RabbitMQ的总结(一)
安装RabbitMQ
这里是基于docker安装的,非常的方便,拉取RabbitMQ镜像,运行即可

RabbitMQ自带的管理页面:http://119.25.162.48:15672/#
通过默认账户 guest/guest 登录,如果能够登录,说明安装成功。
了解一下消息中间件的应用场景
异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种1.串行的方式;2.并行的方式
(1)串行方式:将注册信息写入数据库后,发送注册邮件,再发送注册短信,以上三个任务全部完成后才返回给客户端。 这有一个问题是,邮件,短信并不是必须的,它只是一个通知,而这种做法让客户端等待没有必要等待的东西.
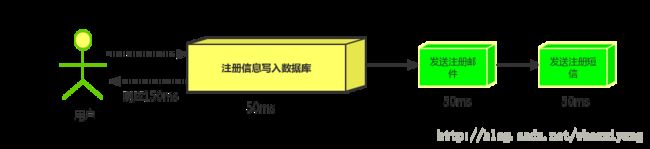
(2)并行方式:将注册信息写入数据库后,发送邮件的同时,发送短信,以上三个任务完成后,返回给客户端,并行的方式能提高处理的时间。
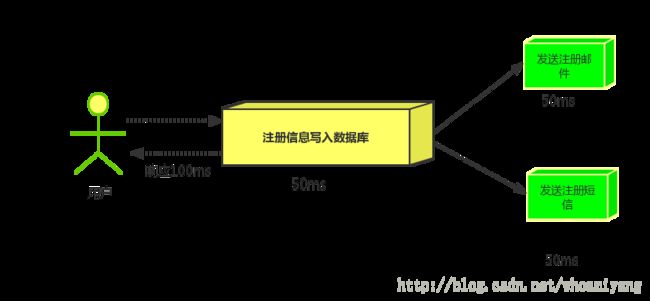
假设三个业务节点分别使用50ms,串行方式使用时间150ms,并行使用时间100ms。虽然并性已经提高的处理时间,但是,前面说过,邮件和短信对我正常的使用网站没有任何影响,客户端没有必要等着其发送完成才显示注册成功,英爱是写入数据库后就返回.
(3)消息队列
引入消息队列后,把发送邮件,短信不是必须的业务逻辑异步处理
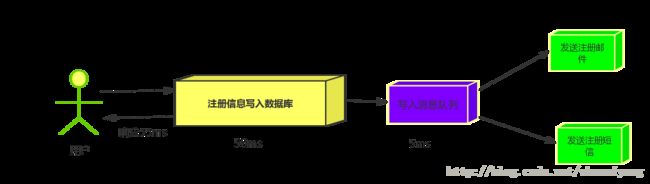
由此可以看出,引入消息队列后,用户的响应时间就等于写入数据库的时间+写入消息队列的时间(可以忽略不计),引入消息队列后处理后,响应时间是串行的3倍,是并行的2倍。
应用解耦
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口.
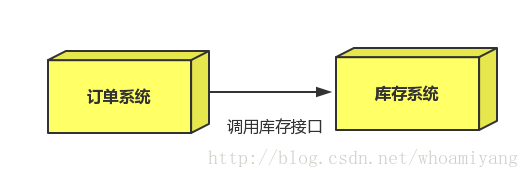
这种做法有一个缺点:
- 当库存系统出现故障时,订单就会失败。
- 订单系统和库存系统高耦合.
