- 本书目录
机器学习介绍
机器学习是一个系统,可以通过自我改进从实例中学习,而不需要程序员明确编码。机器学习将数据与统计工具相结合以预测输出。机器学习与数据挖掘和贝叶斯预测建模密切相关。机器接收数据作为输入,使用算法来制定答案。
典型的机器学习任务是提供推荐。对于拥有Netflix帐户的用户,所有电影或系列推荐都基于用户的历史数据。科技公司正在使用无监督学习来改善个性化推荐的用户体验。
机器学习还用于各种任务,如欺诈检测,预测维护,投资组合优化,自动化任务等。
机器学习与传统编程
在传统的编程中,程序员在与正在开发软件的行业专家协商时编写所有规则。每条规则都基于逻辑,机器将按逻辑语句执行输出。当系统变得复杂时,需要编写更多规则,很难维护。

机器学习输入和输出提炼规则。每当有新数据时,算法根据新数据和经验进行调整,以提高效率。

机器学习如何运作?
机器学习的方式与人类相似,从经验中学习。机器学习的核心目标是学习和推理。首先,机器通过发现模式来学习。这一发现归功于数据。数据科学家的一个关键部分是仔细选择要为机器提供哪些数据。用于解决问题的属性列表称为特征向量。您可以将特征向量视为用于解决问题的数据子集。
机器使用一些奇特的算法来简化现实并将此发现转换为模型。因此,学习阶段用于描述数据并将其概括为模型。
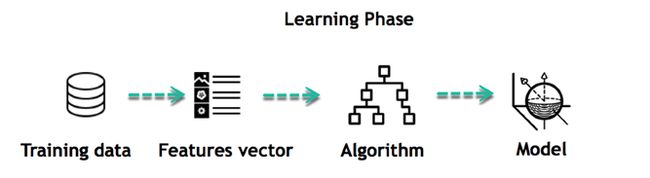
例如,机器试图了解个人工资与去高档餐馆的可能性之间的关系。事实证明,工资与去高端餐厅之间为正比:这就是模型。
- 推理
构建模型时,可以测试它在以前从未见过的数据上的能力。将新数据转换为特征向量,遍历模型并进行预测。无需更新规则或再次训练模型。您可以使用先前训练过的模型来推断新数据。

