实时数据的可视化
实时数据特征
通常来说,可视化的报表会以更高效率的方式将数据背后隐藏的信息传递给我们。通过一个简单的BarChart,我们就很容易对比某商品在第二季度中的销量差异;而通过一条简单的LineChart,则很容易看出员工平均工作时间在某个月份的分布。这些报表都或多或少与时间相关:随着时间的流逝,某项指标会因为各种各样的因素而产生变化。
另一方面,在某些领域,我们需要更高时效性的报表。比如产品的线上指标分析:有多少用户当前在线,主站的负载情况如何,有多少在线交易正在形成等等。此外,很多运维数据也希望有更高的实时性,比如目前服务器的负载如何,过去的5分钟的负载情况又是什么样子的等等。
这类报表的特点是:
- 高时效性
- 对于细粒度的指标,数据量可能会很大
- 过了某段特定的时间段,数据的价值会骤降

比如上图是Mac上的CPU使用情况的实时报表,它展现了一段时间内的各个核上的计算负载。这些信息不断产生,有不断被丢弃,没有人关注一个小时之前的CPU占用,只要能展示出最近几分钟的就好。
基于这些特性,如何存取数据、如何分析度量结果、如何滚动历史数据等等都会遇到和其他图表不尽相同的问题。另外,由于实时数据的可视化与时间是强相关的 – 它本质上必须是一个动态的图表,这与其他的图表类型又有不同。我们在这篇文章中将会讨论这些问题,以及解决这些问题的常见方案。
数据指标
对于实时数据,我们关注不同事件发生的次数,以及事件发生时持续的时长等。我们首先需要定义一些对象:
- 计数器(counter)
- 计时器(timer)
- 标量(gauge)
计数器
计数器涉及需要被记录次数的事件(通常是每发生一次,计数器加一/减一),这类数据的增长/减少规律比较固定,比如:
- 响应为200的请求 -
response.code === 200 - 从某个session产生的请求 -
session.id === 'b1b2b3bab22123bb1a'
计时器
计时器涉及所有应该记录时间长度的事件,通常这类时间我们可以通过引入一个时间段(interval)来计算一些统计信息,比如平均值,方差,标准差,最大值,最小值等。比如:
- 请求响应时间 -
response.time - 停留时间 -
stay.time
标量
还有一种经常会用到的量,我们不关注过程中它的变化倾向,只关注某个时刻上的数字/状态,比如:
- 节点是否可用
- 某一时刻的进程数
- 某一时刻的CPU负载/内存占用率
数据处理典型流程
对于生产环境,实时数据既可以以日志的形式提供,也可以是来源于事件数据库。日志是最常见的形式,几乎所有的系统都会以各种各样的方式记录日志,大部分的日志会提供滚动机制:日志会被记录到一个固定尺寸的文件中,旧的日志会被滚动的写入到另一个文件(通常还会有配套的定时任务来清理更早的日志等)。另一方面,对于很多基于事件的软件系统中,事件会被写入到数据库中,这些数据也可以用作实时数据可视化的来源。
原始数据往往不能直接用来做可视化展现,通常我们需要做一些预处理,这些过程包括:
- 原始数据获取
- 结构化
- 初步统计
- 高阶统计
数据结构化
有很多的工具可以帮助我们实现这些步骤,比如我们通过一个简单的配置,就可以让logstash自动将源源不断产生的日志数据写入到statsd(最终周期性的写入到graphite数据库中):
input {
stdin {}
}
filter {
grok {
match => {
"message" => "%{DATA:time} %{DATA:status} %{NUMBER:request_time} %{DATA:campaign} %{DATA:mac} %{DATA:ap_mac} %{GREEDYDATA:session}"
}
}
}
output {
stdout { codec => rubydebug }
statsd {
host => 'localhost'
increment => "airport.%{session}"
}
statsd {
host => 'localhost'
increment => "airport.%{status}"
}
}
logstash是一个非常灵活其高度可定制的工具,我们只需要指定输入数据源,匹配规则,输出数据源即可做到:对于输入中,如果有满足匹配规则的数据,则将这些数据写入到输出中。这个听起来是不是有点像IFTTT(If This Then That)工具做的事情呢?
