python数据挖掘包SciPy Sparse
博客原文:http://blog.csdn.net/pipisorry/article/details/41762945
简介
SciPy是为数学,科学和工程服务的开源软件
SciPy是建立在Numpy上的数学算法和便利函数的集合
对于那些零元素数目远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称为稀疏矩阵(sparse),由于稀疏矩阵中非零元素较少,零元素较多,因此可以采用只存储非零元素的方法来进行压缩存储。
常用存储格式
现有许多种稀疏矩阵的存储方式,但是多数采用相同的基本技术,即存储矩阵所有的非零元素到一个线性数组中,并提供辅助数组来描述原数组中非零元素的位置。Sparse Matrix Storage Formats稀疏矩阵的存储格式:
Coordinate Format (COO)
一种坐标形式的稀疏矩阵。采用三个数组row、col和data保存非零元素的信息,这三个数组的长度相同,row保存元素的行,col保存元素的列,data保存元素的值

参数:
数组values: 实数或复数数据,包括矩阵中的非零元素,顺序任意。
数组rows: 数据所处的行。
数组columns: 数据所处的列。
矩阵中非零元素的数量 nnz,3个数组的长度均为nnz.
总结:存储的主要优点是灵活、简单,仅存储非零元素以及每个非零元素的坐标。但是COO**不支持元素的存取和增删**,一旦创建之后,除了将之转换成其它格式的矩阵,几乎无法对其做任何操作和矩阵运算
Diagonal Storage Format (DIA)
如果稀疏矩阵有仅包含非0元素的对角线,则对角存储格式(DIA)可以减少非0元素定位的信息量。
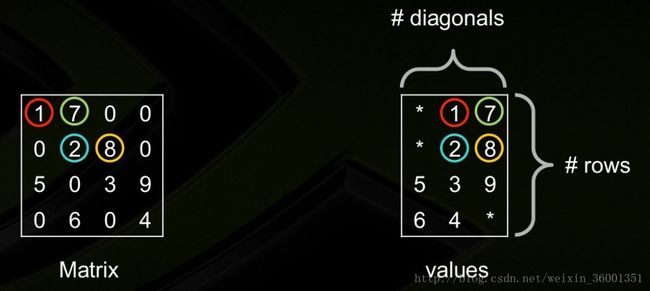
DIA通过两个数组确定: values、distance。
其中values:对角线元素的值;
distance:第i个distance是当前第i个对角线和主对角线的距离
总结:这种存储格式对有限元素或者有限差分离散化的矩阵尤其有效。
Compressed Sparse Row Format (CSR)
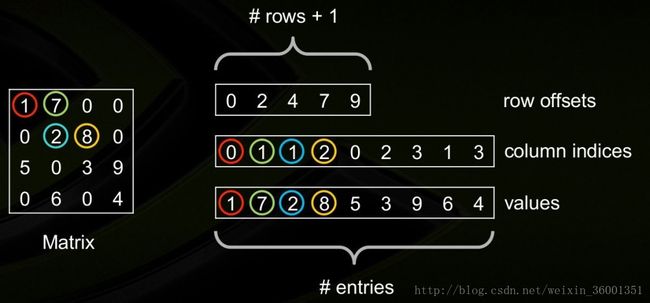
压缩稀疏行格式(CSR)通过四个数组确定: values,columns, pointerB, pointerE.