机器学习程序的生命周期:
定义问题;收集数据;可视化数据;训练算法;测试算法;收集反馈;优化算法;循环4-7次直到结果令人满意;使用模型进行预测
机器学习算法
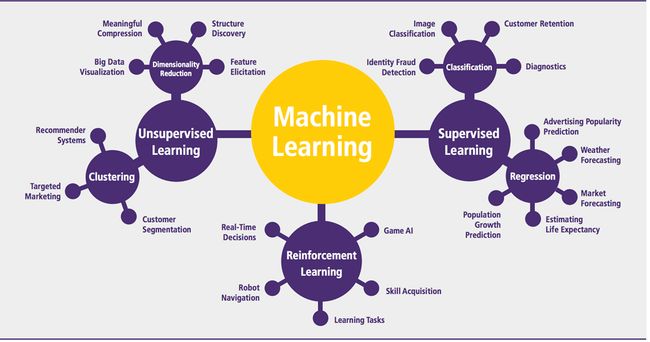
机器学习分类:监督和非监督及半监督。
监督学习
有两种监督学习:
- 分类任务
要预测客户性别。您将开始从数据库收集有关身高,体重,工作,工资,采购篮等的数据。您知道每个客户的性别,它只能是男性或女性。分类器的目的是根据信息(即您收集的特征)分配男性或女性(即标签)的概率。当模型学习如何识别男性或女性时,您可以使用新数据进行预测。例如,您刚收到来自未知客户的新信息,并且您想知道它是男性还是女性。如果分类器预测男性= 70%,则意味着算法确定该客户是男性的70%,而30%是女性。
标签可以是两个或更多个类。上面的例子只有两个类,但是如果分类器需要预测对象,它有几十个类(例如,玻璃,桌子,鞋等,每个对象代表一个类)
- 回归任务
当输出是连续值可以用回归。例如,金融分析师可能需要根据股票,先前股票表现,宏观经济指数等特征来预测股票价值。系统将接受训练,以估算出可能出现最低误差的股票价格。
| 算法 | 描述 | 类型 |
|---|---|---|
| 线性回归 | 找到将每个特征与输出相关联的方法 | 回归 |
| 逻辑回归 | 线性回归的扩展。输出变量只有两个(例如,仅黑色或白色) | 分类 |
| 决策树 | 高度可解释的分类或回归模型,将数据特征值拆分为决策节点处的分支(例如颜色,每种可能的颜色成为新分支),直到做出最终决策输出 | 回归分类 |
| 朴素贝叶斯 | 用可影响事件的每个特征的独立概率更新事件的先验知识。 | 回归分类 |
| 支持向量机 | SVM(Support Vector Machine)算法找到最佳划分类的超平面。它最适合与非线性求解器一起使用。 | 回归(非常见)分类 |
| 随机森林 | 基于决策树之上,可以大大提高准确性。随机森林生成很多次简单的决策树,并使用“多数投票”方法来决定返回哪个标签。对于分类任务,最终预测将是投票最多的;而对于回归任务,所有树的平均预测是最终预测。 | 回归分类 |
| AdaBoost | 分类或回归技术,使用多种模型做出决策,但根据其预测结果的准确性对其进行权衡。 | 回归分类 |
| 梯度增强树 | 先进的分类/回归技术。它专注于先前树所犯的错误并尝试纠正它。 | 回归分类 |
非监督学习
算法探索输入数据而不给出明确的输出(例如,探索客户人口统计数据以识别模式)
当您不知道如何对数据进行分类时,您可以使用它,并且您希望算法找到模式并为您分类数据
| 算法 | 描述 | 类型 |
|---|
K均值聚类 |将数据放入某些组 (k),每组包含具有相似特征的数据(由模型确定,而不是由人类预先确定) |聚类
高斯混合模型 |k-means聚类的泛化,为组(簇)的大小和形状提供了更大的灵活性 |聚类
分层聚类 |沿分层树拆分群集以形成分类系统。可用于群集会员卡客户 |聚类
推荐系统 |帮助定义相关数据 |聚类
PCA / T-SNE |主要用于降低数据的维度。算法将特征数量减少到3或4个具有最高方差的向量。 |尺寸减小
如何选择机器学习算法
有很多机器学习算法。算法的选择基于目标
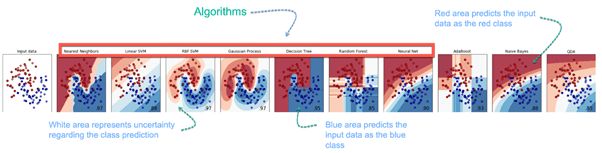
在下面的例子中,任务是预测三个品种中的花的类型。预测基于花瓣的长度和宽度。图片描绘了十种不同算法的结果。左上角的图片是数据集。数据分为三类:红色,浅蓝色和深蓝色。有一些分组。例如,从第二张图像开始,左上角的所有内容都属于红色类别,中间部分则是不确定性和淡蓝色的混合,而底部则对应于深色类别。其他图像显示了不同的算法以及它们如何尝试对数据进行分类。
机器学习的挑战与局限
机器学习的主要挑战是缺乏数据或数据集的密度。建议每组至少观察20次,以帮助机器学习。这种约束导致评估和预测不良。
机器学习的应用
- 增强:
帮助人们完成日常任务,无论是个人还是商业,都无需完全控制输出。机器学习以不同的方式使用,例如虚拟助手,数据分析,软件解决方案。主要用户是减少由于人为偏见造成的错误。
- 自动化:
机器学习可在任何领域完全自主工作,无需任何人为干预。例如,机器人在制造工厂中执行基本工艺步骤。
- 金融业
机器学习在金融业中越来越受欢迎。银行主要使用ML来查找数据中的模式,同时也防止欺诈。
- 政府组织
政府利用ML来管理公共安全和公用事业。以中国为例,面对大规模的人脸。政府使用人工智能来防止中国式过马路。
- 医疗行业
医疗保健是第一个使用机器学习和图像检测的行业之一。
- 营销
在海量数据时代之前,研究人员开发了贝叶斯分析等高级数学工具来估算客户的价值。随着数据的蓬勃发展,营销部门依靠AI来优化客户关系和营销活动。
机器学习在供应链中的应用实例
机器学习为视觉模式识别提供了极好的结果,为整个供应链网络中的物理检查和维护开辟了许多潜在的应用。
无监督学习可以快速搜索不同数据集中的可比模式。反过来,机器可以在整个物流中心进行质量检查,运输时有损坏和磨损。
例如,IBM的Watson平台可以确定运输容器损坏。 Watson将基于视觉和系统的数据结合起来,实时跟踪,报告和提出建议。
在过去一年中,仓库经理广泛依赖于评估和预测库存的主要方法。在结合大数据和机器学习时,已经实施了更好的预测技术(比传统预测工具提高了20%到30%)。就销售而言,这意味着由于库存成本可能降低而增加2%至3%。
机器学习谷歌汽车的例子
Google汽车车顶上装满了激光,告诉它周围区域的位置。它前面有雷达,可以通知汽车周围所有车辆的速度和运动。它利用所有这些数据不仅弄清楚如何驾驶汽车,而且还要弄清楚并预测汽车周围的潜在驾驶员将会做些什么。令人印象深刻的是,该车每秒处理几乎1千兆字节的数据。
参考资料
- 讨论qq群144081101 591302926 567351477 钉钉群21745728
- 本文最新版本地址
- 本文涉及的python测试开发库 谢谢点赞!
- 本文相关海量书籍下载
- 2018最佳人工智能机器学习工具书及下载(持续更新)
为什么机器学习很重要?
到目前为止,机器学习是分析,理解和识别数据模式的最佳工具。机器学习背后的主要思想之一是计算机可以被训练以自动执行对于人类来说是穷举或不可能的任务。机器学习可以在人为干预最少的情况下做出决策。
以下面的例子为例;零售代理商可以根据自己的经验和他对市场的了解来估算房屋的价格。
可以训练机器将专家的知识转化为特征。特征是房屋,社区,经济环境等的所有特征,使价格差异化。对于专家来说,他花了几年时间才掌握估算房屋价格的艺术。每次销售后,他的专业知识越来越好。
对于机器,需要数百万个数据(即示例)来掌握该技术。在学习的最初阶段,机器出错了,不知何故,就像初级推销员一样。一旦机器看到了所有的例子,它就有了足够的知识来进行估算。同时,具有令人难以置信的准确性。机器也可以相应地调整其错误。
大多数大公司都了解机器学习和保存数据的价值。麦肯锡估计,分析的价值在9.5万亿美元到15.4万亿美元之间,而5到7万亿美元的价值可以归功于最先进的人工智能技术。