|
|
在这个例子中,我们使用标准输入为数据源,当输入中有time status request_time campaign mac ap_mac session这样的字符串时,则认为是匹配成功,对于匹配成功的数据,将其通过statsd插件写入到localhost中。increment指令对上述的counter数据类型,即每发生一次匹配,对应的值自增一。
比如当输入的日志内容为:
|
|
匹配结果为:
{
"campaign" => "f3715a7f52d8cef53fef1f73134e487a",
"request_time" => "0.02",
"status" => "403",
"session" => "2293c8e9-8801-485b-9f1d-9e5a7f5a8965",
"message" => "1529242838 403 0.02 f3715a7f52d8cef53fef1f73134e487a 00:61:71:53:f4:0b T2-CL13-49-D87 2293c8e9-8801-485b-9f1d-9e5a7f5a8965",
"@version" => "1",
"host" => "juntao-qiu.local",
"ap_mac" => "T2-CL*-49-D*",
"time" => "1529242838",
"mac" => "00:61:71:53:ff:b0",
"@timestamp" => 2018-06-17T13:40:39.023Z
}这时候,logstash会为airport.2293c8e9-8801-485b-9f1d-9e5a7f5a8965这个counter加一:
|
|
统计
对于结构化的数据,我们需要按照一定的周期来对数据进行初步的统计,比如对于计时器类型的数据,需要做求和,平均值,方差、标准差,中位数等的计算;而对于计数器,则需要累计其值。我们可以通过statsd来完成这些动作。
StatsD本质上来说,是一个非常简单基于UDP的服务。而对于大多数情况,为了避免在数据量变大的时候TCP的巨大开销,使用UDP的不可靠(但是高效)连接反而更可靠。StatsD在接受到客户端请求后,会在本地维护一些counter和timer的计数,然后定时的(默认为10秒)会向graphite发送一次数据。
可视化
对于实时数据的可视化,有很多需要考虑的点。比如结果是呈现在Desktop上还是Web页面上或者移动设备上?对于Web界面来说,是否需要考虑响应式设计,以匹配不同尺寸的屏幕?是否需要又动态的交互,或者只需要静态的展现即可?
另一方面,项目对于数据精度的要求是什么?需要精确到分钟级别,或者是每15分钟?对于不同精度的数据,对存储容量的要求是完全不同的。一种常见的策略是将过期的数据降低精度,而仅仅为最近的数据提供高精度。
对于销售结果,精确到天的统计已经算是实时数据。而对于在线交易的监控,则需要精确到秒级别。在设计这种数据可视化的时候,需要充分考虑对数据实时性的要求。
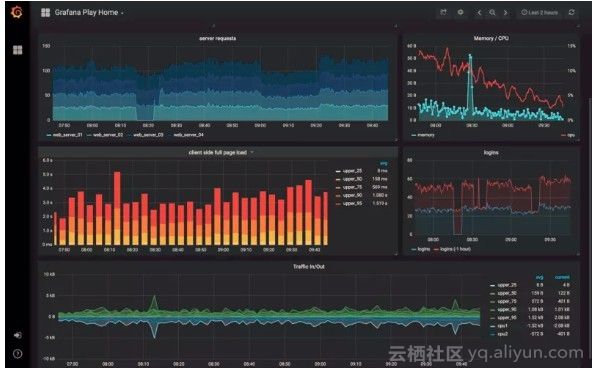
上图一个典型的基于Web的实时数据可视化Dashboard。
工具
在实现实时数据可视化的过程中,我们需要一系列工具的支撑。简而言之,我们需要实际保存数据的数据库,需要保存/查询数据的客户端API,最后是用于客户端呈现的库或者框架。
时间序列数据库
