零基础Ubuntu16.04+Hadoop2.7.3+Spark2.3.4+Zookeeper3.4.14+HBase2.1.6+Kafka2.11大数据集群配置教程
半年后重新整理了大数据集群搭建方案,优化了部分步骤与目录设计
目录
1、环境搭建
虚拟机:
系统:
节点:
2、相关软件版本
3、主要参考文章
4、搭建步骤
4.1 安装虚拟机
4.2 修改hostname与hosts文件
4.3 创建hadoop用户与hadoop用户
4.4 配置虚拟机网络,使虚拟机系统之间以及和host主机之间可以通过相互ping通
4.5 配置Java
4.6 配置ssh
4.6.1 安装ssh
4.6.2 验证ssh是否成功安装输入
4.6.3 生成秘钥对
4.6.7 完成之后,在master上执行下面操作,检查免密码登录是否成功。
4.7 创建大数据集群相关目录
4.8 配置hadoop
4.8.1 直接通过wget命令安在线下载
4.8.2 解包移动
4.8.3 新建文件夹
4.8.4 配置文件(所有配置文件都在/home/bigdata/app/hadoop/etc/hadoop目录中)
4.8.5 把hadoop目录分发到子节点服务器
4.8.6 配置环境变量
4.8.7 启动hadoop
4.8.8 查看hadoop是否完全启动
4.8.9 测试hadoop是否配置完成
4.9 配置Scala
4.9.1 安装Scala
4.9.2 查看Scala版本
4.9.3 查看Scala路径
4.10 配置spark
4.10.1 下载Spark 2.3.4
4.10.2 解包移动
4.10.3 修改配置文件
4.10.4 将spark目录分发到子节点服务器
4.10.5 修改环境变量
4.10.6 启动Spark
4.10.7 测试Spark是否配置成功
4.11 配置Zookeeper
4.11.1 下载Zookeeper
4.11.2 解包移动
4.11.3 修改配置文件
4.11.4 修改环境变量
4.11.5 修改权限
4.11.6 单机版Zookeeper功能测试
4.11.7 Zookeeper集群部署
4.11.8 测试Zookeeper集群
4.12 配置HBase
4.12.1 下载HBase
4.12.2 解包移动
4.12.3 修改配置文件
4.12.4 将hbase目录分发到子节点服务器
4.12.5 修改环境变量
4.12.6 测试HBase
4.13 配置Kafka
4.13.1 下载Kafka
4.13.2 解包移动
4.13.3 修改配置文件server.properties
4.13.4 将kafka目录分发到子节点服务器
4.13.5 修改环境变量
4.13.6 Kafka启停命令
4.13.7 测试Kafka
1、环境搭建
虚拟机:
VMware Worstation 15 (https://www.baidu.com/link?url=lUpoe9j2Gpnpg6pKsyG2saoSRYNZQuJHCEd8IozSFG8eiaf323AtDxMK1VCsFXVFQmWwOj6GLpVKq9yJLfXKwEKwzqP8kSv0svFCqiTwWPm&wd=&eqid=cbcfe22f00000b54000000025c9ed9a8)
系统:
Ubuntu-16.04.6-server-amd64(http://releases.ubuntu.com/)
节点:
Master:192.168.115.135
Slave1:192.168.115.136