- 引入消息队列
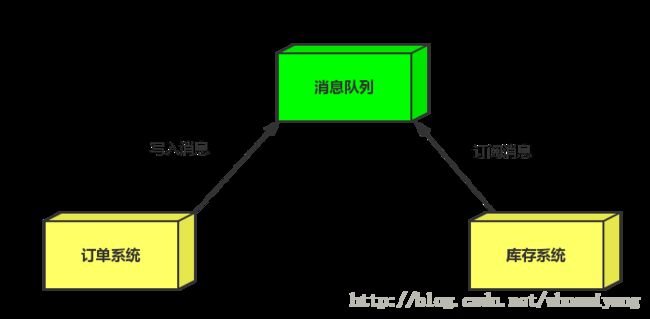
- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
- 库存系统:订阅下单的消息,获取下单消息,进行库操作。 就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失。
流量削峰
流量削峰一般在秒杀活动中应用广泛
场景:秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
1.可以控制活动人数,超过此一定阀值的订单直接丢弃(我为什么秒杀一次都没有成功过呢^^)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
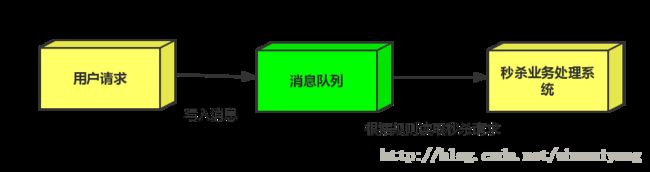
1.用户的请求,服务器收到之后,首先写入消息队列,加入消息队列长度超过最大值,则直接抛弃用户请求或跳转到错误页面.
2.秒杀业务根据消息队列中的请求信息,再做后续处理.
各种消息中间件性能的比较:
TPS比较 一ZeroMq 最好,RabbitMq 次之, ActiveMq 最差。
持久化消息比较—zeroMq不支持,activeMq和rabbitMq都支持。持久化消息主要是指:MQ down或者MQ所在的服务器down了,消息不会丢失的机制。
可靠性、灵活的路由、集群、事务、高可用的队列、消息排序、问题追踪、可视化管理工具、插件系统、社区—RabbitMq最好,ActiveMq次之,ZeroMq最差。
高并发—从实现语言来看,RabbitMQ最高,原因是它的实现语言是天生具备高并发高可用的erlang语言。
综上所述:RabbitMQ的性能相对来说更好更全面,是消息中间件的首选。
为什么要选择RabbitMQ
- 基于AMQP协议
- 高并发
- 高性能
- 高可用
- 强大的社区支持,以及很多公司都在使用
- 支持插件
- 支持多语言
RabbitMQ中的一些概念和思想
- Server:又称为Broker。RabbitMQ服务器,接收客户端连接,实现AMQP的服务器实体。
- Connection:连接,应用程序与Broker的网络连接。
- Channel:信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写的通道。客户端可建立多个Channel,每个Channel代表一个会话任务。
- Message:消息。服务器和应用程序之间传递的数据,本质上就是一段数据,由Properties和Body组成。
- Exchange:交换机。接收消息,根据路由键转发消息到绑定的队列。
- Binding:Exchange和Queue之间的虚拟连接,binding中可以包含routing key。
- Routing key:一个虚拟地址,虚拟机可用它来确定如何路由一个特定消息。
- Queue:也称为Message Queue,消息队列,保存消息并将它们转发给消费者。
- Virtual Host:其实是一个虚拟概念。类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,可以用来隔离Exchange和Queue。,同一个Virtual Host里面不能有相同名称的Exchange和Queue。但是权限控制的最小粒度是Virtual Host。
生产者和消费者
生产者创建消息,消费者接受消息,一个应用程序既可以作为生产者发送消息也可以作为一个消费者接受消息,再此之前,必须建立一条信道channel
什么是信道channel
我们必须连接Rabbit服务,才能消费或者发布消息,应用程序和Rabbit代理服务之间创建一条TCP连接,一旦TCP连接打开,应用程序就会创建一条AMQP信道,信道是建立TCP连接内的虚拟连接,AMQP命令都是通过信道发送出去的,每条信道都会被指派一个唯一ID(AMQP库会帮你记住ID),不论是发布消息、订阅队列还是接受消息、这些都是通过信道完成
为什么需要信道呢?而不是直接通过TCP连接发送AMQP命令呢
