机器学习训练建模、集成模型、模型评估等代码总结(2019.05.21更新)
这篇博客总结一些有关机器学习的模型代码与评价指标,力求一针见血,复制粘贴即可食用,hhhhhh,不定期更新
代码中使用的案例是pandas构造的dataframe型的数据,变量名为 dataframe,最终的模型结果交result_model,它差不多长这么样子,也就是通过前面的这么多项特征预测 mask,当然,mask不一定都是0/1,只是以此为例:
| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
|---|---|---|---|---|---|---|---|
| 0 | 871.38 | 806.73 | 1523 | 854 | 782 | 768 | 0 |
| 1 | 875.55 | 807.63 | 1516 | 852 | 787 | 788 | 0 |
| 2 | 874.53 | 817.04 | 1515 | 858 | 798 | 810 | 0 |
| 3 | 874.61 | 817.56 | 1506 | 873 | 812 | 841 | 1 |
| 4 | 870.45 | 817.39 | 1503 | 889 | 824 | 864 | 1 |
目录
1 建模前夜
1.1 数据处理
1.1.1 一般性数据预处理
1.1.2 标准化
1.1.3 归一化
1.1.4 切分训练集、测试集
1.2 模型核心概念概述
1.2.1 分类与回归
2 机器学习建模
2.1 常规模型建模
2.1.1 Logistic regression (逻辑回归)
2.1.2 Support Vector Machine(支持向量机)
2.1.3 Random Forest(随机森林)
2.1.4 K-Nearest Neighbor (K近邻)
2.1.5 Naive Bayes Classifier (朴素贝叶斯分离器)
2.1.6 Decision tree (决策树)
2.1.7 Multi-Layer Perceptron(多层感知器)
2.1.8 Gradient Boosting Decision Tree(梯度提升决策树)
2.2 集成模型
2.2.1 Voting 模型(多模型投票机制)
2.2.2 Bagging 模型
2.2.3 AdaBoost 模型(自适应增强模型)
3 结果的评估
3.1 分类器模型评估指标
3.1.1 Accuracy score(准确率)
3.1.2 Precision score(精确率、查准率)
3.1.3 Recall score(召回率)
3.1.4 Roc-Auc score (AUC值)
3.1.5 Receiver operating characteristic curve (ROC 曲线)
3.1.6 Area under Curve(AUC曲线)
3.1.7 交叉验证
3.1.8 混淆矩阵
3.2 回归模型评价指标
3.2.1 Mean Squared Error(MSE) 均方误差
3.2.2 Root Mean Squard Error(RMSE) 均方根误差
3.2.3 Mean Absolute Error(MAE) 平均绝对误差
3.2.4 R-Square (R^2)决定系数
3.2.5 Adjusted R-Square 修正R^2
4 参数评估
4.1 训练集各维度权重评估
参考链接(感谢)
1 建模前夜
1.1 数据处理
1.1.1 一般性数据预处理
出门左转:https://blog.csdn.net/weixin_35757704/article/details/89280715
1.1.2 标准化
这一步是为了便于模型训练,使数值矩阵每一列的均值都为0,方差为1
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
#将训练集都标准化
x_train = stdsc.fit_transform(x_train)
y_train = stdsc.fit_transform(y_train)
注意:x_train 与 y_train 中不能有非数值类型的值
1.1.3 归一化
将所有特征压缩在 [ 0 , 1 ] 这个区间上
from sklearn.preprocessing import MinMaxScaler
mms= MinMaxScaler()
#将训练集归一化
x_train = mms.fit_transform(x_train)
y_train = mms.fit_transform(y_train)1.1.4 切分训练集、测试集
首先得到 已知特征 x 与 结果 y
x = dataframe.drop('mask',axis=1)
y = dataframe['mask']然后切分训练集与测试集:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)按照3-7开,70% 的训练数据,30%的测试数据
random_state :随机种子
1.2 模型核心概念概述
1.2.1 分类与回归
这是新手特别容易混淆的:
简单区分:
分类:回忆小时候我们看剧的时候看到结局,我们就能区分这个是好人,这个是坏人;最后能明显贴标签的就是分类。
回归:今天狂风暴雨,那么明天的气温应该是多少呢?最后预测结果是一个区间值(标签化不明显)的就是回归
注意:Logistic回归的模型 并不是回归,而是分类
如果觉得这部分博主瞎讲,那么恭喜你答对了,请期待博主之后从数学的角度写的博客哟~~
2 机器学习建模
2.1 常规模型建模
这样的模型解决回归问题的类是 xxxRegression,解决分类问题的类是 xxxClassifier
2.1.1 Logistic regression (逻辑回归)
from sklearn.linear_model import LogisticRegression
log_model = LogisticRegression()
log_model.fit(x_train,y_train)2.1.2 Support Vector Machine(支持向量机)
from sklearn import svm
svm_model = svm.SVC(kernel='rbf',C=1,gamma=0.1)
# svm_model = svm.SVC(kernel='linear',C=0.1,gamma=0.1)
svm_model.fit(x_train,y_train)SVC参数:
kernel:"rbf" , "linear"
2.1.3 Random Forest(随机森林)
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(n_estimators=10)
rf_model.fit(x_train,y_train)参数:
n_estimators = 10 :树的数量
2.1.4 K-Nearest Neighbor (K近邻)
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier()
knn_model.fit(x_train,y_train)KNeighborsClassifier参数:
n_neighbours=5 : k值(近邻参考值)
2.1.5 Naive Bayes Classifier (朴素贝叶斯分离器)
from sklearn.naive_bayes import GaussianNB
gnb_model = GaussianNB()
gnb_model.fit(x_train,y_train)2.1.6 Decision tree (决策树)
from sklearn.tree import DecisionTreeClassifier
decision_tree_model = DecisionTreeClassifier(max_depth=10)
decision_tree_model.fit(x_train,y_train)DecisionTreeClassifier参数:
max_depth:最大深度
2.1.7 Multi-Layer Perceptron(多层感知器)
from sklearn.neural_network import MLPClassifier
mlp_model = MLPClassifier()
mlp_model.fit(x_train,y_train)2.1.8 Gradient Boosting Decision Tree(梯度提升决策树)
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier()
gbc.fit(x_train,y_train)
它与随机森林类似,也有比如n_estimators这样的参数,可以根据情况配置,效果一般情况下比随机森林好一点
2.2 集成模型
2.2.1 Voting 模型(多模型投票机制)
像是多个模型举手表决一样进行预测,这个模型的准确率波动实在让人印象深刻。
from sklearn.ensemble import VotingClassifier
votion_model = VotingClassifier(estimators=[
('模型名称1',result_model1),
('模型名称2',result_model2),
])
votion_model.fit(x_train,y_train)
2.2.2 Bagging 模型
一个分类器(bag_model)并行构造多个模型(base_estimator)
from sklearn.ensemble import BaggingClassifier
bag_model = BaggingClassifier(base_estimator=result_model,n_estimators=100)
bag_model.fit(x_train,y_train)BaggingClassifier参数:
base_estimator:默认决策树,指定需要并行构造的那一个模型
random_state:随机种子
n_estimators:并行构造的数量
2.2.3 AdaBoost 模型(自适应增强模型)
from sklearn.ensemble import AdaBoostClassifier
ada_cf = AdaBoostClassifier(base_estimator=result_model,n_estimators=100,learning_rate=0.1)
result = cross_val_score(ada_cf,x,y,cv=10,scoring='accuracy')AdaBoostClassifier参数:
base_estimator:默认决策树,指定需要并行构造的那一个模型
random_state:随机种子
n_estimators:并行构造的数量
learning_rate:学习率
3 结果的评估
假设训练出来的模型变量名叫 result_model,预测的结果是result_prediction,真实的结果是y_test
3.1 分类器模型评估指标
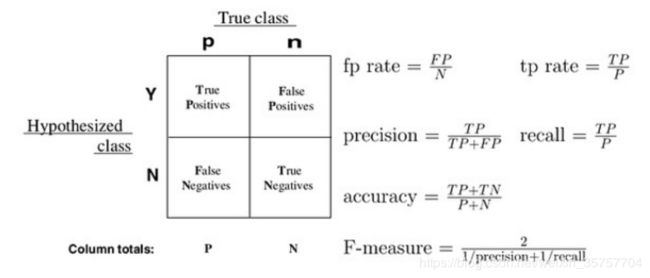
根据上方的图可以更加形象的看各个指标的含义
3.1.1 Accuracy score(准确率)
准确率 = 预测对的样本数 / 全部样本数
from sklearn.metrics import accuracy_score
result_prediction = result_model.predict(x_test)
# 参数为 (真实值,预测值)
score = accuracy_score(y_test,result_prediction)
print(score) # 得到预测结果区间[0,1]3.1.2 Precision score(精确率、查准率)
精确率 = 被预测出的正例样本数 / 预测为正例的样本数
它表示预测为正例的样本中有多少真的是正例。
from sklearn.metrics import precision_score
result_prediction = result_model.predict(x_test)
# 参数为 (真实值,预测值)
score = precision_score(y_test,result_prediction)
print(score) # 得到预测结果区间[0,1]3.1.3 Recall score(召回率)
召回率 = 预测且真的是正例的样本数 / 正例的样本数
它表示样本中的正例有多少被准确预测了。
from sklearn.metrics import recall_score
result_prediction = result_model.predict(x_test)
# 参数为 (真实值,预测值)
score = recall_score(y_test,result_prediction)