Slave2:192.168.115.137
2、相关软件版本
可以在清华镜像源进行下载(https://mirrors.tuna.tsinghua.edu.cn/),由于清华镜像源的相关软件版本会根据软件更新而同步更新,因此看到这份教程的你可能已经找不到我使用的版本了,但是如果版本差别只有最后一位不一样的话,安装步骤可以一样,一般不会出问题。
Hadoop:hadoop-2.7.3
Spark:spark-2.3.4-bin-hadoop2.7
Zookeeper:zookeeper-3.4.14.tar
HBase:hbase-2.1.6-bin
Kafka:kafka_2.11-2.1.1
Java:java(1.8.0_191)
Scala:scala 2.11.6
3、主要参考文章
-
Hadoop2.7.3完全分布式集群搭建和测试(如果一切再重来)
-
The authenticity of host 'localhost (127.0.0.1)' can't be established的处理方法( stpeace)
-
linux下如何查询jdk的安装路径(stpeace)
-
Vmware虚拟机设置静态IP地址(麦兜日常学习笔记)
-
在Ubuntu下搭建Spark群集
-
ZooKeeper安装和配置
-
hadoop-2.7.3安装kafka_2.11-2.1.0
-
Zookeeper3.4+Hadoop2.7+Spark2.3.1+kafka+Redis+Tensorflow服务器配置说明
4、搭建步骤
4.1 安装虚拟机
为了给每个节点配置静态ip地址,安装ubuntu系统前需要先安装Vmware Workstation并配置好网络适配器

进入虚拟网络编辑器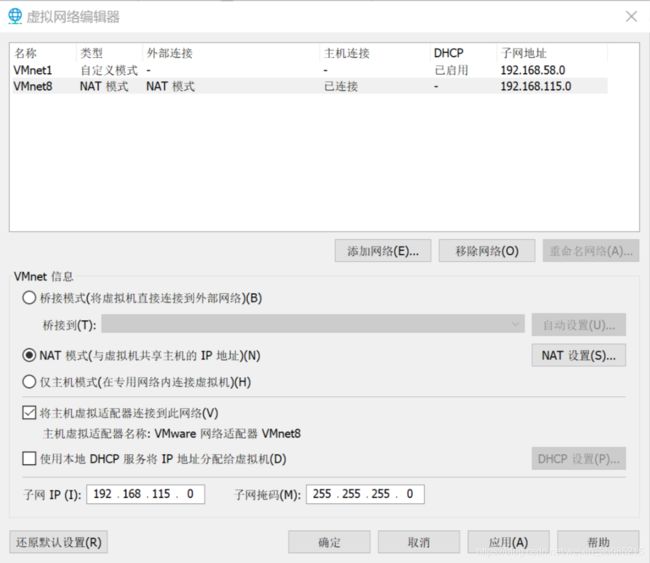
选择NAT模式,勾选“将主机虚拟适配器链接到此网络”,取消“使用本地DHCP服务将IP地址分配给虚拟机”,同时在该页面可以看到子网ip和子网掩码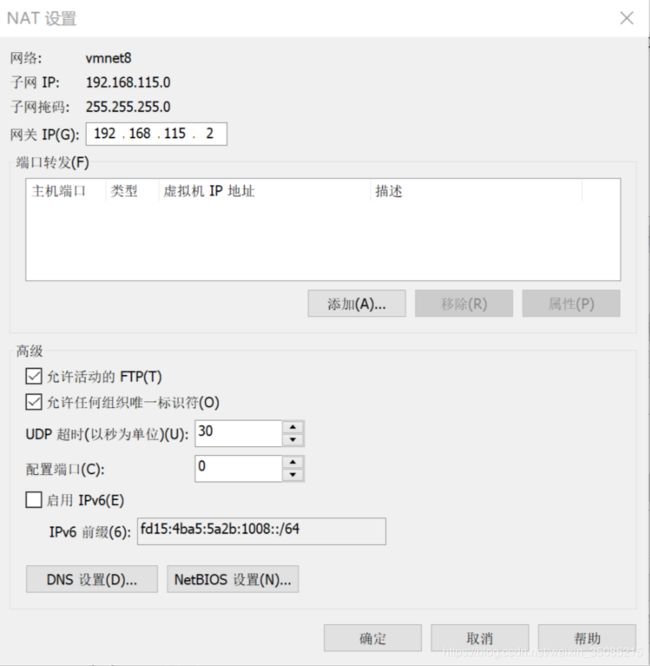
点击NAT设置,可以看到网关IP,一般不做修改
下面这一步很重要,影响到能否使用主机web访问虚拟机端口
检查宿主机VM8 网卡设置,打开网络和共享中心→ 更改适配器设置→,在VMware Network Adapter VMnet8上单击右键,选择属性按钮打开属性对话框。
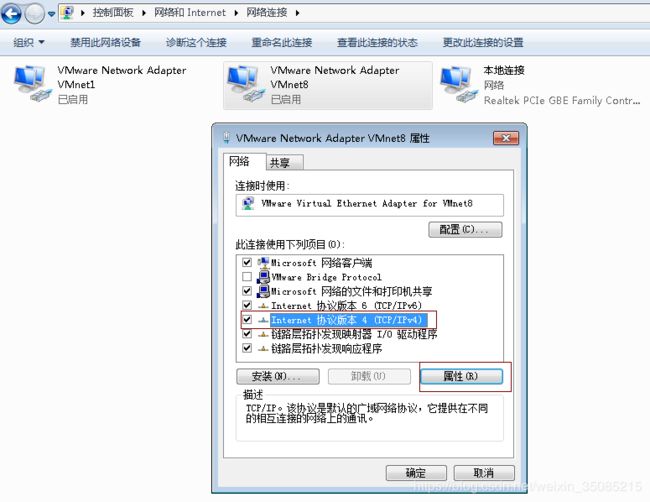
安装三个系统(master、slave1、slave2)以master为例,slave安装方法相同
新建虚拟机,选择提前下载好的ubuntu-16.04.6-server-amd64进行安装,命名为master,为了方便,密码都设为123456.
之后选项可以直接点下一步,直至完成,也可以根据硬盘容量更换存储地址。
系统开始正式安装,由于是静态配置ip地址,会进入如下界面: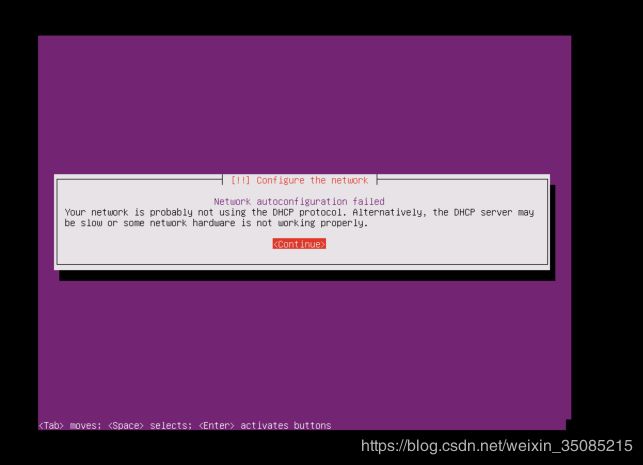
按回车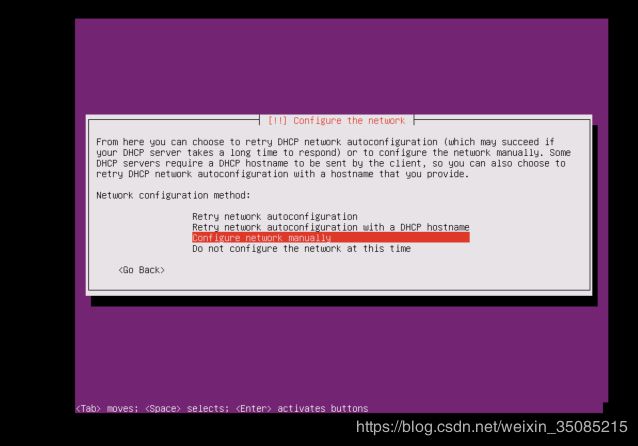
选第三项
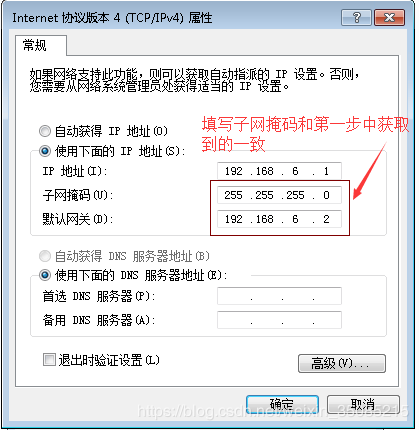
输入要设置的ip地址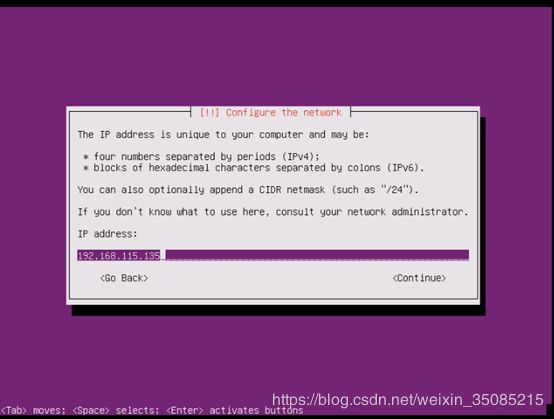
输入子网掩码(在虚拟网络编辑器可以查看)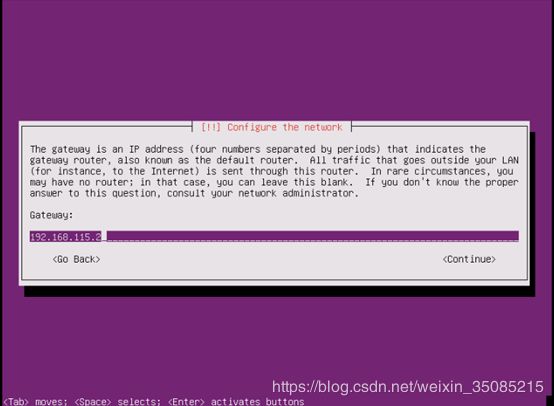