对操作系统来说创建和销毁TCP连接时非常昂贵的开销,如果使用TCP连接,每个线程都需要连接到Rabbit,高峰期每秒创建的成百上千的连接,很快就会性能瓶颈,引入信道,线程启动后,会在现成的连接上创建一条信道,所有线程只用1条TCP连接,又保证线程的私密性,就像拥有独立的连接一样,另外一个TCP连接上创建多少个信道是没有限制的。
队列,交换机,绑定
AMQP消息路由必须有3部分:交换机,队列,绑定,生产者把消息发布到交换机上,消息最终到达队列,并被消费者接收消费。绑定决定了消息如何从路由器到特定的队列,消息到达队列中(存储)并等待消费,需要注意对于没有路由到队列的消息会被丢弃,消费者通过以下2种方式从特定的队列中接受消息
a.通过AMQP的basic.consume命令订阅 。这样会将信道置为接受模式,直到取消对对列的订阅,订阅消息后,消费者在消费或者拒绝最近接受的那条消息之后,就能从队列中自动接收下一条消息;如果消费者处理队列消息并且需要在消息一到达队列时就自动接收就是用这个命令
b.如果只是想获取队列中的单条消息而不是持续订阅的话,可以使用AMQP的basic.get命令,意思就是接受队列的下条消息,如果还需要获取下个继续调用这个命令,不建议放在循环中调用来替代consume命令,性能会有影响
消息如何分发
如果至少有一个消费者订阅队列,消息会立即发送给订阅的消费者,如果消息到达了无人订阅的消费者,消息会在队列中等待,直到有消费者订阅该队列,消息就会自动发送给消费者,如果一个队列有多个消费者队列收到的消息会循环round-robin的方式发送给消费者,每条消息只会发送给一个订阅的消费者,假如有2个消费者p1和p2,消息的分发逻辑:
- 消息msgA到达queue队列
- MQ把消息msgA发送给p1
- p1确认收到消息msgA
- MQ把消息msgA从queue队列中删除
- 消息msgB到达queue队列
- MQ把消息msgB发送给p2
- p1确认收到消息msgB
- MQ把消息msgB从queue队列中删除
消息应答
消费者接受到的每条信息必须进行确认,消费者通过AMQP的basic.ack命令显式的想RabbitMQ发送一个确认,或者可以通过在订阅到队列的时候就将auto_ack参数设为true,设置true,RabbitMQ会自动默认确认消息,这就是手动确认和自动确认机制,只有经过确认接受了消息MQ才能安全的把消息从列队中删除该消息
当然如果消费者收到消息,在确认之前与RabbitMQ断开连接或者从队列上取消订阅,那么RabbitMQ会默认消息没有分发,它会重写分发给下一个订阅的消费者如果程序崩溃了,这样做可以确保消息不会丢失并被发送给另外一个消费者处理
另一方面,如果程序有bug而忘记确认消息的话,RabbitMQ不会给该消费者发送更多的消息,Rabbmit会认为这个消费者在没有上一个消息消费掉而无法准备接受下一个,这样可以保证在处理耗时的消息的时候,RabbitMQ不会持续的发送消息给你的应用导致过载
在接受消息后如果你像明确的拒绝而不是确认接受,我们可以使用AMQP的basic.reject命令去拒绝RabbitMQ发送的消息,如果把reject命令的requeue参数设置成true,RabbitMQ会把消息从新发送给下一个订阅者,如果设置成false,RabbitMQ立即把消息从列队中移除,而不会发送给其他消费者我们就可以利用这点去忽略一些格式错误的消息(任何消费者都无法处理的)
注意:当丢弃一条消息时,使用basic.reject+requeue=false来处理后,这个消息就被转移到“死信”dead letter队列中,死信队列就是用来存放哪些被拒绝而不重入队列的消息
创建队列
使用AMQP的queue.declare命令来创建队列,如果一个消费者在同一条信道channel上订阅了一个队列,他就无法在申明队列了,必须先取消订阅,将信道置为“传输”模式
创建队列的时候指定队列名称,消费者绑定/订阅队列的时候需要指定队列名称,如果不指定,RabbitMQ会随机分配一个随机名称由queue.declare返回
队列一般会设置以下有用的参数:
- exclusive:true表示队列变成私有,一般想要限制一个队列只有一个消费者的时候使用
