Flume简单使用
Flume
apache版官网:http://flume.apache.org/
左侧边栏Documentation ==》中间界面的Flume User Guide 可进入最新版用户指导
需要老版本点 左侧边栏Documentation ==》中间最后一行的Releases,然后再选版本
flume简介:
distributed, reliable, and available service
collecting, aggregating, and moving large amounts of log data
分布式的海量日志的高效收集、聚合、移动/传输的框架
安装
下载,安装,配置环境变量$FLUME_HOME
在$FLUME_HOME/conf/flume-env.sh里配置好java路径
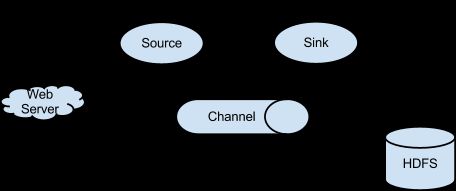
Flume核心组件
Source,Channel,Sink组成了最核心的组件Agent。
Flume三大核心组件
Source: exec/Spooling Directory/Taildir Source/NetCat
采集数据,将数据从产生的源头采集过来,输出到channel中
Channel: Memory/File
连接source和sink,类似于一个队列或者缓冲区
Sink: HDFS/Logger/Avro/Kafka
从Channel中获取数据,将数据写到目标目的地或
把数据写入到下一个Agent的Source中去
使用
flume安装目录下的bin目录,执行./flume-ng --help,打印出用户指导
Usage: ./flume-ng [options]...
commands:
help display this help text
agent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
global options:
--conf,-c use configs in directory
--classpath,-C append to the classpath
--dryrun,-d do not actually start Flume, just print the command
--plugins-path colon-separated list of plugins.d directories. See the
plugins.d section in the user guide for more details.
Default: $FLUME_HOME/plugins.d
-Dproperty=value sets a Java system property value
-Xproperty=value sets a Java -X option
agent options:
--name,-n the name of this agent (required)
--conf-file,-f specify a config file (required if -z missing)
--zkConnString,-z specify the ZooKeeper connection to use (required if -f missing)
--zkBasePath,-p specify the base path in ZooKeeper for agent configs
--no-reload-conf do not reload config file if changed
--help,-h display help text
avro-client options:
--rpcProps,-P RPC client properties file with server connection params
--host,-H hostname to which events will be sent
--port,-p port of the avro source
--dirname directory to stream to avro source
--filename,-F text file to stream to avro source (default: std input)
--headerFile,-R File containing event headers as key/value pairs on each new line
--help,-h display help text
Either --rpcProps or both --host and --port must be specified.
Note that if directory is specified, then it is always included first
in the classpath.
可以看出,想要执行命令,需要command和options,我们如果command选agent,那么options只需要选择全局的和agent特有的即可。
简单使用:
./flume-ng agent --name a1 --conf ../conf --conf-file ../conf/flume-conf.properties.template
在官网的用户指导里,详细的介绍了source、channel、sink的各种类型,需要哪种就可以把配置文件改成相对应的配置。
比如官网给的例子中,配置文件(命名为 example.conf)的内容可以:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
然后启动(flume根目录启动),注意agent命名为a1,需要和配置文件相同:
bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
然后在另一个命令行界面执行(需要安装telnet):
telnet localhost 44444
在这儿输入数据,在原来的界面就能看到相同的输出。
监控文件并写入HDFS
需求是监控文件,那么source就是exec,channel是内存memory,sink是hdfs。根据官网,配置文件(命名为exec-memory-hdfs.conf)可以是:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/data.log
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop000:8020/data/flume/tail
a1.sinks.k1.hdfs.batchSize = 10
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.cannel = c1
然后启动:
./flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-memory-hdfs.conf -Dflume.root.logger=INFO,console
在另一个界面/home/hadoop/data/目录下往data.log中输入数据:
执行十几次这个代码:
echo aaa >> data.log
可以看到原界面输出了信息,其中一个是把FlumeData.xxxx.tmp重命名成FlumeData.xxxx(命名规则可以参照官网hdfs sink修改)。然后到hdfs下查看,可以看到已经出现了那个文件,查看文件内容也和输入的一样。