输入网关(在虚拟网络编辑器可以查看)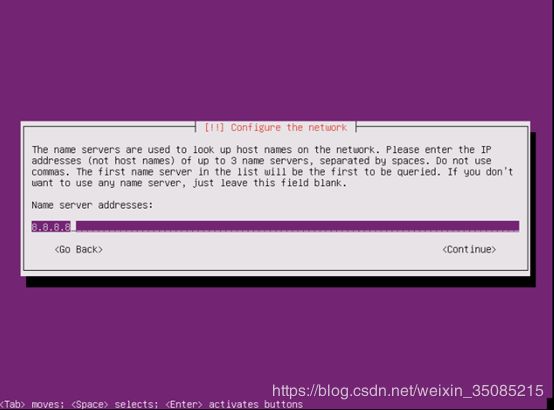
DNS可以设置成8.8.8.8
4.2 修改hostname与hosts文件
三条机器都需要修改,以master上机器为例,打开终端
可以先查看一下目前的ip是不是自己设置的那样
~$ ifconfig #查看ip信息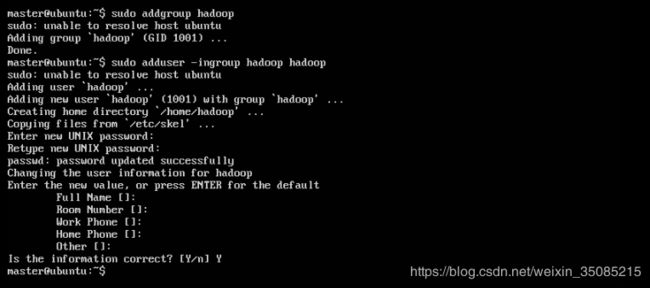
执行如下的操作
把hostname修改成master:
~$ sudo vi /etc/hostname #打开hostname
将ubuntu改成master

把hosts修改成如下所示的样子:
~$ sudo vi /etc/hosts #打开hosts文件
同样地,在slave1和slave2机器上做相似的操作,分别更改主机名为slave1和slave2,然后把hosts文件更改和master一样。
4.3 创建hadoop用户与hadoop用户
# 创建hadoop组
~$ sudo addgroup hadoop
# 在hadoop组创建hadoop用户
~$ sudo adduser -ingroup hadoop hadoop
# 给hadoop用户添加权限
~$ sudo vi /etc/sudoers #打开sudoers文件在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,给hadoop用户赋予root用户同样的权限(这里一般会遇到即使用sudo命令打开依然没有修改权限的情况,用<:wq!>指令强制写入然后关闭)
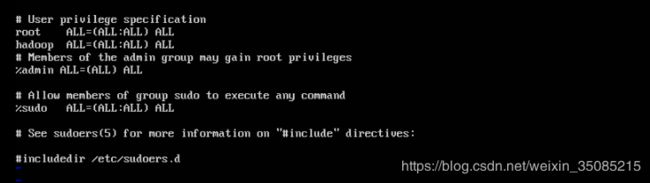
接下来各台主机都用hadoop账户登录进行操作( su + <主机名> )
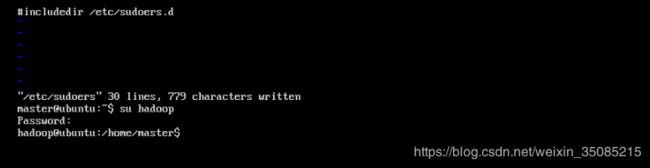
4.4 配置虚拟机网络,使虚拟机系统之间以及和host主机之间可以通过相互ping通
如果前面安装系统的时候已经选择了NAT模式,那么这里只需要使用 ping + <主机名>指令进行测试即可。分别在3台机器上都进行测试,出现以下情况则表示能连通。
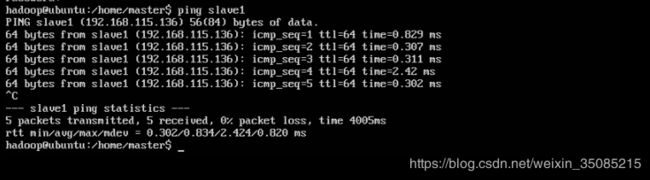
按< Ctrl + C >终止命令,退出连通状态
4.5 配置Java
Java的安装这个不要单独下载jdk文件配置,而直接使用以下三条命令安装:
~$ sudo apt-get update
~$ sudo apt-get install openjdk-8-jdk
~$ java -version #查看java版本,确认是否安装成功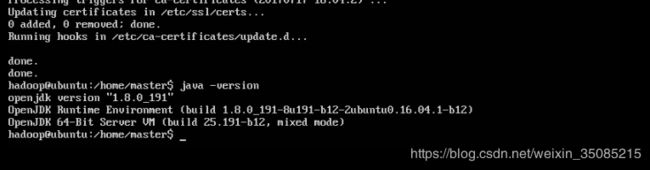
配置ssh前建议先将之前调试好的三个系统进行备份,后面的步骤容易出错!!!
4.6 配置ssh
以下步骤三个系统都要做
4.6.1 安装ssh
~$ sudo apt-get install openssh-server已有ssh或者安装成功了的输入命令
~$ ps -e | grep ssh4.6.2 验证ssh是否成功安装输入
~$ ssh localhost如果出现以下提示说明安装成功

但是笔者一般会遇到以下提示
The authenticity of host 'localhost ( : :1)' can't be established.
