tensorflow 验证码识别(captcha)
验证码识别方法
-
传统的机器学习方法,对于多位字符验证码都是采用的 化整为零 的方法:先分割成最小单位,再分别识别,然后再统一。
-
卷积神经网络方法,直接采用 端到端不分割 的方法:输入整张图片,输出整个图片的标记结果,具有更强的通用性。端到端 的识别方法显然更具备优势,因为目前的字符型验证码为了防止被识别,多位字符已经完全融合粘贴在一起了,利用传统的技术基本很难实现分割了。
卷积神经网络方法步骤
- generate_captcha.py - 利用 Captcha 库生成验证码;
- captcha_model.py - CNN 模型;
- train_captcha.py - 训练 CNN 模型;
- predict_captcha.py - 识别验证码。
1 generate_captcha.py
图片验证码是由数字、大写字母、小写字母组成(当然你也可以根据自己的需求调整,比如添加一些特殊字符),长度为 4,所以总共有 6 2 4 62^4 624 种组合验证码。
pip install captcha
#!/usr/bin/python
# -*- coding: utf-8 -*
from captcha.image import ImageCaptcha
from PIL import Image
import numpy as np
import random
import string
class generateCaptcha():
def __init__(self,
width = 160,#验证码图片的宽
height = 60,#验证码图片的高
char_num = 4,#验证码字符个数
characters = string.digits + string.ascii_uppercase + string.ascii_lowercase):#验证码组成,数字+大写字母+小写字母
self.width = width
self.height = height
self.char_num = char_num
self.characters = characters
self.classes = len(characters)
def gen_captcha(self,batch_size = 50):
X = np.zeros([batch_size,self.height,self.width,1])
img = np.zeros((self.height,self.width),dtype=np.uint8)
Y = np.zeros([batch_size,self.char_num,self.classes])
image = ImageCaptcha(width = self.width,height = self.height)
# 这个总体的无限循环是一个训练集的生成器,执行此代码后,会在最后的yield语句返回训练集X和Y,
# 然后循环结束。下次再想生成验证码训练集时,会从yield语句(最后一句)开始,回到开头再执行一次循环。
while True:
for i in range(batch_size):
# 生成一个验证码字符串的随机变量,self.characters为62位的字符串(0~9A~Za~z),self.char_num=4(生成4个字符)。
captcha_str = ''.join(random.sample(self.characters,self.char_num))
# 使用的是ImageCaptcha类的内置方法,将字符串变为图片。convert(‘L’):表示生成的是灰度图片,就是通道数为1的黑白图片。
img = image.generate_image(captcha_str).convert('L')
# Returns the contents of this image as a sequence object containing pixel values. The sequence object is flattened, so that values for line one follow directly after the values of line zero, and so on.
# 将此图像的内容作为包含像素值的序列对象返回。Sequence对象是新的,因此第一行的值直接跟随在零行的值之后,依此类推。
img = np.array(img.getdata())
# 每个像素值都要除以255,这是为了归一化处理,因为灰度的范围是0~255,这里除以255就让每个像素的值在0~1之间,目的是为了加快收敛速度。
X[i] = np.reshape(img,[self.height,self.width,1])/255.0
# 用以生成对应的测试集Y,j和ch用以遍历刚刚生成的随机字符串,j记录index(0~3,表示第几个字符),ch记录字符串中的字符。找到Y的第i条数据中的第j个字符,然后把62长度的向量和ch相关的那个置为1。
for j,ch in enumerate(captcha_str):
Y[i,j,self.characters.find(ch)] = 1
Y = np.reshape(Y,(batch_size,self.char_num*self.classes))
yield X,Y
def decode_captcha(self,y):
y = np.reshape(y,(len(y),self.char_num,self.classes))
return ''.join(self.characters[x] for x in np.argmax(y,axis = 2)[0,:])
def get_parameter(self):
return self.width,self.height,self.char_num,self.characters,self.classes
def gen_test_captcha(self):
image = ImageCaptcha(width = self.width,height = self.height)
captcha_str = ''.join(random.sample(self.characters,self.char_num))
img = image.generate_image(captcha_str)
img.save(captcha_str + '.jpg')
X = np.zeros([1,self.height,self.width,1])
Y = np.zeros([1,self.char_num,self.classes])
img = img.convert('L')
img = np.array(img.getdata())
X[0] = np.reshape(img,[self.height,self.width,1])/255.0
for j,ch in enumerate(captcha_str):
Y[0,j,self.characters.find(ch)] = 1
Y = np.reshape(Y,(1,self.char_num*self.classes))
return X,Y
random.sample() method return a k length list of unique elements chosen from the population sequence or set, used for random sampling without replacement.
