大家好,今天介绍自然语言处理中经典的隐马尔科夫模型(HMM)。HMM早期在语音识别、分词等序列标注问题中有着广泛的应用。
了解HMM的基础原理以及应用,对于了解NLP处理问题的基本思想和技术发展脉络有很大的好处。本文会详细讲述HMM的基本概念和原理,并详细介绍其在分词中的实际应用。
作者 | 小Dream哥
编辑 | 小Dream哥&言有三
1 马尔科夫随机过程
设随机变量X(t)随时间t(t=t1,t2,t3...tn)而变化,E为其状态空间,若随机变量x满足马尔科夫性,如下:
即X在tn时刻的状态只与其前一时刻时状态的值有关,则称该随机变量的变化过程是马尔科夫随机过程,随机变量满足马尔科夫性。
2 隐马尔科夫模型(HMM)
如图所示为马尔科夫模型的图结构

基于此图结构可知,HMM模型满足如下的性质:
(1) 它基于观测变量来推测未知变量;
(2) 状态序列满足马尔科夫性;
(3) 观测序列变量X在t时刻的状态仅由t时刻隐藏状态yt决定。
同时,隐马尔科夫模型是一种概率图模型,它将学习任务归结于计算变量的概率分布。通过考虑联合概率P(Y,X)来推断Y的分布。
考虑马尔科夫性质以及随机变量Y在t时刻的状态仅由y(t-1)决定,观测序列变量X在t时刻的状态仅由yt决定,有:

从而可以推出联合概率:
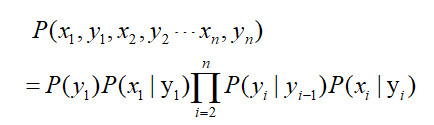
总的来说,马尔科夫模型式利用已知的观测序列来推断未知变量序列的模型。
例如在分词任务中,中文的句子“请问今天的天气怎么样?”就是可以被观测到的序列,而其分词的标记序列就是未知的状态序列“请问/今天/深圳/的/天气/怎么样/?”这种分词方式对应的标记序列为“BEBEBESBEBME”
标记序列:标签方案中通常都使用一些简短的英文字符[串]来编码。
标签列表如下,在分词任务中,通常用BMES标记。
B,即Begin,表示开始
M,即Mediate,表示中间
E,即End,表示结尾
S,即Single,表示单个字符
3 HMM模型的几个重要概率矩阵
仔细分析此联合概率表达式,可知其分为三个部分:

(1) 初始状态概率P(y1)
初始概率矩阵是指序列头的状态分布,以分词为例,就是每个句子开头,标记分别为BMES的概率。
(2) 状态转移概率P(yi|yi-1)
状态转移概率是指状态序列内,两个时刻内不同状态之间转移的状态分布。以分词为例,标记状态总共有BMES四种,因此状态转移概率构成了一个4*4的状态转移矩阵。这个矩阵描述了4种标记之间转化的概率。例如,P(yi=”E”|yi-1=”M”)描述的i-1时刻标为“M”时,i时刻标记为“E”的概率。
(3) 输出观测概率P(xi|yi)
输出观测概率是指由某个隐藏状态输出为某个观测状态的概率。以分词为例,标记状态总共有BMES四种,词表中有N个字,则输出观测概率构成了一个4*N的输出观测概率矩阵。这个矩阵描述了4种标记输出为某个字的概率。例如,P(Xi=”深”|yi=”B”)描述的是i时刻标记为“B”时,i时刻观测到到字为“深”的概率。
4 HMM在分词应用中的实战
经过上面的讲述,各位读者可能还是会对HMM有一种似懂非懂的感觉。所以这一节中介绍其在分词应用中的实践,通过完整实际的思路介绍和代码讲解,相信各位读者能够对HMM模型有一个准确的认识。
假设有词序列Y = y1y2....yn,HMM分词的任务就是根据序列Y进行推断,得到其标记序列X= x1x2....xn,也就是计算这一个概率:

根据贝叶斯公式:

当语料确定时

可以认为是常数,所以只需计算
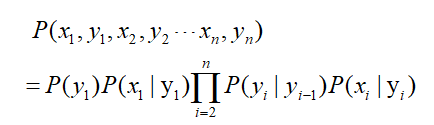
这样的话,就是要计算3小节的那三个概率矩阵,当获得上述三个矩阵之后,便可以根据维特比算法计算出一个词序列对应概率最大的分词标记序列,就此也就完成了分词的任务。那我们就还剩下2个任务:
4.1 根据语料计算三个概率矩阵
当获得了分好词的语料之后,三个概率可以通过如下方式获得:
(1) 初始状态概率P(y1)
统计每个句子开头,序列标记分别为B,S的个数,最后除以总句子的个数,即得到了初始概率矩阵。
(2) 状态转移概率P(yi|yi-1)
根据语料,统计不同序列状态之间转化的个数,例如count(yi=”E”|yi-1=”M”)为语料中i-1时刻标为“M”时,i时刻标记为“E”出现的次数。得到一个4*4的矩阵,再将矩阵的每个元素除以语料中该标记字的个数,得到状态转移概率矩阵。
(3) 输出观测概率P(xi|yi)
根据语料,统计由某个隐藏状态输出为某个观测状态的个数,例如count(xi=”深”|yi=”B”)为i时刻标记为“B”时,i时刻观测到字为“深”的次数。得到一个4*N的矩阵,再将矩阵的每个元素除以语料中该标记的个数,得到输出观测概率矩阵。
我们看一下该部分的代码:
Pi = {k: v*1.0/line_num for k,v in Pi_dict.items()}
A = {k: { k1: v1/ Count_dict[k] for k1, v1 in v.items()}
for k, v in A_dict.items()
}
B= {k: { k1: v1/ Count_dict[k] for k1, v1 in v.items()}
for k,v in B_dict.items()
}
line_num为预料中句子的个数;
Pi_dic记录了语料中句子中开头标记的个数。
Count_dict记录了预料中“BMES”四个标记的个数;
A_dict记录了不同序列状态之间转化的个数;
B_dict记录了不同隐藏状态输出为某个观测状态的个数。
4.2 维特比算法
训练结束之后,便可获得三个概率矩阵,那么该如何利用上述矩阵,获得一个句子的最大概率分词标记序列,即完成分词任务呢?下面就是我们要介绍的维特比算法。
设Q是所有可能状态的集合Q={q1,q2,....qN},V={v1,v2,...vM}是所有可能的观测集的集合。其中N是可能的状态数(例如标记个数4:“BMES”),M是可能的观测状态数(例如字典中字的个数)。
一个隐马尔可夫模型由一个三元组(Pi,A,B)确定,I是长度为T的状态序列,O是对应的观测序列,先用数学符号表示上述的三个概率矩阵:
初始概率矩阵,表示序列开头,序列状态为yi的概率
状态转移矩阵,表示序列状态由yi转为yj的概率
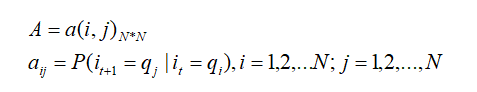
输出状态矩阵,表示序列状态为yi时,输出字为xj的概率

进而,为了叙述方便,引入两个变量:
定义时刻t状态为i的所有单个路径(i1,i2,i3,...,it)中概率最大值为,简单记为delta(i):

由其定义可得其递推公式:

下为时刻t状态为i的所有单个路径中,概率最大的路径的第t-1个节点,简单记为kethe(i):

先阐述一下维特比算法的基本流程:
(1) 计算初始转态概率

通过上述公式,得到t=1时刻,隐藏状态取各个值(BMES)时的概率。
(2) 逐渐递推到t=2,3,4.....T
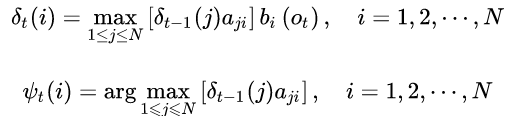
通过上述公式,分别得到各个时刻,隐藏状态取各个值时的概率最大的路径以及其前一时刻节点状态
(3) 终止