看似输完yes后能够输密码登录,实则会对后期产生影响

解决方案如下:
~$ hadoop@ubuntu:/home/master$ cd ~/.ssh
# 进入 .ssh 文件夹
~$ hadoop@ubuntu:~/.ssh$ sudo chmod 777 /etc/ssh/ssh_config
# 修改ssh_config文件权限
~$ hadoop@ubuntu:~/.ssh$ vi /etc/ssh/ssh_config
# 打开ssh_config文件在ssh_config文件最后加上以下两行内容:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null

再次输入
没有初出现The authenticity of host 'localhost ( : :1)' can't be established. 说明问题已解决。

4.6.3 生成秘钥对
~$ ssh-keygen -t rsa #命令前不要加sudo!! # 输入之后一直选择enter即可。生成的秘钥位于 ~/.ssh文件夹下。可用cd 命令进入查看。

4.6.4 导入authorized_keys
~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys这样,

4.6.5 把master上的authorized_keys拷贝到其他主机的相应目录下,实现远程无密码登录
~$ cd ~/.ssh #进 入master的.ssh目录,执行复制操作
~/.ssh$ scp authorized_keys hadoop@slave1:~/.ssh/
~/.ssh$ scp authorized_keys hadoop@slave2:~/.ssh/
4.6.6 修改各台主机上authorized_keys文件的权限
所有机器上,均执行命令:
~$ chmod 600 ~/.ssh/authorized_keys4.6.7 完成之后,在master上执行下面操作,检查免密码登录是否成功。
~$ ssh slave1
~$ ssh slave2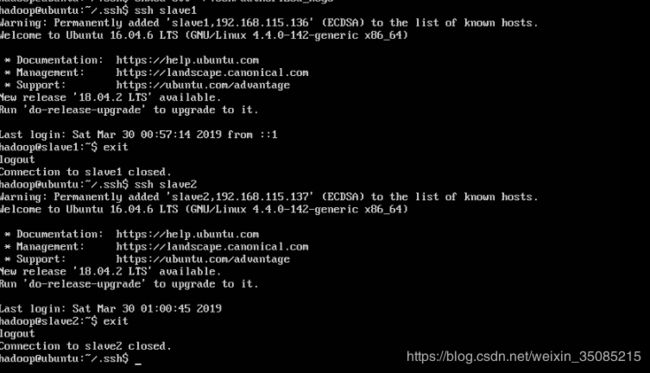
至此,ssh配置完成,可以保存备份一下。
4.7 创建大数据集群相关目录
在所有服务器系统下的home目录下创建bigdata目录,并在其中创建app、data、lib、software和source目录。
~$ sudo mkdir -p /home/bigdata #所有大数据相关内容配置在bigdata目录下
~$ sudo mkdir -p /home/bigdata/app #app目录下存放所有软件的安装目录
~$ sudo mkdir -p /home/bigdata/data #data目录存放测试数据
~$ sudo mkdir -p /home/bigdata/lib #lib目录存放开发的jar包
~$ sudo mkdir -p /home/bigdata/software #software目录存放软件安装包
~$ sudo mkdir -p /home/bigdata/source #source目录存放框架源码4.8 配置hadoop
4.8.1 直接通过wget命令安在线下载
进入/home/bigdata/software目录,使用wget命令从清华镜像源下载(下载路径会因版本变动而无法使用,最好在自己windows环境上用浏览器上先看一下路径是否可以使用,不能使用的话,根据路径去清华镜像源上找到相应的最新版本的下载路径)
~$ cd /home/bigdata/software #进入/home/bigdata/software目录
/home/bigdata/software$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
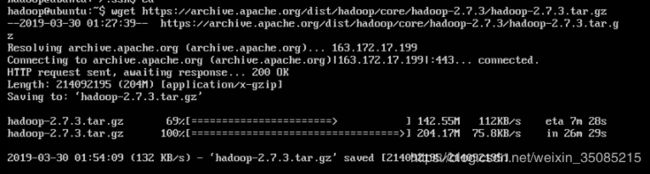
4.8.2 解包移动
# 解压Hadoop包到当前目录
/home/bigdata/software$ tar -zxvf hadoop-2.7.3.tar.gz # 解压hadoop-2.7.3.tar.gz文件
# 将解压后的hadoop-2.7.3目录重命名后移到/home/bigdata/app目录下
/home/bigdata/software$ sudo mv hadoop-2.7.3 /home/bigdata/app/hadoop
4.8.3 新建文件夹
# 在/home/bigdata/app/hadoop目录下新建如下目录
/home/bigdata/software$ cd /home/bigdata/app/hadoop # 切换到/home/bigdata/app/hadoop作为当前目录
/home/bigdata/app/hadoop$ mkdir tmp # 新建tmp目录由于dfs目录创建在data目录下而不是hadoop目录下,无法在之后同hadoop目录一起分发,所以以下步骤每个服务器都需要进行,不然在子节点找不到dfs目录(也可创建完后单独分发dfs目录)
# 在/home/bigdata/data目录下新建如下目录
/home/bigdata/app/hadoop$ cd /home/bigdata/data # 切换到/home/bigdata/data作为当前目录
/home/bigdata/data$ sudo mkdir -p dfs # 新建dfs目录
/home/bigdata/data$ sudo mkdir -p dfs/name # 在dfs文件夹下新建name目录
/home/bigdata/data$ sudo mkdir -p dfs/data # 在dfs文件夹下新建data目录
修改dfs目录权限,并复制到子节点上
/home/bigdata/data$ sudo chmod -R 777 dfs # 修改dfs目录权限
4.8.4 配置文件(所有配置文件都在/home/bigdata/app/hadoop/etc/hadoop目录中)
由于前面java环境安装使用通过apt-get install openjdk-8-jdk,因此这里的JAVA_HOME环境变量值可以通过以下命令获得:
~$ ls -l /etc/alternatives/java # 获取java路径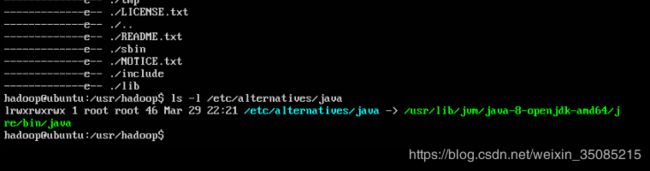
4.8.4.1 配置文件:hadoop-env.sh
修改JAVA_HOME值(改为export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64)
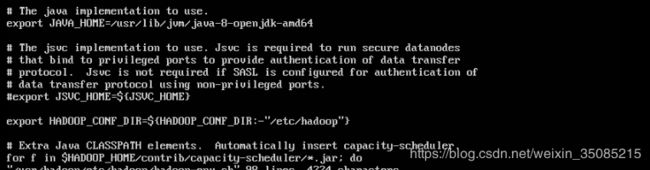
4.8.4.2 配置文件:yarn-env.sh
修改JAVA_HOME值(改为export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64)

4.8.4.3 配置文件:slaves
将内容修改为:
slave1
slave2
4.8.4.4 配置文件:core-site.xml
fs.defaultFS
hdfs://master:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/home/bigdata/app/hadoop/tmp # 4.8.3中创建的目录
Abase for other temporary directories.
