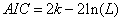
其中k是模型参数个数,L是似然函数。从一组可供选择的模型中选择最佳模型时,通常选择AIC最小的模型。
当两个模型之间存在较大差异时,差异主要体现在似然函数项,当似然函数差异不显著时,上式第一项,即模型复杂度则起作用,从而参数个数少的模型是较好的选择。
一般而言,当模型复杂度提高(k增大)时,似然函数L也会增大,从而使AIC变小,但是k过大时,似然函数增速减缓,导致AIC增大,模型过于复杂容易造成过拟合现象。目标是选取AIC最小的模型,AIC不仅要提高模型拟合度(极大似然),而且引入了惩罚项,使模型参数尽可能少,有助于降低过拟合的可能性。
BIC(Bayesian InformationCriterion)贝叶斯信息准则与AIC相似,用于模型选择,1978年由Schwarz提出。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
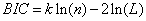
其中,k为模型参数个数,n为样本数量,L为似然函数。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
经常地,对一堆数据进行建模的时候,特别是分类和回归模型,我们有很多的变量可供使用,选择不同的变量组合可以得到不同的模型,例如我们有5个变量,2的5次方,我们将有32个变量组合,可以训练出32个模型。但是哪个模型更加的好呢?目前常用有如下方法:
AIC=-2 ln(L) + 2 k 中文名字:赤池信息量 akaike information criterion
BIC=-2 ln(L) + ln(n)*k 中文名字:贝叶斯信息量 bayesian information criterion
HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
其中L是在该模型下的最大似然,n是数据数量,k是模型的变量个数。
注意这些规则只是刻画了用某个模型之后相对“真实模型”的信息损失【因为不知道真正的模型是什么样子,所以训练得到的所有模型都只是真实模型的一个近似模型】,所以用这些规则不能说明某个模型的精确度,即三个模型A, B, C,在通过这些规则计算后,我们知道B模型是三个模型中最好的,但是不能保证B这个模型就能够很好地刻画数据,因为很有可能这三个模型都是非常糟糕的,B只是烂苹果中的相对好的苹果而已。
这些规则理论上是比较漂亮的,但是实际在模型选择中应用起来还是有些困难的,例如上面我们说了5个变量就有32个变量组合,如果是10个变量呢?2的10次方,我们不可能对所有这些模型进行一一验证AIC, BIC,HQ规则来选择模型,工作量太大。