其中
数组values:是一个实(复)数,包含矩阵A中的非0元,以行优先的形式保存;数组columns:第i个整型元素代表矩阵A中第i列;
数组pointerB :第j个整型元素给出矩阵A行j中第一个非0元的位置,等价于pointerB(j) -pointerB(1)+1 ;
数组pointerE:第j个整型元素给出矩阵A第j行最后一个非0元的位置,等价于pointerE(j)-pointerB(1)。
* Compressed Sparse Column Format (CSC)*
压缩稀疏列格式(CSC)类似CSR格式,只是用的是列而不是行压缩。换句话说,矩阵A的CSC 格式和矩阵A的转置的CSR是一样的
同样CSC也是由四个数组确定:values, columns, pointerB, and pointerE. 含义类同CSR
dok_matrix
基于keys的字典稀疏矩阵。
lil_matrix
基于行链接列表的稀疏矩阵,增量式创建稀疏矩阵的结构。
其他: Skyline Storage Format 、Block Compressed Sparse Row Format (BSR)、ELLPACK (ELL)、Hybrid (HYB) 。。。。
优缺点
sparse matrix稀疏矩阵不同的存储形式在sparse模块中对应如下:
bsr_matrix(arg1[, shape, dtype,copy, blocksize]) Block Sparse Row matrix
coo_matrix(arg1[, shape, dtype,copy]) A sparse matrix in COOrdinate format.
csc_matrix(arg1[, shape, dtype,copy]) Compressed Sparse Column matrix
csr_matrix(arg1[, shape, dtype,copy]) Compressed Sparse Row matrix
dia_matrix(arg1[, shape, dtype,copy]) Sparse matrix with DIAgonal storage
dok_matrix(arg1[, shape, dtype,copy]) Dictionary Of Keys based sparse matrix.
lil_matrix(arg1[, shape, dtype,copy]) Row-based linked list sparse matrix
scripy稀疏矩阵
scipy.sparse库中提供了多种表示稀疏矩阵的格式,每种格式都有不同的用处。同时稀疏矩阵可以支持加、减、乘、除和幂等算术操作
分块压缩稀疏行格式(BSR)bsr_matrix(arg1, shape=None, dtype=None, copy=False, blocksize=None)Block Sparse Row matrix
和压缩稀疏行格式(CSR)很相似,但是BSR更适合于有密集子矩阵的稀疏矩阵,分块矩阵通常出现在向量值有限的离散元中,在这种情景下,比CSR和CSC算术操作更有效
csc_matrix(arg1,shape=None, dtype=None, copy=False)压缩的列稀疏矩阵CSC
高效的CSC +CSC, CSC * CSC算术运算;高效的列切片操作。但是矩阵内积操作没有CSR, BSR快;行切片操作慢(相比CSR);稀疏结构的变化代价高
csr_matrix(arg1, shape=None, dtype=None, copy=False)Compressed Sparse Row matrix压缩稀疏行格式(CSR)
高效的CSR + CSR, CSR *CSR算术运算;高效的行切片操作;高效的矩阵内积内积操作。但是列切片操作慢(相比CSC);稀疏结构的变化代价高(相比LIL 或者 DOK)。CSR格式在存储稀疏矩阵时非零元素平均使用的字节数(Bytes per Nonzero Entry)最为稳定(float类型约为8.5,double类型约为12.5)。CSR格式常用于读入数据后进行稀疏矩阵计算
coo_matrix(arg1,shape=None,dtype=None,copy=False)坐标格式(COO)
坐标形式的一种稀疏矩阵。采用三个数组row、col和data保存非零元素的信息。这三个数组的长度相同,row保存元素的行,col保存元素的列,data保存元素的值。
coo_matrix不支持元素的存取和增删,一旦创建之后,除了将之转换成其它格式的矩阵,几乎无法对其做任何操作和矩阵运算
dia_matrix(arg1, shape=None, dtype=None, copy=False)Sparse matrix with DIAgonal storage
对角存储格式(DIA)和ELL格式在进行稀疏矩阵-矢量乘积(sparse matrix-vector products)时效率最高,所以它们是应用迭代法(如共轭梯度法)解稀疏线性系统最快的格式;DIA格式存储数据的非零元素平均使用的字节数与矩阵类型有较大关系,适合于StructuredMesh结构的稀疏矩阵(float类型约为4.05,double类型约为8.10)。对于Unstructured Mesh以及Random Matrix,DIA格式使用的字节数是CSR格式的十几倍
dok_matrix(arg1, shape=None, dtype=None, copy=False)Dictionary Of Keys based sparse matrix.