- auto-delete:当最后一个消费者取消订阅,队列会自动删除,一般创建临时队列使用
如果申明一个已经存在的队列,RabbitMQ什么都不会做,并返回成功,可以利用这点判断对了是否存在,如果只想检测队列是否存在,可以通过queue.declare的passive选项为true,在这种情况下如果队列存在就会返回成功,如果不存在queue.declare不会创建队列而回返回要给错误
队列的作用:
为消息提供存储,再次等待消费
实现负载均衡,轮询消费
队列是Rabbit中消息的最后终点
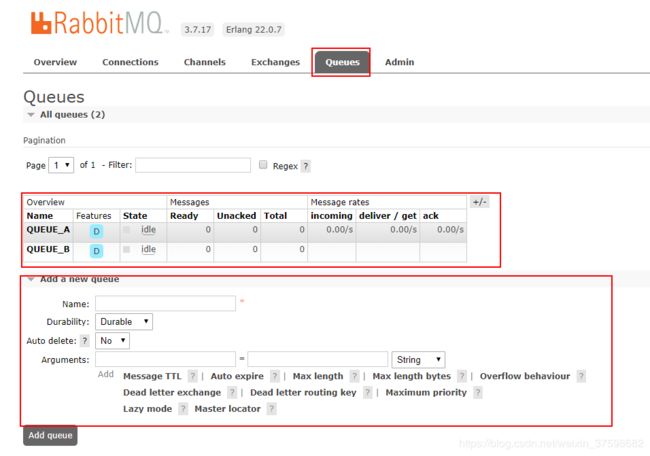
队列中的属性
- Durability:是否持久化,Durable是,Transient是否。如果不持久化,那么在服务器宕机或重启之后Queue就会丢失。
- Auto delete:如果选择yes,当最后一个消费者不在监听Queue的时候,该Queue就会自动删除,一般选择false。
- Arguments:AMQP协议留给AMQP实现者扩展使用的。
x-message-ttl:一个消息推送到队列中的存活时间。设置的值之后还没消费就会被删除。
x-expires:在自动删除该队列的时候,可以使用该队列的时间。
x-max-length:在队列头部删除元素之前,队列可以包含多少个(就绪)消息,如果再次向队列中发送消息,会删除最早的那条消息,用来控制队列中消息的数量。
x-max-length-bytes:在队列头部删除元素之前,队列的总消息体的大小,用来控制队列中消息的总大小。
x-dead-letter-exchange:当消息被拒绝或者消息过期,消息重新发送到的交换机(Exchange)的可选名称。
x-dead-letter-routing-key:当消息被拒绝或者消息过期,消息重新发送到的交换机绑定的Route key的名称,如果没有设置则使用之前的Route key。
x-max-priority:队列支持的最大优先级数,如果没有设置则不支持消息优先级
x-queue-mode:将队列设置为延迟模式,在磁盘上保留尽可能多的消息以减少RAM使用; 如果未设置,队列将保持在内存中的缓存,以尽可能快地传递消息。
x-queue-master-locator:将队列设置为主位置模式,确定在节点集群上声明队列主节点所在的规则。
交换机和绑定
Exchange在RabbitMQ消息中间件中的作用:
服务器发送消息不会直接发送到队列中(Queue),而是直接发送给交换机(Exchange),然后根据确定的规则,RabbitMQ将会决定消息该投递到哪个队列。这些规则称为路由键(routing key),队列通过路由键绑定到交换机上。消息发送到服务器端(broker),消息也有自己的路由键(也可以是空),RabbitMQ也会将消息和消息指定发送的交换机的绑定(binding,就是队列和交互机的根据路由键映射的关系)的路由键进行匹配。如果匹配的话,就会将消息投递到相应的队列。协议中定义了不同的交换机,4种类型的交换机
- fanout
- direct
- topic
- headers
Fanout Exchange:直接将消息转发到所有binding的对应queue中,这种exchange在路由转发的时候,忽略Routing key。
Direct Exchange:将消息中的Routing key与该Exchange关联的所有Binding中的Routing key进行比较,如果相等,则发送到该Binding对应的Queue中。
Topic Exchange:将消息中的Routing key与该Exchange关联的所有Binding中的Routing key进行对比,如果匹配上了,则发送到该Binding对应的Queue中。
Headers Exchange:将消息中的headers与该Exchange相关联的所有Binging中的参数进行匹配,如果匹配上了,则发送到该Binding对应的Queue中。
- Virtual host:属于哪个Virtual host。
- Name:名字,同一个Virtual host里面的Name不能重复。
- Durability: 是否持久化,Durable:持久化。Transient:不持久化。