print(score) # 得到预测结果区间[0,1]3.1.4 Roc-Auc score (AUC值)
这个函数的计算也是AUC的值
from sklearn.metrics import roc_auc_score
result_prediction = result_model.predict(x_test)
# 参数为 (真实值,预测值)
score = roc_auc_score(y_test,result_prediction)
print(score) # 得到预测结果区间[0,1]3.1.5 Receiver operating characteristic curve (ROC 曲线)
请参考这篇博客:https://blog.csdn.net/abcjennifer/article/details/7359370
3.1.6 Area under Curve(AUC曲线)
请参考这篇博客:https://blog.csdn.net/u013385925/article/details/80385873
3.1.7 交叉验证
可以得到一个模型的平均精度
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
kfold = KFold(n_splits=10,random_state=0)
# x 为所有数据中用来预测的特征;y为所有数据中需要预测的结果列
cv_cross = cross_val_score(result_model,x,y,cv=kfold,scoring="accuracy")
print(cv_cross.mean()) # 交叉验证均值
print(cv_cross.std()) # 交叉验证标准差KFold参数:
- n_splits:交叉验证将数据集平均切分的份数
3.1.8 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,result_prediction)混淆矩阵会生成 n*n 的混淆矩阵,主对角线是预测对的值,左侧为真实值,上边是预测值。混淆矩阵可以初步看出分类器的问题。

3.2 回归模型评价指标
3.2.1 Mean Squared Error(MSE) 均方误差
from sklearn.metrics import mean_squared_error
print(mean_squared_error(y_test,result_prediction))

3.2.2 Root Mean Squard Error(RMSE) 均方根误差
import numpy as np
from sklearn.metrics import mean_squared_error
print(np.sqrt(mean_squared_error(y_test,result_prediction)))
均方根误差就是均方误差开根号:
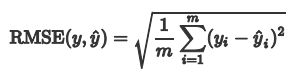
3.2.3 Mean Absolute Error(MAE) 平均绝对误差
from sklearn.metrics import mean_absolute_error
print(mean_absolute_error(y_test,result_prediction))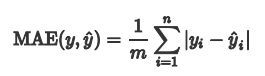
相当于求预测值与真实值的差值的绝对值,累加后求平均
3.2.4 R-Square (R^2)决定系数
from sklearn.metrics import r2_score
print(r2_score(y_test,result_prediction))
取值范围为 [0,1] ,越接近1,模型效果越好,越接近0,效果越差;但是随着预测数据量的增加会增加降低R2值,因此只能大致评估模型,建议使用3.2.5中的校正决定系数进行评估。
3.2.5 Adjusted R-Square 修正R^2
from sklearn.metrics import r2_score
def ad_r2(y_test,result_prediction,train_df):
p = train_df.shape(0) # 特征数量
n = train_df.shape(1) # 样本数量
return (1-((1-r2_score(y_test,result_prediction))*(n-1))/(n-p-1))
# x_train 是Dataframe格式的训练样本
adr = ad_r2(y_test,result_prediction,x_train)
print(adr)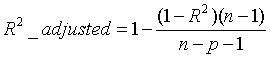
取值范围为 [0,1] ,越接近1,模型效果越好,越接近0,效果越差。可以定量比较不同模型的效果。
4 参数评估
4.1 训练集各维度权重评估
result_model.feature_importances_
参考链接(感谢)
Minitab 18 支持:https://support.minitab.com/zh-cn/minitab/18/
分类与回归的区别是什么:https://www.zhihu.com/question/21329754
机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线:https://blog.csdn.net/quiet_girl/article/details/70830796
sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix):https://blog.csdn.net/CherDW/article/details/55813071
AUC,ROC我看到的最透彻的讲解:https://blog.csdn.net/u013385925/article/details/80385873
ROC曲线-阈值评价标准:https://blog.csdn.net/abcjennifer/article/details/7359370
机器学习评估指标:https://zhuanlan.zhihu.com/p/36305931
回归评价指标:MSE、RMSE、MAE、R2、Adjusted R2:https://blog.csdn.net/u012735708/article/details/84337262