ha.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
4.8.4.5 配置文件:hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.http.address
master:50070
dfs.namenode.name.dir
file:/home/bigdata/data/dfs/name # 4.8.3中创建的目录
dfs.datanode.data.dir
file:/home/bigdata/data/dfs/data # 4.8.3中创建的目录
dfs.replication
2
dfs.webhdfs.enabled
true
4.8.4.6 配置文件:yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
4.8.4.7 配置文件:mapred-site.xml
先根据文件 mapred-site.xml.template 创建文件 mapred-site.xml
/home/bigdata/app/hadoop/etc/hadoop/$ cp mapred-site.xml.template mapred-site.xml然后修改 mapred-site.xml 文件
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
4.8.5 把hadoop目录分发到子节点服务器
# 将hadoop目录传输到子节点的/home/bigdata/app目录下。
~$ scp -r /home/bigdata/app/hadoop hadoop@slave1:/home/bigdata/app
~$ scp -r /home/bigdata/app/hadoop hadoop@slave2:/home/bigdata/app(如果传输时报错说 :权限拒绝,先把文件传送到非/usr目录下,然后在node上把这个文件再移动到/usr/hadoop)
如笔者正是将hadoop先传输到了子节点的/tmp目录下
~$ scp -r /usr/hadoop hadoop@slave1:/tmp
~$ scp -r /usr/hadoop hadoop@slave2:/tmp
# 然后,再分别从slave1和slave2上,将hadoop文件夹分别放到各自的/home/bigdata/app目录中
# 在slave1机器:
~$ sudo mv /tmp/hadoop /home/bigdata/app
# 在slave2机器:
~$ sudo mv /tmp/hadoop /home/bigdata/app然后,分别在各个节点上修改/home/bigdata/app/hadoop目录权限。
~$ sudo chmod -R 777 /home/bigdata/app/hadoop在分发到子节点前若已经修改了hadoop目录的权限,则分发后子节点上的hadoop目录权限已经符合需要
4.8.6 配置环境变量
每个子节点都要配置以下一样的环境变量
编辑/etc/profile文件
~$ sudo vi /etc/profile在后边添加以下内容就可以
#hadoop
export HADOOP_HOME=/home/bigdata/app/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin执行< source /etc/profile >使更新的配置生效
配置完成的话可以通过< hadoop version >查看hadoop版本
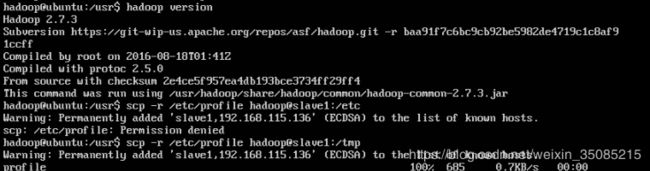
4.8.7 启动hadoop
Hadoop集群的启动只需要在主节点服务器启动即可,进入主节点的/home/bigdata/app/hadoop目录
~$ cd /home/bigdata/app/hadoop第一次启动Hadoop集群需要在主节点对hdfs进行格式化,格式化之前需要确保在4.8.5中对/home/bigdata/app/hadoop目录权限进行修改
# 修改权限
/home/bigdata/app/hadoop$ sudo chmod -R 777 /home/bigdata/app/hadoop
# 格式化
/home/bigdata/app/hadoop$ bin/hdfs namenode -format
# 启动hadoop
/home/bigdata/app/hadoop$ sbin/start-all.sh4.8.8 查看hadoop是否完全启动
# 输入jps查看状态
~$ jps正常情况下应显示如下情况
主节点显示:
NameNode
Jps
ResourceManager
SecondaryNameNode
从节点显示:
Jps
DataNode
NodeManager

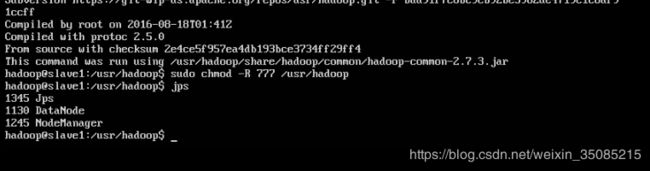

4.8.9 测试hadoop是否配置完成
4.8.9.1 启动hadoop
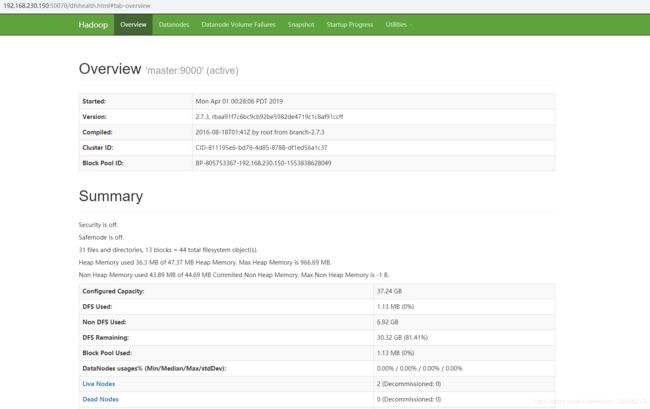
~$ /home/bigdata/app/hadoop/sbin/start-all.sh4.8.9.2 检查能否通过浏览器访问webapp
hdfs管理界面 192.168.230.150:50070
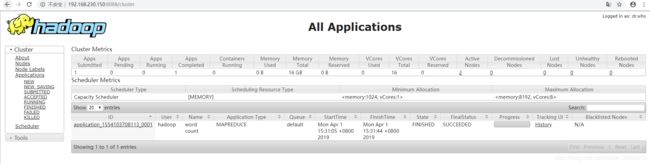
yarn管理界面 192.168.230.150:8088
4.8.9.3 hadoop测试——wordcount
~$ cd /home/bigdata/app/hadoop # 进入本地hadoop目录
/home/bigdata/app/hadoop$ bin/hdfs dfs -mkdir -p /data/input # 在hdfs上创建一个测试目录/data/input
/home/bigdata/app/hadoop$ bin/hdfs dfs -put README.txt /data/input # 将当前目录下的README.txt 文件复制到hdfs中
/usr/hadoop$ bin/hdfs dfs-ls /data/input # 查看文件系统中是否存在我们所复制的文件
# 运行如下命令向hadoop提交单词统计任务
/home/bigdata/app/hadoop$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /data/input /data/output/result
# 查看result,结果在result下面的part-r-00000中
/home/bigdata/app/hadoop$ bin/hdfs dfs -cat /data/output/result/part-r-00000
4.9 配置Scala
4.9.1 安装Scala
~$ sudo apt-get install scala4.9.2 查看Scala版本
~$ scala -version![]()
4.9.3 查看Scala路径
由于前面java环境安装使用通过apt-get install scala,因此scala的路径可以通过以下命令获得:
# 获取scala路径
~$ ls -l /etc/alternatives/scala ![]()
4.10 配置spark
4.10.1 下载Spark 2.3.4
~$ cd /home/bigdata/software #进入/home/bigdata/software目录
/home/bigdata/software$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.4/spark-2.3.4-bin-hadoop2.7.tgz
4.10.2 解包移动
解压Spark包到当前目录
/home/bigdata/software$ tar -zxvf spark-2.3.4-bin-hadoop2.7.tgz将解压后的spark-2.3.4-bin-hadoop2.7目录重名后移到/home/bigdata/app目录下
/home/bigdata/software$ sudo mv spark-2.3.4-bin-hadoop2.7 /home/bigdata/app/spark
4.10.3 修改配置文件
所有配置文件都在/home/bigdata/app/spark/conf目录中