对于实时数据的存储,事实上有一个专门的数据库分类:时间序列数据库(Time Series DBMS)。时间序列数据库是一个Key-Value数据库的细分,通常它维护的对象为:时间戳,指标名称,指标值。另外,各个实现往往还会提供一些Query Language来方便指标的检索。
这里是一些常见的时序数据库(或者被用作时序数据库)的实现:
- Graphite
- Influxdb
- Promethous
Feeder / API
虽然大部分时序数据库都提供Native API来进行数据的存储、检索,不过大部分时候人们更倾向使用简单的HTTP API或者客户端库。
比如,StatsD是一个Node.js的服务,通过它的客户端API,我们可以很容易的创建counter, timer等指标。
- StatsD
- Graphite
数据的可视化
Grafana是一个非常强大、已于使用的客户端框架。通过它,你可以很容易的将多个数据源的数据集成在同一个Dashboard上进行展现。比如CPU/Memory的负载信息来自于graphite,而用户的在线情况则可能来自于influxdb或者promethous。
如果你需要更高的可定制性,比如在自己的页面上绘制一个实时图表,则可以考虑使用d3.js+cubism的组合。它可以从不同的后端API周期性的获取数据,并实时呈现在svg/canvas画布上。
- Grafana
- Cubism
数据直接呈现
Logstalgia
Logstalgia可以将特定格式的日志文件分析,并以一种非常酷炫的方式展现出来,就好像是在玩经典游戏打砖块一样。
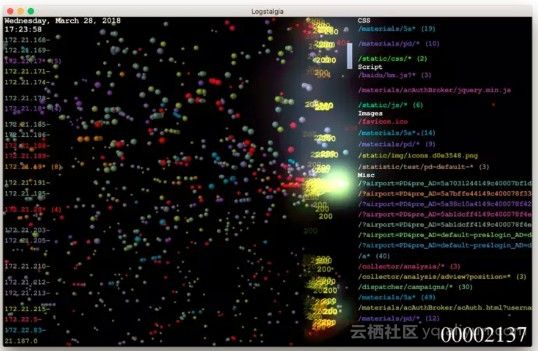
Logstalgia要求一些必填字段:
- UNIX时间戳
- 请求的hostname/ip
- 请求资源的路径
- 响应码(201, 500等)
- 响应的大小
|
|
如果原始日志不是这个格式,你可以写一个简单的转换器来适配:
|
|
注意这个脚本的输入和输出是标准输入和输出,即你可以通过管道将它接入到命令行中。比如:
|
|
不过,logstalgia只能运行在Desktop上,应用的外观比较固定,基本上无法定制(比如动画效果的配置等)。更多时候,我们希望可以将实时数据的呈现放在Web端,以提高可定制性。
实时数据呈现
如果要做到实时呈现,我们可以直接读取日志,并将日志通过WebSocket发送给客户端。这种做法的好处是实时,比如一个相应为500的错误,一个交易失败的异常等,可以非常直观的展现出来。它的缺点也很明显,一方面如果信息量很大,即日志写入速度太快,前端很可能处理不过来,另一方面,这种被摊平的原始信息可能太过于粗糙,无法做到统计分析。
WebScoket + D3.js
|
|
我们通过spawn来在子进程中启动一个shell脚本,这个脚本会不断的从远程服务器上的日志文件中读取日志,并输出到控制台上。当有新的WebSocket连接建立时,我们会将generator子进程上产生的数据写入该连接,当然,在写入前会将基于行的日志解析成客户端消费的结构化的数据,并以JSON格式返回。
最后,当客户端主动断开连接时,我们需要将generator上的事件监听函数删除掉。
这里的generator.sh内容可以是任何能从日志读取信息,并输出到控制台的脚本。比如最简单的可能是这样:
|
|
如果本地没有访问流量,我们可以将其指向测试环境:
|
|
对于客户端而言,只需要在页面加载时建立一个WebSocket连接,当数据到来时做重新处罚绘制接口。此处使用了一个D3.js的实时报表插件。
|
|
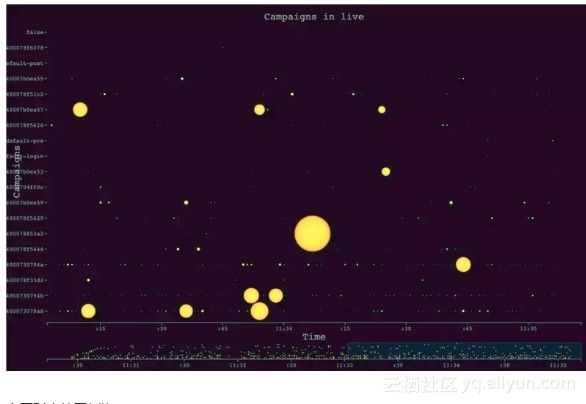
上图对应的图例为:
- 横轴表示时间
- 纵轴表示被请求的特定资源(比如某个API,或者某个静态图片)
- 每一个时刻被请求到的资源会在画布上形成一个点
- 点的大小反应了响应时长
统计信息的呈现
使用Graphite
graphite自带了一个可视化的界面,你可以选择将多个指标展现在同一个界面上:

除此之外,graphite还提供了更强大的renderAPI,使用这个API,你可以获得多种输出格式,比如:csv, json等,方便二次开发。另一方面,你可以通过target参数将表达式来获取更为复杂的指标计算。
比如:
|
|
其中,format指定了json,而target指定了指标的名称,事实上,target可以更丰富:
|
|
这里的target的值为alias(sumSeries(stats.jc.airport.campaigns.*), ''),表示要对所有的以stats.jc.airport.campaigns开头的指标的值求和。通过from和until指定起止时间,可以获取在该段时间中所有的数据,这样我们可以通过客户端轮询的方式,逐步的、实时的展现出一些指标的统计信息。
Graphite提供了丰富的函数用以聚合指标,比如求平均值,方差,极值等常规操作,还可以对两个/多个指标进行算数操作,从而获得新的数据集等等。这里有一份完整的列表。
使用 Horizon Chart 展现实时数据
Cubism是D3.js的一个插件,专门用来展现基于时间的实时报表。事实上,Cubism背后有许多研究和论文支持,即horizon Chart(地平线图)。这种图表会以一个固定频率来不断的刷新,数据看起来会不断的向左侧移动,最左侧的、老的数据会消失;同事右侧会不断的有新的数据流入并被绘制。
你可以为地平线图指定不同的数据源,以graphite为例,你可以这样指定:
|
|
这样cubism会向graphite服务器会定时的发送请求:
|
|
然后根据实际的数据,cubism会不断的刷新图表:
|
|
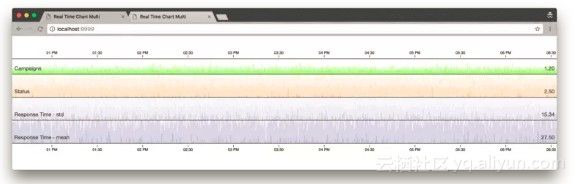
事实上,由于horizon图表纵向占用的空间很少,你可以很容易的将多个表合并在一起,形成多行图表。
小结
本文介绍了实时数据可视化的一些典型场景,以及通用的数据准备及呈现方法。通过一些既有的工具或者简单的脚本,我们就可以将实时产生的数据feed到统计用的时序数据库,然后按照不同的需求方式呈现出来。通常来说,基于固定时间间隔的统计数据更有意义一些,比如单位时间内的请求数量,请求的平均时延等;另一方面,仅仅将数据实时的呈现出来在某些场景下也非常有意义,比如系统实时的在线人数,发生登陆异常的占比,某些节点高于90%的负载等信息。
参考资料
- Horizon Chart
- Visualisation Papers
- Cubism
其他资料
- Setup Graphite in Docker
- An concrete example for using cubism with graphite
原文作者:掘金
本文来源: 掘金 如需转载请联系原作者