- Auto delete:当最后一个绑定(队列或者exchange)被unbind之后,该exchange自动被删除。
- Internal: 是否是内部专用exchange,是的话,就意味着我们不能往该exchange里面发消息。
- Arguments: 参数,是AMQP协议留给AMQP实现做扩展使用的。
alternate_exchange配置的时候,exchange根据路由路由不到对应的队列的时候,这时候消息被路由到指定的alternate_exchange的value值配置的exchange上。
Message详解
消息。服务器和应用程序之间传送的数据,本质上就是一段数据,由Properties和Payload(body)组成。
Delivery mode:是否持久化,如果未设置持久化,转发到queue中并未消费则重启服务或者服务宕机则消息丢失。
Headers:头信息,是由一个或多个健值对组成的,当固定的Properties不满足我们需要的时候,可以自己扩展。
Properties(属性)
content_type:传输协议
content_encoding:编码方式
priority:优先级
correlation_id:rpc属性,请求的唯一标识。
reply_to:rpc属性,
expiration:消息的过期时间
message_id:消息的id
timestamp:消息的时间戳
...
如何保证消息的不丢失,三个地方做到持久化。
- Exchange需要持久化。
- Queue需要持久化。
- Message需要持久化。
多租户模式:虚拟主机和隔离
每个RabbitMQ服务器都能创建虚拟消息服务器,我们称之为虚拟主机vhost,每个vhost的本质就是个mini版的RabbitMQ服务器,拥有自己的队列,交换器和绑定,更重要的是它还拥有自己的权限机制,可以做最小粒度的权限控制。能够安全的使用RabbitMQ服务器来服务众多的应用,vhost之于RabbitMQ,相当于虚拟机之于物理服务器:通过在各个实例之间提供的逻辑上的分离,允许不同应用程序安全的运行数据,这样的话可以将一个RabbitMQ的多个客户去分开,又可以避免队列和交换器命名冲突而不需要运行多个RabbitMQ
vhost是AMQP概念的基础,连接的时候进行指定,由于RabbitMQ包含了开箱即用的默认vhost,即“/”,如果不需要多个就使用默认的,默认的用户名和密码guest访问默认的vhost,当在rabbit里面创建要给用户的时候,用户通常被指定至少一个vhost,并且只能访问指定vhost的队列交换器和绑定,同时,当在RabbitMQ集群上创建vhost时,整个集群都会创建该vhost,vhost不仅消除了为基础架构中的每一层运行一个RabbitMQ服务器的需要,同时避免了为每一层创建不同的集群
如何创建vhost
无法使用AMQP协议创建(不同与队列交换机等),需要使用RabbitMQ安装路径下./sbin/目录中的rabbitmactl工具创建,运行rabbitmqtcl add_vhost [vhost_name]即可
删除:rabbitmqtcl delete_vhost [vhost_name]即可,vhost创建成功后我们可以添加队列和交换机,rabbitmqtcl list_vhosts查看所有vhost
注意:通常情况下直接在服务器上运行rabbitmqtcl来管理自己的rabbitmq节点,也可以通过制定 -n rabbit@[server_name]来管理远程的rabbitMQ节点
@符号左边是Erlang应用程序的名称,永远是rabbit,右边是服务器主机名或者IP

消息持久化
RabbitMQ创建的队列和交换器在默认情况下无法幸免于服务器重启,重启服务后,队列和交换机联通里面的消息就会消失
因为交换机和列队的默认durable=false,设置成true,就会避免重启或者宕机后队列和交换器的消失,但是消息还是会丢失
所以当把交换器和队列的durable设置成true还是不够的,还需要持久化消息,在消息发布之前,通过把它的投递模式delivery mode选项设置成2来吧消息标记成持久化,只有这2个条件同时满足才可以保证消息不会丢失
怎么做到消息持久化的?