4.10.3.1 配置文件:spark-env.sh
先根据文件 spark-env.sh.template 创建文件 spark-env.sh
/home/bigdata/app/spark/conf$ cp spark-env.sh.template spark-env.sh在文件末尾添加以下内容:
export SCALA_HOME=/usr/share/scala-2.11
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/bigdata/app/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_LOCAL_DIRS=/home/bigdata/app/spark
export SPARK_DRIVER_MEMORY=1G
export LD_LIBRARY_PATH=/home/bigdata/app/hadoop/lib/native/:$LD_LIBRA
RY_PATH
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000/history"4.10.3.2 配置文件:spark-defaults.conf
先根据文件 spark-defaults.conf.template 创建文件 spark-defaults.conf
/home/bigdata/app/spark/conf$ cp spark-defaults.conf.template spark-defaults.conf添加以下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/history
spark.eventLog.compress true创建history的目录(需要在hadoop启动时执行以下命令)
hdfs dfs -mkdir -p /history4.10.3.3 配置文件:slaves
先根据文件 slaves.template 创建文件 slaves
/home/bigdata/app/spark/conf$ cp slaves.template slaves将内容修改为:
slave1
slave24.10.4 将spark目录分发到子节点服务器
将spark目录传输到子节点的/home/bigdata/app目录下
~$ scp -r /home/bigdata/app/spark hadoop@slave1:/home/bigdata/app
~$ scp -r /home/bigdata/app/spark hadoop@slave2:/home/bigdata/app然后,分别在各个节点上修改/home/bigdata/app/spark目录权限
~$ sudo chmod -R 777 /home/bigdata/app/spark4.10.5 修改环境变量
每个子节点都要配置以下一样的环境变量
~$ sudo vi /etc/profile # 打开/etc/profile文件在后边添加以下内容就可以
#spark
export SPARK_HOME=/home/bigdata/app/spark
export PATH=$PATH:$SPARK_ HOME/sbin
export PATH=$PATH:$SPARK_ HOME/bin执行< source /etc/profile >使更新的配置生效
4.10.6 启动Spark
启动Spark前要先启动Hadoop
~$ cd /home/bigdata/app/hadoop #进入Hadoop安装目录
/home/bigdata/app/hadoop$ sbin/start-all.sh #启动Hadoop
/home/bigdata/app/hadoop$ cd /home/bigdata/app/spark #进入Spark安装目录
/home/bigdata/app/spark$ sbin/start-all.sh #启动Spark
/home/bigdata/app/spark$ start-history-server.sh #启动history server运行jps看看Java进程,发现比Hadoop启动的时候多了Master进程。

切换到slave01节点上,运行JPS,看看进程,这里比Hadoop的时候多了一个Worker进程。说明我们的Spark群集已经启动成功。
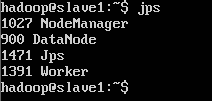
4.10.7 测试Spark是否配置成功
启动Spark集群后可以通过如下功能的测试监测Spark集群是否配置成功。
4.10.7.1 检查能否浏览器访问webapp
spark管理界面 192.168.230.150:8080

4.10.7.2 检查能否进入shell模式
使用< spark-shell >命令进入shell模式,可以看到Spark版本。
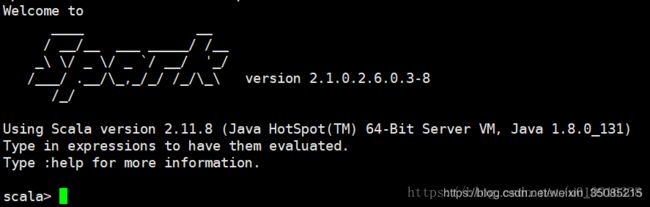
4.11 配置Zookeeper
先配置单机版Zookeeper
4.11.1 下载Zookeeper
进入/home/bigdata/software目录,直接通过以下命令下载zookeeper-3.4.14.tar.gz文件
/home/bigdata/software$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
4.11.2 解包移动
解压Zookeeper包到当前目录
/home/bigdata/software$ tar -zxvf zookeeper-3.4.14.tar.gz将解压后的zookeeper-3.4.14目录重名后移到/home/bigdata/app目录下
home/bigdata/software$ sudo mv zookeeper-3.4.14 /home/bigdata/app/zookeeper4.11.3 修改配置文件
新建3个日志文件夹
~$ sudo mkdir -p /home/bigdata/app/zookeeper/data
~$ sudo mkdir -p /home/bigdata/app/zookeeper/datalogs
~$ sudo mkdir -p /home/bigdata/app/zookeeper/logs4.11.3.1 配置文件:zoo.cfg
Zoo.cfg文件在/home/bigdata/app/zookeeper/conf目录中
先根据文件 zoo_sample.cfg 创建文件 zoo.cfg
~$ cd /home/bigdata/app/zookeeper/conf
/home/bigdata/app/zookeeper/conf$ cp zoo_sample.cfg zoo.cfg在zoo.cfg文件中添加以下内容(若已有该参数,直接在原有参数上修改即可)
tickTime=2000
dataDir=/home/bigdata/app/zookeeper/data
dataLogDir=/home/bigdata/app/zookeeper/datalogs
clientPort=2181
autopurge.snapRetainCount=10
autopurge.purgeInterval=48
配置参数解释:
ClientPort:zookeeper服务器监听的端口,客户端通过该端口建立连接,每台zk服务器也允许设置为不同的值。默认配置文件设定的是2181,无特殊情况不需要修改。
dataDir:zookeeper用于保存内存数据库的快照的目录,除非设置了dataLogDir,否则这个目录也用来保存更新数据库的事务日志。在生产环境使用的zookeeper集群,强烈建议设置dataLogDir,让dataDir只存放快照,因为写快照的开销很低,这样dataDir就可以和其他日志目录的挂载点放在一起。
DataLogDir: zookeeper的事务日志路径。
tickTime:前面已提到过,zookeeper使用的基本时间单位是tick,这个参数用于配置一个tick的长度,单位为毫秒,默认配置文件设定的是3000,除非你有什么难言之隐否则不需要修改。
autopurge.snapRetainCount:3.4.0及之后版本zookeeper提供了自动清理快照文件和事务日志文件的功能,该参数指定了保留文件的个数,默认为3,这里我设置为10。