dok_matrix从dict继承,它采用字典保存矩阵中不为0的元素:字典的键是一个保存元素(行,列)信息的元组,其对应的值为矩阵中位于(行,列)中的元素值。显然字典格式的稀疏矩阵很适合单个元素的添加、删除和存取操作。通常用来逐渐添加非零元素,然后转换成其它支持快速运算的格式。
基于字典存储的稀疏矩阵
lil_matrix(arg1, shape=None, dtype=None, copy=False)Row-based linked list sparse matrix
基于行连接存储的稀疏矩阵。lil_matrix使用两个列表保存非零元素。data保存每行中的非零元素,rows保存非零元素所在的列。这种格式也很适合逐个添加元素,并且能快速获取行相关的数据。
综合
2. COO和CSR格式比起DIA和ELL来,更加灵活,易于操作;
3. ELL的优点是快速,而COO优点是灵活,二者结合后的HYB格式是一种不错的稀疏矩阵表示格式;
4. 根据Nathan Bell的工作:
CSR格式在存储稀疏矩阵时非零元素平均使用的字节数(Bytes per Nonzero Entry)最为稳定(float类型约为8.5,double类型约为12.5)
而DIA格式存储数据的非零元素平均使用的字节数与矩阵类型有较大关系,适合于StructuredMesh结构的稀疏矩阵(float类型约为4.05,double类型约为8.10)
对于Unstructured Mesh以及Random Matrix,DIA格式使用的字节数是CSR格式的十几倍;
5. 一些线性代数计算库:COO格式常用于从文件中进行稀疏矩阵的读写,如matrix market即采用COO格式,而CSR格式常用于读入数据后进行稀疏矩阵计算。
函数
sparse matrix稀疏矩阵不同的存储形式在sparse模块中对应如下:官方API
调用格式及参数说明:
rg1:密集矩阵或者另一个稀疏矩阵;
shape=(M, N):创建的稀疏矩阵的shape为(M, N)未指定时从索引数组中推断;
dtype:稀疏矩阵元素类型,默认为’d’;
copy:bool类型,是否进行深拷贝,默认False。
其中BSR特有的参数blocksize:分块矩阵分块大小,而且必须被矩阵shape (M,N)整除。未指定时会自动使用启发式方法找到合适的分块大小。
坐标格式(COO) :
coo_matrix(arg1[, shape, dtype,copy])
[coo_matrix]
对角存储格式(DIA) :
dia_matrix(arg1[, shape, dtype,copy])
[dia_matrix]
压缩稀疏行格式(CSR) :
csr_matrix(arg1[, shape, dtype,copy])
[csr_matrix]
压缩稀疏列格式(CSC) :
csc_matrix(arg1[, shape, dtype,copy])
[csc_matrix]
分块压缩稀疏行格式(BSR) :
bsr_matrix(arg1[, shape, dtype,copy,blocksize])
[bsr_matrix]、
常用属性
dtype 矩阵数据类型
shape (2-tuple)矩阵形状
ndim (int)矩阵维数
nnz 非0元个数
data矩阵的数据数组
row COO特有的,矩阵行索引
col COO特有的,矩阵列索引
has_sorted_indices BSR有的,是否有排序索引
indices BSR特有的,BSR格式的索引数组
indptr BSR特有的,BSR格式的索引指针数组
blocksize BSR特有的,矩阵块大小
常用方法
asformat(format) 返回给定格式的稀疏矩阵
astype(t) 返回给定元素格式的稀疏矩阵
diagonal() 返回矩阵主对角元素
dot(other) 坐标点积
getcol(j) 返回矩阵列j的一个拷贝,作为一个(mx 1) 稀疏矩阵 (列向量)
getrow(i) 返回矩阵行i的一个拷贝,作为一个(1 x n) 稀疏矩阵 (行向量)
max([axis]) 给定轴的矩阵最大元素
nonzero() 非0元索引
todense([order, out]) 返回当前稀疏矩阵的密集矩阵表示
相关操作
创建核查看稀疏矩阵
直接将dense矩阵转换成稀疏矩阵
from scipy.sparse import coo_matrix
A = coo_matrix([[1,2],[3,4]])
print(A)
output:
(0, 0) 1
(0, 1) 2
(1, 0) 3
(1, 1) 4按照相应存储形式构建矩阵
import numpy as np
row = np.array([0,0,0,0,1,3,1])
col = np.array([0,0,0,2,1,3,1])
data = np.array([1,1,1,8,1,1,1])
