MTCNN(三)基于python代码的网络结构更改
背景:MTCNN的训练是在python上实现的,我们需要对其结构进行更改。
目的:读懂MTCNN的python代码。
目录
一、代码结构
1.1 tensorflow设置与设备设置
1.2 设置placeholder与out_tensor
1.3 网络saver
1.4 定义相应的网络fun
1.5 用detect_face函数给出备选框
二、placeholder与out_tensor
2.1 tf.placeholder
2.2 PNet,RNet,ONet
2.2.1 pnet = PNet({'data': image_pnet}, mode='test')
2.2.2 out_tensor_pnet = pnet.get_all_output()
三、tf.train.saver模型的保存与恢复
四、网络的结构定义
Pnet原始结构
Pnet 最终结构
Rnet原始结构
Rnet最终结构
Onet原始结构
Onet最终采用结构
4.1 conv之中的定义
4.2 wd=self.weight_decay_coeff
一、代码结构
1.1 tensorflow设置与设备设置
import os
os.environ['CUDA_VISIBLE_DEVICES']='1'
...
file_paths = get_model_filenames(args.model_dir)
with tf.device('/gpu:0'):
with tf.Graph().as_default():
config = tf.ConfigProto(allow_soft_placement=True)
with tf.Session(config=config) as sess:注意,关于GPU的device是在os.environ['CUDA_VISIBLE_DEVICES']='1'后面这个变量来更改的,而不是后面的with tf.device('/gpu:0'):,这个需要后面查找什么意思。
1.2 设置placeholder与out_tensor
image_pnet = tf.placeholder(
tf.float32, [None, None, None, 3])
pnet = PNet({'data': image_pnet}, mode='test')
out_tensor_pnet = pnet.get_all_output()
image_rnet = tf.placeholder(tf.float32, [None, 24, 24, 3])
rnet = RNet({'data': image_rnet}, mode='test')
out_tensor_rnet = rnet.get_all_output()
image_onet = tf.placeholder(tf.float32, [None, 48, 48, 3])
onet = ONet({'data': image_onet}, mode='test')
out_tensor_onet = onet.get_all_output()1.3 网络saver
saver_pnet = tf.train.Saver(
[v for v in tf.global_variables()
if v.name[0:5] == "pnet/"])
saver_rnet = tf.train.Saver(
[v for v in tf.global_variables()
if v.name[0:5] == "rnet/"])
saver_onet = tf.train.Saver(
[v for v in tf.global_variables()
if v.name[0:5] == "onet/"])
saver_pnet.restore(sess, file_paths[0])1.4 定义相应的网络fun
def pnet_fun(img): return sess.run(
out_tensor_pnet, feed_dict={image_pnet: img})
saver_rnet.restore(sess, file_paths[1])
def rnet_fun(img): return sess.run(
out_tensor_rnet, feed_dict={image_rnet: img})
saver_onet.restore(sess, file_paths[2])
def onet_fun(img): return sess.run(
out_tensor_onet, feed_dict={image_onet: img})1.5 用detect_face函数给出备选框
rectangles, points = detect_face(img, args.minsize,
pnet_fun, rnet_fun, onet_fun,
args.threshold, args.factor)
二、placeholder与out_tensor
2.1 tf.placeholder
tf.placeholder(dtype, shape=None, name=None)
placeholder,占位符,在tensorflow中类似于函数参数,运行时必须传入值。
image_pnet = tf.placeholder(tf.float32, [None, None, None, 3])意思就是类型为float32类型,四维的数组,最后一个维度为3。
image_rnet = tf.placeholder(tf.float32, [None, 24, 24, 3])
image_onet = tf.placeholder(tf.float32, [None, 48, 48, 3])
根据向量可以看出分别是12,24与48,但是第一层仅仅是在训练的时候用12*12来训练,所以维度为None
2.2 PNet,RNet,ONet
引入在from src.mtcnn import PNet, RNet, ONet
2.2.1 pnet = PNet({'data': image_pnet}, mode='test')
定义在src/mtcnn.py之中
#src/mtcnn.py
class PNet(NetWork):
def setup(self, task='data', reuse=False):
...
if self.mode == 'train':
...
else
...
self.out_put.append(self.get_output())pnet是具体化的PNet,其中的'data'对应于image_pnet,其中的mode对应于'train'的else
2.2.2 out_tensor_pnet = pnet.get_all_output()
#src/mtcnn.py
class NetWork(object):
...
def get_all_output(self):
return self.out_put
...