autopurge.purgeInterval:和上一个参数配合使用,设置自动清理的频率,单位为小时,默认为0表示不清理,建议设为6或12之类的值。这里我设置了48,意思是48小时自动清理一次。
4.11.3.2 配置文件:log4j.properties
log4j.properties在/home/bigdata/app/zookeeper/conf目录中
将以下配置:
zookeeper.root.logger=INFO, CONSOLE
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender修改为:
zookeeper.root.logger=INFO, ROLLINGFILE
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender以下两条注释掉,DailyRollingFileAppender这个类不带属性maxBackupIndex, maxFileSize的,它是按日期来保存日志的,所以不需要设置该2个属性
log4j.appender. ROLLINGFILE.MaxFileSize=500KB
log4j.appender. ROLLINGFILE.MaxBackupIndex=104.11.3.3 配置文件:zkEnv.sh
zkEnv.sh在/home/bigdata/app/zookeeper/bin目录中
将以下配置:
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="."
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,CONSOLE"
fi修改为:
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/home/bigdata/app/zookeeper/logs "
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
Fi4.11.4 修改环境变量
在master服务器添加Zookeeper的环境变量
打开profile文件
~$ sudo vi /etc/profile在后边添加以下内容就可以
# zookeeper
export ZOOKEEPER_HOME=/home/bigdata/app/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin执行< source /etc/profile >使更新的配置生效
4.11.5 修改权限
sudo chmod -R 777 /home/bigdata/app/zookeeper4.11.6 单机版Zookeeper功能测试
启动Zookeeper
~$ zkServer.sh start 输入jps查看进程,可以看到进程中多了QuorumPeerMain这一条,说明Zookeeper已经配置完成了。
~$ zkServer.sh status # 查看当前Zookeeper状态
~$ zkServer.sh stop # 退出zookeeper
~$ zkServer.sh restart # 重启zookeeper4.11.7 Zookeeper集群部署
4.11.7.1 修改zoo.cfg文件
在zoo.cfg文件中添加以下内容:
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:38884.11.7.2 创建myid文件 (在/home/software/app/zookeeper/data目录下)
在/home/software/app/zookeeper/data目录下创建myid文件
~$ touch myid 创建myid文件
~$ vi myid 编辑myid文件myid文件内容对应 zoo.cfg配置的。如master这个服务器对应 server.1 那么myid内容为1
4.11.7.3 将zookeeper目录分发到子节点服务器
将zookeeper传输到子节点的/home/bigdata/app目录
~$ scp -r /home/bigdata/app/zookeeper hadoop@slave1:/home/bigdata/app
~$ scp -r /home/bigdata/app/zookeeper hadoop@slave2:/home/bigdata/app然后,分别在子节点上修改/home/bigdata/app/zookeeper目录权限
在slave机器上:
~$ sudo chmod -R 777 /home/bigdata/app/zookeeper分别修改每台服务器的myid,参考4.11.7.2节
在每台服务器上修改hadoop里的core-site.xml文件,添加以下内容(这一步在配置Hadoop时已经添加,此处对此进行说明)
ha.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
4.11.8 测试Zookeeper集群
在每台机器上打开zookeeper
~$ zkServer.sh start全部开启后检查集群状态,输入jps查看进程,可以看到每me服务器进程中多了QuorumPeerMain这一条。
~$ zkServer.sh status正常启动的集群会看到Mode:follower或Mode:leader
如果发现没有启动成功,可以等一会,在各个服务器上都查看一遍状态,Zookeeper集群的启动需要一些时间,不一定是配置问题。
4.12 配置HBase
4.12.1 下载HBase
进入/home/bigdata/software目录,直接通过以下命令下载hbase-2.1.6-bin.tar.gz文件
~$ cd /home/bigdata/software #进入/home/bigdata/software目录
/home/bigdata/software$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.1.6/hbase-2.1.6-bin.tar.gz
4.12.2 解包移动
解压Hbase包到当前目录
/home/bigdata/software$ tar -zxvf hbase-2.1.6-bin.tar.gz将解压后的hbase-2.1.6目录重名后移到/home/bigdata/app目录下
/home/bigdata/software$ sudo mv hbase-2.1.6 /home/bigdata/app/hbase4.12.3 修改配置文件
配置文件都在/home/bigdata/app/hbase/conf里
4.12.3.1 配置文件:hbase-env.sh
在文件末尾添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64(java的安装路径)
export HBASE_MANAGES_ZK=false4.12.3.2 配置文件:hbase-site.xml
添加以下内容
hbase.rootdir
hdfs://master:9000/home/bigdata/app/hbase/hbase_db
hbase.cluster.distributed
true
hbase.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
4.12.3.3 配置文件:regionservers
指定其他五台子节点的主机名
slave1
slave24.12.3.4 配置文件:backup-masters
在/home/bigdata/app/hbase/conf 目录下用touch命令创建backup-masters文件
/home/bigdata/app/hbase/conf $ touch backup-masters添加要作为备用主节点的主机名
slave14.12.3.5 拷贝hdfs-site.xml和core-site.xml
要把 hadoop 的 hdfs-site.xml 和 core-site.xml 复制到 /home/bigdata/app/hbase/conf 下
~$ cd /home/bigdata/app/hadoop/etc/hadoop
/home/bigdata/app/hadoop/etc/hadoop$ sudo cp hdfs-site.xml /home/bigdata/app/hbase/conf