matrix = coo_matrix((data,(row,col)),shape=(4,4))
print(matrix)
print(matrix.todense())
output:
(0, 0) 1
(0, 0) 1
(0, 0) 1
(0, 2) 8
(1, 1) 1
(3, 3) 1
(1, 1) 1
[[3 0 8 0]
[0 2 0 0]
[0 0 0 0]
[0 0 0 1]]csr_matrix总是返回稀疏矩阵,而不会返回一维向量。即使csr_matrix([2,3])也返回矩阵
稀疏矩阵大小
from scipy.sparse import csr_matrix
crs = csr_matrix([[1,5],[4,0],[1,3]])
print(crs.todense())
print(crs.shape)
print(crs.shape[1])
output:
[[1 5]
[4 0]
[1 3]]
(3, 2)
2稀疏矩阵下标存取
print(crs)
out:
(0, 0) 1
(0, 1) 5
(1, 0) 4
(2, 0) 1
(2, 1) 3
print(crs[0]) # 稀疏矩阵横向或者纵向合并
函数:vstack、hstack
from scipy.sparse import vstack
csr = csr_matrix([[1,5,5],[4,0,6],[1,3,7]])
print(csr.todense())
crs2 = csr_matrix([[3,0,9]])
print(crs2.todense())
print(vstack([crs,crs2]).todense)注意:如果合并数据形式不一样,不能合并。一个矩阵中的数据格式必须是相同的
sparse矩阵读取
可以像常规矩阵一样通过下标读取。也可以通过getrow(i),gecol(i)读取特定的列或者特定的行,以及nonzero()读取非零元素的位置。对于大多数(似乎只除了coo之外)稀疏矩阵的存储格式,都可以进行slice操作,比如对于csc,csr。也可以进行arithmeticoperations,矩阵的加减乘除,速度很快。
取矩阵指定列数
import numpy as np
row = np.array([0,0,0,0,1,3,1])
col = np.array([0,0,0,2,1,3,1])
data = np.array([1,1,1,8,1,1,1])
matrix = coo_matrix((data,(row,col)),shape=(4,4))
print(matrix)
out:
(0, 0) 1
(0, 0) 1
(0, 0) 1
(0, 2) 8
(1, 1) 1
(3, 3) 1
(1, 1) 1
sub = matrix.getcol(1) #'coo_matrix' object does not support indexing,不能使用matrix[1]
print(sub)
out:
(1, 0) 2
sub2 = matrix.todense()[:,[1,2]] # #常规矩阵取指定列print(sub)
out:
[[0 8]
[2 0]
[0 0]
[0 0]]稀疏矩阵点积计算
from scipy.sparse import csr_matrix
from numpy import *
import datetime
A = csr_matrix([[1,2,0],[0,0,3]])
print(A.todense())
V = A.T
print(V.todense())
out:
[[1 0]
[2 0]
[0 3]]
d = A.dot(V)
print(d)
(0, 0) 5
(1, 1) 9
from scipy.sparse import lil_matrix
B = lil_matrix([[1,2,0],[0,0,3],[4,0,5]])
v2 = array([1,0,-1])
s = datetime.datetime.now()
for i in range(10000):
d = B.dot(v2)
print(datetime.datetime.now() -s)
out:
0:00:00.492017
crs_mat1 = csr_matrix([1,2,0])
crs_mat2 = csr_matrix([1,0,-1])
similar = (crs_mat1.dot(crs_mat2.transpose())) # 这里csr_mat2也是一个csr_matrix
print(type(similar)) # 文件中读取
相关函数:
mmwrite(target, a[, comment, field, precision]) Writes the sparse or dense array a to a Matrix Market formatted file.