从序列(sequence)中随机选择k个元素,返回的是一个新的list,原来的序列不受影响。
X:一个 mini-batch 的训练数据,其 shape 为 [ batch_size, height, width, 1 ],batch_size 表示每批次多少个训练数据,height ,width 表示验证码图片的高和宽,1 表示这是1个通道的黑白图片。
Y:X 中每个训练数据属于哪一类验证码,其形状为 [ batch_size, class ] ,对验证码中每个字符进行 One-Hot 编码,所以 class 大小为 4*62。
1.2 进入cmd
cd D:\LearningFiles\VerificationCode-yueying\sdxx_train_over
python3
from generate_captcha import generateCaptcha
g = generateCaptcha()
X,Y = g.gen_test_captcha()
2 captcha_model.py
CNN 模型
总共 5 层网络,前 3 层为卷积层,第 4、5 层为全连接层。对 4 层隐藏层都进行 dropout。
网络结构如下所示: input——>conv——>pool——>dropout——>conv——>pool——>dropout——>conv——>pool——>dropout——>fully connected layer——>dropout——>fully connected layer——>output

# -*- coding: utf-8 -*
import tensorflow as tf
import math
class captchaModel():
def __init__(self,
width = 160,
height = 60,
char_num = 4,
classes = 62):
self.width = width
self.height = height
self.char_num = char_num
self.classes = classes
# 这是2维卷积函数。x表示传入的待处理图片,W表示卷积核,strides=[1, 1, 1, 1],其中第二个和第三个1分别表示x方向步长和y方向步长,
# padding=’SAME’表示边界处理策略设为’SAME’,这样卷积处理完图片大小不变。
def conv2d(self,x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 这是2×2最大值池化函数。x表示待被池化处理的图片,ksize=[1, 2, 2, 1],
# 其中第二个和第三个2分别表示池化窗口高度和池化窗口宽度,strides和padding意义同上。
def max_pool_2x2(self,x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 从截断的正态分布中输出随机值。X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,
# 在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)
# 看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
def weight_variable(self,shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 生成一组全部都是0.1的常量数
def bias_variable(self,shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def create_model(self,x_images,keep_prob):
#first layer
w_conv1 = self.weight_variable([5, 5, 1, 32])
b_conv1 = self.bias_variable([32])
h_conv1 = tf.nn.relu(tf.nn.bias_add(self.conv2d(x_images, w_conv1), b_conv1))
h_pool1 = self.max_pool_2x2(h_conv1)
h_dropout1 = tf.nn.dropout(h_pool1,keep_prob)
conv_width = math.ceil(self.width/2)
conv_height = math.ceil(self.height/2)
# w_conv1是卷积核,可以理解为一共有32个卷积核,每个卷积核的尺寸是(5, 5, 1),
# 即长度和宽度都是5,通道是1。每个卷积核对图片处理完就会产生一张特征图,32个卷积核对
# 图片处理完后就会产生32个特征图,将这些特征图叠加排列,那么原本通道数为1的图片现在通道
# 数变为图片的个数,也就是32。图片的尺寸变化为(?, 60, 160, 1) –> (?, 60, 160, 32)。
# 随后又对图片进行一次池化处理,池化窗口为2×2,所以图片的长度和宽度都会变为原来的一半。
# 图片的尺寸变化为(?, 60, 160, 32) → (?, 30, 80, 32)。
# 随后又进行了一次dropout以防止过拟合,同时也是为了加大个别神经元的训练强度。
#second layer
w_conv2 = self.weight_variable([5, 5, 32, 64])
b_conv2 = self.bias_variable([64])
h_conv2 = tf.nn.relu(tf.nn.bias_add(self.conv2d(h_dropout1, w_conv2), b_conv2))
h_pool2 = self.max_pool_2x2(h_conv2)
h_dropout2 = tf.nn.dropout(h_pool2,keep_prob)