RabbitMQ确保消息能从服务器中恢复的方式是:将他们写入磁盘上的一个持久化日志文件,当发布一条持久化的消息到持久化的交换机上,rabbit会在消息提交到日志文件后才发送响应,如果发送到非持久化的队列上,他会自动从持久性日志中移除导致无法恢复,还有如果一旦你从持久化队列中消费了一条持久化消息,并且确认了它,那么RabbitMQ会在持久化日志中把这条消息标记为等待垃圾收集,在你消费持久化消息前,如果rabbitMQ重启,服务器会自动重建交换器和队列以及绑定,重播持久性日志文件中的消息到合适的队列或交换机上,虽然持久化好,但是会影响性能,写入磁盘的比存入内存慢超级多,而且极大的减少RabbitMQ服务器每秒处理消息的总数。所以使用持久化机制而导致消息吞吐量降低至少10倍的情况并不少见。
此外持久化消息在RabbitMQ内建集群环境下工作的并不好,虽然RabbitMQ集群允许你和集群中的任何节点的任意队列通信,但是事实上这个队列是均匀分布在各个节点上而没有备份,所以一个队列所在的节点崩溃,在节点恢复之前没这个队列和这个节点的其他队列都是不可用的,而且持久化队列也无法重建,导致消息丢失
AMQP事务
在消息持久化到磁盘前,服务宕机可能导致消息丢失,这种情况持久化不能完全保证消息不丢失,在处理其他任务之前,必须保证代理收到消息并把消息路由给所有匹配的订阅队列,我们可以把这些行为包装到一个事务中,在AMQP中,把信道channel设置成事务模式之后,那么通过这个信道发送想要确认的消息,还有多个其他的AMQP命令,这些命令的执行还是忽略却取决于第一条消失是否发送成功,一旦完成所有命你就可以提交事务了,事务填补了生产者发送消息和RabbitMQ把消息提交到磁盘上这2个阶段丢失情况。
事务的缺点,就是影响RabbitMQ的性能,降低2-10倍的吞吐量,还会使生产者应用程序产生同步,而使用消息就是为了避免同步
所有有更好的方案来保证消息投递:发送方的确认模式,它和事务模式相似,使用发送方确认需要将信道channel设置成confirm模式(channel.confirmSelect();),而且只能通过重写创建信道来关闭该设置,一旦信道进入confirm模式,所有在信道上发布的消息都会被指派一个唯一的ID号(也就是deliveryTag,从1开始,后面的每一条消息都会加1,deliveryTag在channel范围内是唯一的。),一旦消息被投递到所有匹配的队列后,信道会发送一个发送方确认模式给生产者应用(包含消息的唯一ID),使得生产者知晓消息一经安全到达目的队列,如果消息和队列是持久化的,那么消息只会在队列将消息写入磁盘后才会发出,发送者确认模式的最大好处是它们是异步的,一旦发布了一个消息,生产者应用程序就可以在等待确认的同时继续发送下一条消息,当确认消息收到的时候,生产者应用的回调方法就会被触发来处理该确认消息,如果rabbit发生内部错误导致消息丢失,rabbit会发送一条nack(not acknowledged未确认)消息,就像发送方确认消息那样,只不过这一次说的是消息已经丢失,同时由于不像事务那样没有回滚,发送方确认模式更加轻量,对性能的影响几乎不计