选取T时刻中,取值最大的那个状态为T时刻的状态。
(4) 回溯最优路径

根据前面计算的结果,反推得到各个时刻隐藏状态的取值
可能还有同学对这个过程不是很理解,我们举分词的例子,详细介绍一下这个过程。
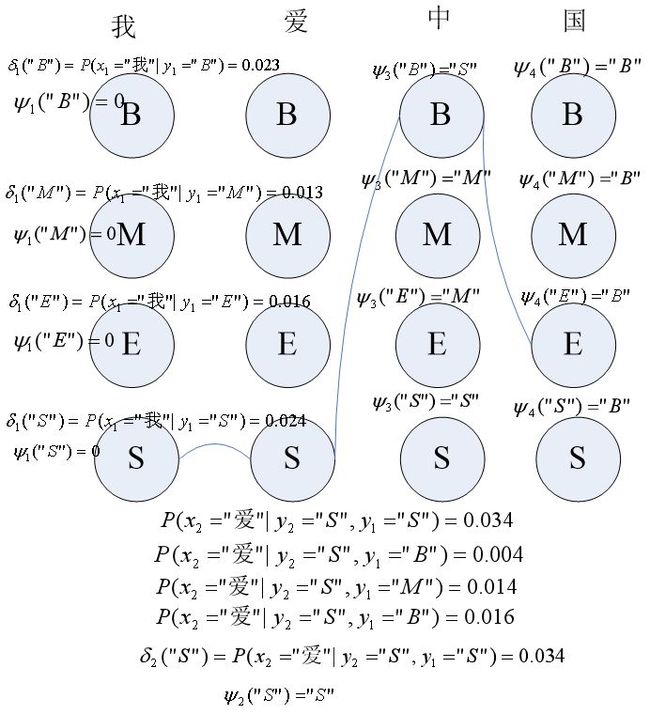
维特比算法是计算一个概率最大的路径,如图要计算“我爱中国”的分词序列:
第一个词为“我”,通过初始概率矩阵和输出观测概率矩阵分别计算delta1("B")=P(y1=”S”)P(x1=”我”|y1=”S”),delta1("M")=P(y1=”B”)P(x1=”我”|y1=”B”),delta1("E")=P(y1=”M”)P(x1=”我”|y1=”M”),delta1("S")=P(y1=”E”)P(x1=”我”|y1=”E”),
并设kethe1("B")=kethe1("M")=kethe1("E")=kethe1("S")=0;
同理利用公式分别计算:
delta2("B"),delta2("M"),delta2("E"),delta2("S")。图中列出了delta2("S")的计算过程,就是计算:
P(y2=”S”|y1=”B”)P(x2=”爱”|y2=”S”)
P(y2=”S”|y1=”M”)P(x2=”爱”|y2=”S”)
P(y2=”S”|y1=”E”)P(x2=”爱”|y2=”S”)
P(y2=”S”|y1=”S”)P(x2=”爱”|y2=”S”)
其中P(y2=”S”|y1=”S”)P(x2=”爱”|y2=”S”)的值最大,为0.034,因此delta2("S"),kethe2("S")="S",同理,可以计算出delta2("B"),delta2("M"),delta2("E")及kethe2("B"),kethe2("M"),kethe2("E")。
同理可以获得第三个和第四个序列标记的delta和kethe。
到最后一个序列,delta4("B"),delta4("M"),delta4("E"),delta4("S")中delta4("S")的值最大,因此,最后一个状态为”S”。
最后,回退,
i3 = kethe4("S") ="B"
i2 =kethe3("B") = "S"
i1 = kethe2("S") ="S"
求得序列标记为:“SSBE”。
总结
HMM的基本原理和其在分词中的应用就讲到这里了,从上述分析可以看出,HMM时非常适合用于序列标注问题的。但是HMM模型引入了马尔科夫假设,即T时刻的状态仅仅与前一时刻的状态相关。但是,语言往往是前后文相互照应的,所以HMM可能会有它的局限和问题,读者可以思考一下,如何解决这个问题。
下期预告:条件随机场(CRF)原理与应用
如果想加入我们,后台留言吧
转载文章请后台联系
侵权必究
技术交流请移步知识星球
更多请关注知乎专栏《有三AI学院》和公众号《有三AI》