数学推导+纯Python实现机器学习算法27:LDA线性判别分析
Python机器学习算法实现
Author:louwill
Machine Learning Lab
线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的线性分类方法。注意机器学习中还有一种用于NLP主题模型建模的潜在狄利克雷分布(Latent Dirichlet Allocation)也简称为LDA,大家在学习的时候注意区分。不同于上一讲谈到的PCA降维使用最大化方差的思想,LDA的基本思想是将数据投影到低维空间后,使得同一类数据尽可能接近,不同类数据尽可能疏远。所以,LDA是一种有监督的线性分类算法。
LDA原理与推导
下图描述了PCA和LDA直观上的区别。
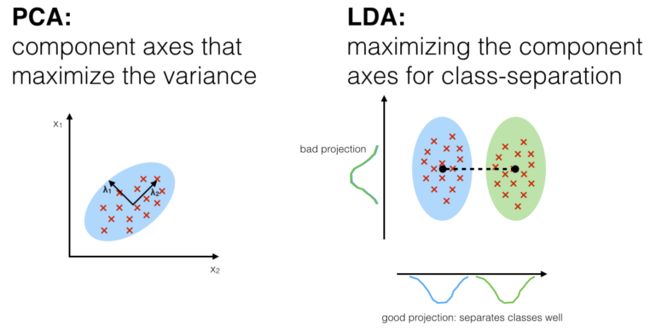
我们来看LDA的基本原理推导。给定数据集,其中 、 、 分别表示为第 类数据的集合、均值向量和协方差矩阵。假设将上述数据投影到直线 上,则两类样本的中心投射到直线上的投影分别为 和 ,考虑所有样本投射情况下,两类样本的协方差分别为 和 。由于直线 为一维空间,上述值均为实数。
现在我们的优化目标是使同类样本的投影点尽可能相近,异类样本投影点尽可能远离。要让同类样本的投影点尽可能相近,我们可以使同类样本投影点的协方差尽可能的小,即 尽可能小。异类样本投影点尽可能远离,可以使得类中心点之间的距离尽可能大,即 尽可能大。同时考虑这两个优化目标的情况下,我们可以定义最大化目标函数:
定义类内散度矩阵 : 定义类间散度矩阵 :
则上述优化目标可改写为:
上式即为LDA最终要优化的目标。现在问题在于我们要如何求出 。这里可以令 ,则上述优化式可表示为:
根据条件约束优化求解的拉格朗日乘子法,上式等于:
令
并代入到 可得:
考虑到 矩阵数值解的稳定性,我们可以对其进行奇异值分解,即:
最后求其逆即可得到 。
根据上述推导,我们可以整理LDA完整的算法流程为:
对数据按类别分组
分别计算每组样本的均值和协方差
计算类间散度矩阵
计算均值差
SVD方法计算类间散度矩阵 的逆
根据 计算 。
计算投影后的数据点
读者还可以自行考虑将LDA推广到多分类情况,这里不再展开推导。
LDA基本实现
按照前述LDA算法流程,我们可以给基于numpy来实现一个简单的LDA模型。基本关 键点包括计算分组均值与协方差、类间散度矩阵和SVD分解等。具体实现过程如下代 码所示:
import numpy as np
class LDA():
def __init__(self):
self.w = None
def calculate_covariance_matrix(self, X, Y=None):
# 计算协方差矩阵
m = X.shape[0]
X = X - np.mean(X, axis=0)
Y = X if Y == None else Y - np.mean(Y, axis=0)
return 1 / m * np.matmul(X.T, Y)
# 对数据进行向量转换
def transform(self, X, y):
self.fit(X, y)
X_transform = X.dot(self.w)
return X_transform
# LDA拟合过程
def fit(self, X, y):
# 按类划分
X0 = X[y == 0]
X1 = X[y == 1]
# 分别计算两类数据自变量的协方差矩阵
sigma0 = self.calculate_covariance_matrix(X0)
sigma1 = self.calculate_covariance_matrix(X1)
# 计算类内散度矩阵
Sw = sigma0 + sigma1
# 分别计算两类数据自变量的均值和差
u0, u1 = X1.mean(0), X2.mean(0)
mean_diff = np.atleast_1d(u0 - u1)
# 对类内散度矩阵进行奇异值分解
U, S, V = np.linalg.svd(Sw)
# 计算类内散度矩阵的逆
Sw_ = np.dot(np.dot(V.T, np.linalg.pinv(S)), U.T)
# 计算w
self.w = Sw_.dot(mean_diff)
# LDA分类预测
def predict(self, X):
y_pred = []
for sample in X:
h = sample.dot(self.w)
y = 1 * (h < 0)
y_pred.append(y)
return y_pred
本文只给出二分类的LDA的推导和基本实现,读者可自行将其推广到多分类的情形,这里不做过多展开。sklearn中为LDA算法提供了sklearn.lda.LDA接口可供调用,实际应用时直接调用该接口即可。
参考资料:
周志华 机器学习
往期精彩:
数学推导+纯Python实现机器学习算法26:PCA降维
数学推导+纯Python实现机器学习算法28:奇异值分解SVD
数学推导+纯Python实现机器学习算法29:马尔可夫链蒙特卡洛
数学推导+纯Python实现机器学习算法17:XGBoost
数学推导+纯Python实现机器学习算法13:Lasso回归
数学推导+纯Python实现机器学习算法10:线性不可分支持向量机
一个算法工程师的成长之路


长按二维码.关注机器学习实验室
喜欢您就点个在看!