def get_output(self):
return self.terminals[-1]self.output是最终定义完网络结构之后的最终的输出。
针对Pnet,输入为image_pnet,输出为out_tensor_pnet
三、tf.train.saver模型的保存与恢复
https://www.cnblogs.com/denny402/p/6940134.html
https://blog.csdn.net/index20001/article/details/74322198
四、网络的结构定义
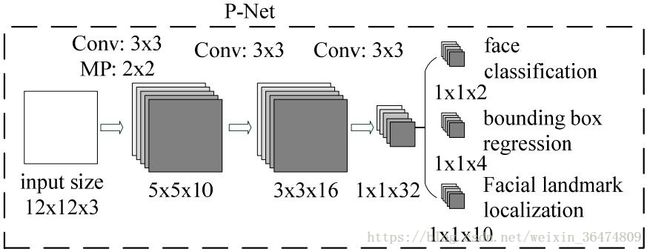
Pnet原始结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 12*12*3 |
conv1 prelu1 |
3*3*10 |
1 |
Valid |
| 10*10*10 |
pool1 | Maxpool 2*2 |
2 |
Same |
| 5*5*10 |
conv2 prelu2 |
3*3*16 |
1 |
Valid |
| 3*3*16 |
conv3 prelu3 |
3*3*32 |
1 |
Valid |
| 1*1*32 |
|
|
|
Pnet改进结构
| Feature size |
Kernel size |
Stride |
Padding |
| 12*12*3 |
3*3*10 |
1 |
Valid |
| 10*10*10 |
3*3*10 |
2 |
Same |
| 5*5*10 |
3*3*16 |
1 |
Valid |
| 3*3*16 |
3*3*32 |
1 |
Valid |
| 1*1*32 |
|
|
|
Pnet理想结构
| Feature size |
Kernel size |
Stride |
Padding |
| 12*12*3 |
3*3*10 |
1 |
same |
| 12*12*10 |
3*3*10 |
2 |
Same |
| 6*6*10 |
3*3*16 |
2 |
same |
| 3*3*16 |
3*3*32 |
1 |
same |
| 1*1*32 |
|
|
Pnet 最终结构
只有3×3的卷积(为保证输出的得分图与输入的映射,需要same与valid)
| Feature size |
name | Kernel size |
Stride |
Padding |
| 12*12*3 |
conv1 prelu1 |
3*3*10 |
1 |
Valid |
| 10*10*10 |
pool1_conv1 pool1_prelu1 |
3*3*16 |
2 |
Same |
| 5*5*16 |
conv2 prelu2 |
3*3*32 |
1 |
Valid |
| 3*3*32 |
conv3 prelu3 |
3*3*32 |
1 |
Valid |
| 1*1*32 |
|
|
|
注意!代码更改之后stride也变了,所以需要更改tools之中的generateBoundingBox的stride的尺度,及关于stride的映射。
最终训练结构:
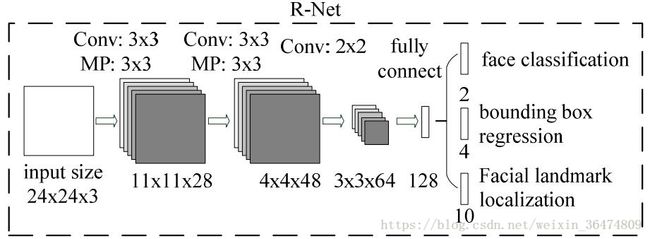
Rnet原始结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 24*24*3 |
conv1 prelu1 |
3*3*28 |
1 |
Valid |
| 22*22*28 |
pool1 | maxPool 3*3 |
2 |
Same |
| 11*11*28 |
conv2 prelu2 |
3*3*48 |
1 |
Valid |
| 9*9*48 |
pool2 | maxPool 3*3 |
2 |
valid |
| 4*4*48 |
conv3 prelu3 |
2*2*64 |
1 |
Valid |
| 3*3*64 |
|
|
|
Rnet改进结构
| Feature size |
Kernel size |
Stride |
Padding |
| 24*24*3 |
3*3*28 |
1 |
Valid |
| 22*22*28 |
3*3*28 |
2 |
Same |
| 11*11*28 |
3*3*48 |
1 |
Valid |
| 9*9*48 |
3*3*48 |
2 |
same |
| 5*5*48 |
3*3*64 |
1 |
valid |
| 3*3*64 |
|
|
|
Rnet最终结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 24*24*3 |
conv1 prelu1 |
3*3*28 |
1 |
Same |
| 24*24*28 |
pool1_conv1 pool1_prelu1 |
3*3*28 | 2 | Same |
| 12*12*28 | conv2 prelu2 |
3*3*48 | 1 | Same |
| 12*12*48 | pool2_conv3 poo2_prelu3 |
3*3*48 | 2 | Same |
| 6*6*48 | conv3 prelu3 |
3*3*64 | 2 | Same |
| 3*3*64 |
|
|
最终训练结构:
all trainable variables:
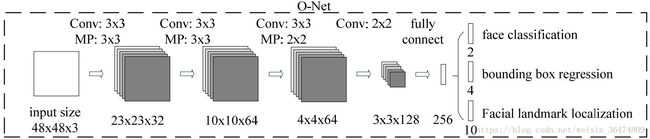
Onet原始结构
| Feature size |
name | Kernel size |
Stride |
Padding |
| 48*48*3 |
conv1 prelu1 |
3*3*32 |
1 |
Valid |
| 46*46*32 |
pool1 | maxPool 3*3 |
2 |
Same |
| 23*23*32 |
conv2 prelu2 |
3*3*64 |
1 |
Valid |
| 21*21*64 |
pool2 | maxPool 3*3 |
2 |
valid |
| 10*10*64 |
conv3 prelu3 |
3*3*64 |
1 |
Valid |
| 8*8*64 |
pool3 | maxPool 2*2 | 2 |
Same |
| 4*4*64 | conv4 prelu4 |
2*2*128 | 1 | valid |
| 3*3*128 |
Onet最终采用结构
因其参数量较小,最终采用 (mAP=58.58%)?