/home/bigdata/app/hadoop/etc/hadoop$ sudo cp core-site.xml /home/bigdata/app/hbase/conf
4.12.4 将hbase目录分发到子节点服务器
分发之前先删除hbase目录下的docs文件夹
/home/bigdata/app/hbase$ sudo rm -rf docs然后将hbase传输到子节点的/home/bigdata/app目录下
~$ scp -r /home/bigdata/app/hbase hadoop@slave1:/home/bigdata/app
~$ scp -r /home/bigdata/app/hbase hadoop@slave2:/home/bigdata/app然后,分别在所有节点上修改/home/bigdata/app/hbase目录权限
~$ sudo chmod -R 777 /home/bigdata/app/hbase4.12.5 修改环境变量
每个节点都要配置以下一样的环境变量
打开profile文件
~$ sudo vi /etc/profile在后边添加以下内容就可以
# hbase
export HBASE_HOME=/home/bigdata/app/hbase
export PATH=$PATH:$HBASE_HOME/bin执行< source /etc/profile >使更新的配置生效
4.12.6 测试HBase
启动Hbase前先要确保Hadoop已经启动
~$ start-hbase.sh #启动Hbase输入jps查看进程
可以看到主节点的进程中多了HMaster这一条,各从节点都启动HRegionServer进程就是启动成功了。
浏览器里输入<192.168.115.135:16010/master-status>能看到Hbase状态信息(192.168.115.135是master的内网IP)
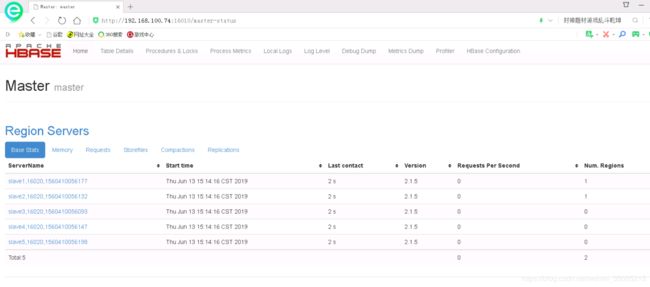
输入
输入
1 active master, 1 backup masters, 5 servers, 0 dead, 0.4000 average load4.13 配置Kafka
4.13.1 下载Kafka
进入/home/bigdata/software目录,通过以下命令下载kafka_2.11-2.1.1.tgz文件
~$ cd /home/bigdata/software #进入/home/bigdata/software目录
/home/bigdata/software$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.1.1/kafka_2.11-2.1.1.tgz
4.13.2 解包移动
解压Kafka包到当前目录
/home/bigdata/software$ tar -zxvf kafka_2.11-2.1.1.tgz将解压后的文件夹移到/home/bigdata/app目录下,并重命名为kafka
/home/bigdata/software$ sudo mv kafka_2.11-2.1.1 /home/bigdata/app/kafka4.13.3 修改配置文件server.properties
文件在 /home/bigdata/app/kafka/config目录中
修改以下四处内容:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1(节点的ID,必须与其它节点不同)
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners=PLAINTEXT://:9092
listeners = PLAINTEXT://master:9092
# A comma separated list of directories under which to store log files
log.dirs=/home/bigdata/app/kafka/logs
# root directory for all kafka znodes.
zookeeper.connect=master:2181,slave1:2181,slave2:2181
4.13.4 将kafka目录分发到子节点服务器
将kafka传输到子节点的/home/bigdata/app目录
~$ scp -r /home/bigdata/app/kafka hadoop@slave1:/home/bigdata/app
~$ scp -r /home/bigdata/app/kafka hadoop@slave2:/home/bigdata/app此时,各个子节点的配置文件仍有两处细节需要修改,与master服务器不一致,以slave1为例:
修改/home/bigdata/app/kafka/config目录下的server.properties文件
~$ vi server.properties修改以下两处
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2 (此处master服务器是1,各个从节点依次为2、3)
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
#listeners=PLAINTEXT://:9092
listeners = PLAINTEXT://slave1:9092 (此处master服务器是master,各个从节点依次为slave1、slave2、)
4.13.5 修改环境变量
修改各个服务器的环境变量
~$ sudo vi /etc/profile在后边添加以下内容就可以
#kafka
export KAFKA_HOME=/home/bigdata/app/kafka
export PATH=$PATH:$KAFKA_HOME/bin执行< source /etc/profile >使更新的配置生效
4.13.6 Kafka启停命令
启动Kafka前需要启动Zookeeper。
Kafka启动命令
~$ kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties #常规模式启动kafka
~$ nohup kafka-server-start.sh $KAFKA_HOME/config/server.properties >/dev/null 2>&1 & #进程守护模式启动kafka
Kafka关闭命令:
~$ kafka-server-stop.sh4.13.7 测试Kafka
在集群的所有服务器上都启动Kafka后,输入jps可以查看到每个服务器的进程中多了一条Kafka的进程,说明该台服务器上的Kafka启动成功。
接下来,可以通过创建一个topic,并建立1个producer发送信息和1个consumer接受信息来测试Kafka的运行状态(生产者与消费者需要分别在2台服务器上开起或在1台服务器上开两个窗口进行操作)。
使用命令如下:
kafka-topics.sh --create -zookeeper master:2181 --replication-factor 1 --partitions 1 --topic topic_name # 创建topic
kafka-console-producer.sh --broker-list master:9092 --topic topic_name # 创建生产者
kafka-console-consumer.sh --bootstrap-server master:9092 --topic topic_name --from-beginning # 创建消费者
在生产者输入的每一条消息,消费者都接收到,说明kafka运行良好。
使用以下命令可以查看Kafka中topic的相关信息:
kafka-topics.sh --list --zookeeper master:2181 # 查看topic列表
kafka-topics.sh --describe --zookeeper master:2181 # 查看全部topic详细信息
kafka-topics.sh --describe --zookeeper master:2181 --topic topic_name # 查看指定topic详细信息
至此hadoop、spark、zookeeper、hbase和kafka集群都已配置完毕。若有网友在使用本教程时发现漏洞,欢迎提出,我及时修改。