mmread(source) Reads the contents of a Matrix Market file ‘filename’ into a matrix.
import random
import numpy as np
from scipy.sparse import csr_matrix
from scipy.io import mminfo,mmread,mmwrite
def save_csr_mat(
item_item_sparse_mat_filename=r'.\datasets\lastfm-dataset-1K\item_item_csr_mat.mtx'):
random.seed(10)
tmp_list = []
for i in range(6):
tmp_list.append(random.randint(0,6))
print(tmp_list) # [3, 3, 4, 1, 5, 5]
raw_user_item_mat = np.array(tmp_list).reshape(3,2)
d = csr_matrix(raw_user_item_mat)
print(d.todense())
out:
[[3 3]
[4 1]
[5 5]]
print(d)
(0, 0) 3
(0, 1) 3
(1, 0) 4
(1, 1) 1
(2, 0) 5
(2, 1) 5
mmwrite(item_item_sparse_mat_filename, d)
print("item_item_sparse_mat_file information: ")
print(mminfo(item_item_sparse_mat_filename)) #(3, 2, 6, 'coordinate', 'integer', 'general')
k = mmread(item_item_sparse_mat_filename)
print(k.todense())
out:
[[3 3]
[4 1]
[5 5]]
save_csr_mat()保存的文件拓展名应为.mtx
实例
背景: 推荐系统中经常需要处理类似user_id, item_id, rating这样的数据,其实就是数学里面的稀疏矩阵,scipy中提供了sparse模块来解决这个问题。但scipy.sparse有很多问题不太合用:
- 不能很好的同时支持data[i, …]、data[…, j]、data[i, j]快速切片
- 由于数据保存在内存中,不能很好的支持海量数据处理。
要支持data[i, …]、data[…, j]的快速切片,需要i或者j的数据集中存储;同时,为了保存海量的数据,也需要把数据的一部分放在硬盘上,用内存做buffer。
这里的解决方案比较简单,用一个类Dict的东西来存储数据,对于某个i(比如9527),它的数据保存在dict[‘i9527’]里面,需要取出data[9527, …]的时候,只要取出dict[‘i9527’]即可,dict[‘i9527’]原本是一个dict对象,储存某个j对应的值,为了节省内存空间,我们把这个dict以二进制字符串形式存储。采用类Dict来存储数据的另一个好处是你可以随便用内存Dict或者其他任何形式的DBM
点这里
测试4500W条rating数据(整形,整型,浮点格式),922MB文本文件导入,采用内存dict储存的话,12分钟构建完毕,消耗内存1.2G,采用示例代码中的bdb存储,20分钟构建完毕,占用内存300~400MB左右,比cachesize大不了多少。消耗1.4788秒,大概读取一条数据1.5ms
sklearn特征提取中的稀疏情景
加载字典的中的特征:类 DictVectorizer 可以把特征向量转化成标准的Python字典对象的一个列表,同时也是被scikit-learn的估计器使用的一个NumPy/SciPy体现(ndarray)
即使处理时并不是特别快,python的字典有易于使用的优势,适用于稀疏情景(缺失特征不会被存储),存储特征的名字和值
特征哈希:类 FeatureHasher 是一个快速且低内存消耗的向量化方法,使用了 feature hashing 技术,或可称为”hashing trick”。没有像矢量化那样,为计算训练得到的特征建立哈西表,类 FeatureHasher 的实例使用了一个哈希函数来直接确定特征在样本矩阵中的列号。这样在可检查性上增加了速度减少了内存开销。这个类不会记住输入特征的形状,也没有 inverse_transform 方法。
特征提取
本文转载地址首页已说明,更多详情查看原博文