| Feature size |
name | Kernel size |
Stride |
Padding |
| 48*48*3 |
conv1 prelu1 |
3*3*32 |
1 |
Same |
| 48*48*32 | conv2 prelu2 |
3*3*32 | 2 |
Same |
| 24*24*32 |
conv3 prelu3 |
3*3*64 | 1 |
Same |
| 24*24*64 |
conv4_ prelu4_ |
3*3*64 | 2 |
Same |
| 12*12*64 |
conv5_ prelu5_ |
3*3*128 | 2 |
Same |
| 6*6*128 |
conv6_ prelu6_ |
3*3*128 | 2 |
Same |
| 3*3*128 |
Onet改进结构,只有same的3×3卷积,增加参数量可以增加mAP=59.85%
| Feature size |
Kernel size |
Stride |
Padding |
| 48*48*3 |
3*3*32 |
1 |
Same |
| 48*48*32 |
3*3*64 |
2 |
Same |
| 24*24*64 |
3*3*64 |
1 |
Same |
| 24*24*64 |
3*3*128 |
2 |
Same |
| 12*12*128 |
3*3*256 |
2 |
Same |
| 6*6*256 |
3*3*128 |
2 |
Same |
| 3*3*128 |
Onet layer 8层卷积结构,只有same的3×3卷积mAP=64.19%
| Feature size |
Kernel size |
Stride |
Padding |
| 48*48*3 |
3*3*32 |
1 |
Same |
| 48*48*32 |
3*3*64 |
2 |
Same |
| 24*24*64 |
3*3*128 |
1 |
Same |
| 24*24*128 |
3*3*256 |
2 |
Same |
| 12*12*256 | 3*3*256 | 1 | Same |
| 12*12*256 | 3*3*256 | 1 | Same |
| 12*12*256 |
3*3*256 |
2 |
Same |
| 6*6*256 |
3*3*128 |
2 |
Same |
| 3*3*128 |
最终训练参数
4.1 conv之中的定义
#src/mtcnn.py in class NetWork(object):
def conv(self, inp, k_h, k_w, c_o, s_h, s_w, name,
task=None, relu=True, padding='SAME',
group=1, biased=True, wd=None):
self.validate_padding(padding)
c_i = int(inp.get_shape()[-1])
assert c_i % group == 0
assert c_o % group == 0
def convolve(i, k): return tf.nn.conv2d(
i, k, [1, s_h, s_w, 1], padding=padding)
with tf.variable_scope(name) as scope:
kernel = self.make_var(
'weights', shape=[
k_h, k_w, c_i / group, c_o])
if group == 1:
output = convolve(inp, kernel)
else:
input_groups = tf.split(inp, group, 3)
kernel_groups = tf.split(kernel, group, 3)
output_groups = [convolve(i, k) for i, k in
zip(input_groups, kernel_groups)]
output = tf.concat(output_groups, 3)
if (wd is not None) and (self.mode == 'train'):
self.weight_decay[task].append(
tf.multiply(tf.nn.l2_loss(kernel), wd))
if biased:
biases = self.make_var('biases', [c_o])
output = tf.nn.bias_add(output, biases)
if relu:
output = tf.nn.relu(output, name=scope.name)
return outputpadding='SAME'就是输入输出一样大,‘VALID’就是不进行padding
几个数字分别为卷积核的大小,卷积核的个数,卷积核时的stride
4.2 wd=self.weight_decay_coeff
网络中有的有此语句,有的没有此语句,该语句全都在后几层。
# src/mtcnn.py in class class NetWork(object):
# in def conv
if (wd is not None) and (self.mode == 'train'):
self.weight_decay[task].append(
tf.multiply(tf.nn.l2_loss(kernel), wd))是对权重的步长的设置,应该对结果没有太大影响。