conv_width = math.ceil(conv_width/2)
conv_height = math.ceil(conv_height/2)
# w_conv2是第二层卷积神经网络的卷积核,共有64个,每个卷积核的尺寸是(5, 5, 32),处理之后
# 图片的尺寸变化为(?, 30, 80, 32) → (?, 30, 80, 64)。
# 随后又对图片进行一次池化处理,池化窗口为2×2,所以图片的长度和宽度都会变为原来的一半。
# 图片的尺寸变化为(?, 30, 80, 64) → (?, 15, 40, 64)。
# 再进行一次dropout以防止过拟合,同时也是为了加大个别神经元的训练强度。
#third layer
w_conv3 = self.weight_variable([5, 5, 64, 64])
b_conv3 = self.bias_variable([64])
h_conv3 = tf.nn.relu(tf.nn.bias_add(self.conv2d(h_dropout2, w_conv3), b_conv3))
h_pool3 = self.max_pool_2x2(h_conv3)
h_dropout3 = tf.nn.dropout(h_pool3,keep_prob)
conv_width = math.ceil(conv_width/2)
conv_height = math.ceil(conv_height/2)
# w_conv3是第三层卷积神经网络的卷积核,共有64个,每个卷积核的尺寸是(5, 5, 64),处理之后
# 图片的尺寸变化为(?, 15, 40, 64) → (?, 15, 40, 64)。
# 随后又对图片进行一次池化处理,池化窗口为2×2,所以图片的长度和宽度都会变为原来的一半。
# 图片的尺寸变化为(?, 15, 40, 64) → (?, 8, 20, 64),这里的15 / 2 = 8,是因为边界策略为
# SAME,那么遇到剩下还有不足4个像素的时候同样采取一次最大值池化处理。
# 再进行一次dropout以防止过拟合,同时也是为了加大个别神经元的训练强度。
#first fully layer
conv_width = int(conv_width)
conv_height = int(conv_height)
w_fc1 = self.weight_variable([64*conv_width*conv_height,1024])
b_fc1 = self.bias_variable([1024])
h_dropout3_flat = tf.reshape(h_dropout3,[-1,64*conv_width*conv_height])
h_fc1 = tf.nn.relu(tf.nn.bias_add(tf.matmul(h_dropout3_flat, w_fc1), b_fc1))
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 这里就把刚刚卷积神经网络的输出作为传统神经网络的输入了,w_fc1(10240, 1024)和b_fc1(1024)
# 分别是这一层神经网络的参数以及bias。上面代码第五行将卷积神经网络的输出数据由(?, 8, 20, 64)
# 转为了(?, 64 * 20 * 8),可以很明显感觉出来把所有的数据拉成了一条一维向量,然后经过矩阵
# 处理,这里的数据变为了(1024, 1)的形状。
#second fully layer
w_fc2 = self.weight_variable([1024,self.char_num*self.classes])
b_fc2 = self.bias_variable([self.char_num*self.classes])
y_conv = tf.add(tf.matmul(h_fc1_drop, w_fc2), b_fc2)
# 再连接一次神经网络,这次不再需要添加激励函数了ReLu了,因为已经到达输出层,线性相加后直接
# 输出就可以了,结果保存在y_conv变量里,最后将y_conv返回给调用函数。
return y_conv
# 这是外层函数调用model后所得到的训练结果。
3 train_captcha.py
训练 CNN 模型,每批次采用 64 个训练样本,每 100 次循环检查1次识别准确度,当精准度大于0.99时,训练结束,采用 GPU 需要 4-5 个小时左右,CPU 大概需要 20 个小时左右。
#-*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import string
import generate_captcha
import captcha_model
if __name__ == '__main__':
captcha = generate_captcha.generateCaptcha()
width,height,char_num,characters,classes = captcha.get_parameter()
x = tf.placeholder(tf.float32, [None, height,width,1])
y_ = tf.placeholder(tf.float32, [None, char_num*classes])
keep_prob = tf.placeholder(tf.float32)
model = captcha_model.captchaModel(width,height,char_num,classes)
y_conv = model.create_model(x,keep_prob)
# 由于识别验证码本质上是对验证码中的信息进行分类,所以我们这里使用cross_entropy的方法来衡量损失。
# 优化方式选择的是AdamOptimizer,学习率设置比较小,为1e-4,防止学习的太快而训练不好。
cross_entropy = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y_,logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
