python爬虫----b站的弹幕获取
这次逛到b站的音乐里面的我以歌声寄明月中的洛天依原创的《独醉宣月》,感觉是一首良曲,画风也很不错!所以就对它起了“歹徒之心”,而去把弹幕给获取来作词云。
导包
import requests-----网页请求
import time-----延时操作
import jieba----分词操作
import numpy as np-----图片格式转换为数组
from PIL import Image-----图片的读取
from wordcloud import WordCloud as wc----词云制作
网页分析
https://www.bilibili.com/video/av1490046/,这是目标资源。通过检查元素-->netword,去寻找有关弹幕的链接,会发现到一个与众不同的东西,名为list.so?oid=XXXX的目标。选中它直接点击preview并没有什么内容,正当我们去查看的它请求头的时候,把它的url重新去搜索一遍就会发现一丝不可告人的秘密了!
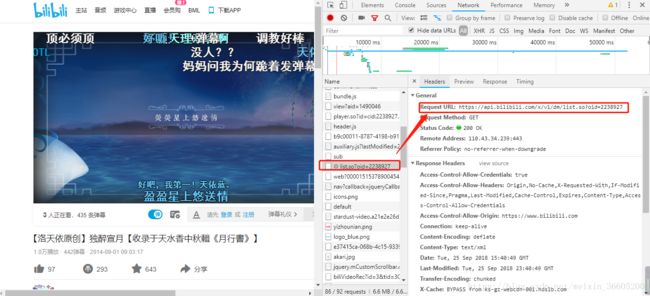
list.so?oid=xxxx的结果,这技术我们要找的弹幕资源了!
网页获取和解析
把所有的操作都封装成的一个类Bilibili,初始化就设置好请求头跟url以及弹幕的获取,由于弹幕的数据是放在一个xml文件的,所以就把这个目标的文件给下载了,再用xpath解析xml文档,xpath的作用在于快速去查找到想要的目标。
"""docstring for Bilibili"""
def __init__(self,oid):
self.headers={
'Host': 'api.bilibili.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'finger=edc6ecda; LIVE_BUVID=AUTO1415378023816310; stardustvideo=1; CURRENT_FNVAL=8; buvid3=0D8F3D74-987D-442D-99CF-42BC9A967709149017infoc; rpdid=olwimklsiidoskmqwipww; fts=1537803390'
}
self.url='https://api.bilibili.com/x/v1/dm/list.so?oid='+str(oid)
self.barrage_reault=self.get_page()
# 获取信息
def get_page(self):
try:
# 延时操作,防止太快爬取
time.sleep(0.5)
response=requests.get(self.url,headers=self.headers)
except Exception as e:
print('获取xml内容失败,%s' % e)
return False
else:
if response.status_code == 200:
# 下载xml文件
with open('bilibili.xml','wb') as f:
f.write(response.content)
return True
else:
return False
# 解析网页
def param_page(self):
time.sleep(1)
if self.barrage_reault:
# 文件路径,html解析器
html=etree.parse('bilibili.xml',etree.HTMLParser())
# xpath解析,获取当前所有的d标签下的所有文本内容
results=html.xpath('//d//text()')
return results弹幕去重
先把弹幕内容存储到一个results的空列表中去,每次都要判断当前的列表是否存在该元素,不存在就添加,否则,就添加到double_barrage列表和barrage的集合去,方便下面的弹幕内容的重复数量的统计。
# 弹幕去重
def remove_double_barrage(self):
'''
double_arrage:所有重复弹幕的集合
results:去重后的弹幕
barrage:每种弹幕内容都存储一遍
'''
double_barrage=[]
results=[]
barrage=set()
for result in self.param_page():
if result not in results:
results.append(result)
else:
double_barrage.append(result)
barrage.add(result)
return double_barrage,results,barrage
弹幕重复内容的计数和词云的制作
# 弹幕重复计算和词云的制作
def make_wordCould(self):
double_barrages,results,barrages=self.remove_double_barrage()
# 重词计数,结果写进txt文件
with open('barrages.txt','w') as f:
for barrage in barrages:
# 数量的统计
amount=double_barrages.count(barrage)
f.write(barrage+':'+str(amount+1)+'\n')
# 设置停用词
stop_words=['【','】',',','.','?','!','。']
words=[]
if results:
for result in results:
for stop in stop_words:
# 去除上面的停用词,再拼接成字符串
result=''.join(result.split(stop))
words.append(result)
# 列表拼接成字符串
words=''.join(words)
words=jieba.cut(words)
words=''.join(words)
luo=np.array(Image.open('洛天依.jpg'))
w=wc(font_path='C:/Windows/Fonts/SIMYOU.TTF',background_color='white',width=1600,height=1600,max_words=2000,mask=luo)
w.generate(words)
w.to_file('luo.jpg')实现的效果
词云的制作

弹幕重复内容的计数

项目链接:链接:https://pan.baidu.com/s/1EyCYYXtQNBl0ZPEMG_RyjQ 密码:l22z
欢迎来pick!