predict = tf.reshape(y_conv, [-1,char_num, classes])
real = tf.reshape(y_,[-1,char_num, classes])
correct_prediction = tf.equal(tf.argmax(predict,2), tf.argmax(real,2))
correct_prediction = tf.cast(correct_prediction, tf.float32)
accuracy = tf.reduce_mean(correct_prediction)
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 1
while True:
batch_x,batch_y = next(captcha.gen_captcha(64))
_,loss = sess.run([train_step,cross_entropy],feed_dict={x: batch_x, y_: batch_y, keep_prob: 0.75})
print ('step:%d,loss:%f' % (step,loss))
if step % 100 == 0:
batch_x_test,batch_y_test = next(captcha.gen_captcha(100))
acc = sess.run(accuracy, feed_dict={x: batch_x_test, y_: batch_y_test, keep_prob: 1.})
print ('###############################################step:%d,accuracy:%f' % (step,acc))
if acc > 0.99:
saver.save(sess,"./capcha_model.ckpt")
break
step += 1
然后执行:
python3 train_captcha.py
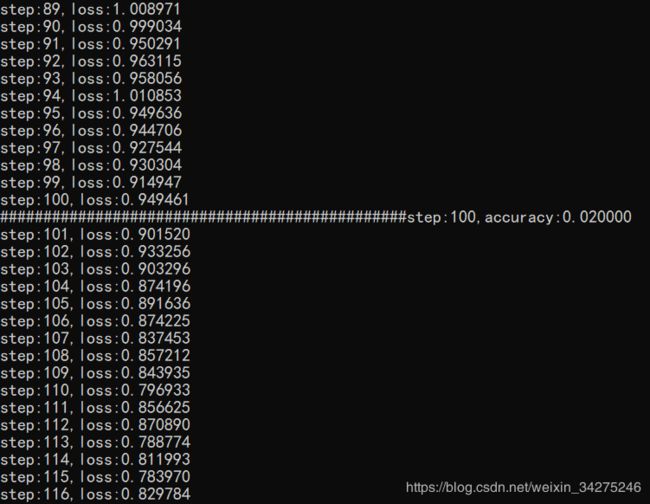
step为步长,每100批测试一次训练集,loss为损失值,我的电脑惠普envy,i5-8250U,MX150大概需要18h完成训练。
4 predict_captcha.py
测试识别验证码
#-*- coding:utf-8 -*-
from PIL import Image, ImageFilter
import tensorflow as tf
import numpy as np
import string
import sys
import generate_captcha
import captcha_model
if __name__ == '__main__':
captcha = generate_captcha.generateCaptcha()
width,height,char_num,characters,classes = captcha.get_parameter()
gray_image = Image.open(sys.argv[1]).convert('L')
img = np.array(gray_image.getdata())
test_x = np.reshape(img,[height,width,1])/255.0
x = tf.placeholder(tf.float32, [None, height,width,1])
keep_prob = tf.placeholder(tf.float32)
model = captcha_model.captchaModel(width,height,char_num,classes)
y_conv = model.create_model(x,keep_prob)
predict = tf.argmax(tf.reshape(y_conv, [-1,char_num, classes]),2)
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.95)
with tf.Session(config=tf.ConfigProto(log_device_placement=False,gpu_options=gpu_options)) as sess:
sess.run(init_op)
saver.restore(sess, "capcha_model.ckpt")
pre_list = sess.run(predict,feed_dict={x: [test_x], keep_prob: 1})
for i in pre_list:
s = ''
for j in i:
s += characters[j]
print(s)
然后执行:
python3 predict_captcha.py captcha/ehm5.jpg

PIL 图像处理
传统机器学习方法:ladingwu/identfying_code_recognize
1. 基于TensorFlow的CAPTCHA注册码识别实验
2. github:tengxing/tensorflow-learn/captcha
3. github:Yuwailaifeng/VerificationCode_CNN
4. 基于TensorFlow识别Captcha库验证码图文教程
5. 深度学习基于TF破解验证码
python2能装tensorflow,不过需要是Linux系统或者Mac系统。
windows只能是python3.5版本安装TensorFlow。
下面是各平台安装TensorFlow的方法。
https://tensorflow.google.cn/install/
参考我的另一篇博文:
ubuntu 安装 tensorflow python2