数据挖掘实践学习一 数据集处理 未完待续
前言
8月份参加的DataWhale组织的组队学习活动,自以为是地报了MySQL,数据挖掘和爬虫,结果只有MySQL完成得还可以了,数据挖掘不厚道地随便搞了一下,蒙混过关,爬虫搞了一半最后被请出了群聊。
虽然没有完成,但好处保留了这些资料和高手们的聊天记录,现在想把没做完和做好的事情做完做好,可以照着别人的脚步,跟着做,这叫站在巨人的肩膀上。做的这些,当然都是为了一份工作。
第一部分是数据集处理,即拿到数据集后,对数据字段的意义和类型、数据的分布、以及数据的缺失值进行了解和分析,然后做相应的处理。
引用一位群友的总结,即这一部分包括:1、剔除无用的特征;2、缺失值的处理;3、异常值和离群值的处理;4、分类数据的编码;5、时间类特征的处理;6、其他特征的处理。
这一边日志,我主要进行数据值的处理,用python的数据可视化包展示一下数据的分布,这里也复习一下Matplotlib和seaborn,不然真的过去学的都忘了。至于时间类和其他特征处理,放在一下篇,专门学习一下特征工程。
数据集说明
这是DataWhale提供的一个金融数据集,数据集已经做了脱密处理。需要做的是预测用户的贷款是否会逾期。数据字段"status" 是结果标签:0表示未逾期,1表示逾期。
数据集将会三七分,三分测试集七分训练集。随机种子设置为2018。
导入常用的工具包
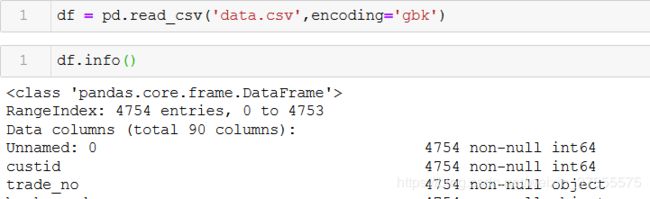
导入数据
导入数据并查看DataFrame结构:总共有4754行数据,90个字段。
字段分析
查看每个字段的唯一值有多少个,如果只有一个唯一值,那么这个字段特征没有什么用,如果字段的唯一值跟总数据行数相等,那么也是无关字段
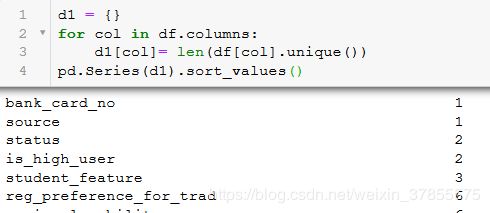
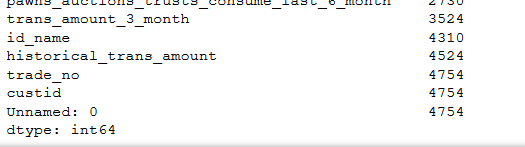
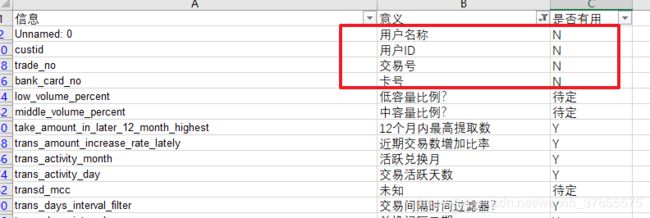
从以上可以看出,'bank_card_no','source','Unnamed: 0','custid','trade_no'是无用特征
接下来,对每个字段的意义进行探究,从常理上判断一个特征字段是否具有意义。
每个字段随机选取5个数查看
然后逐个看

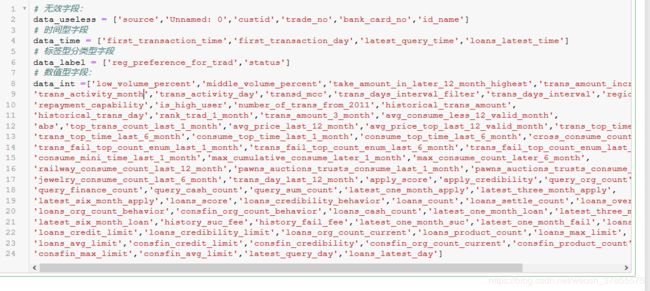
将字段分类
按照常理去掉一部分无效字段,比如卡号,客户姓名。一般日期信息应该主要用于做季节性趋势性分析,或这用户生命周期的分析,等进步一再看。
删除无用字段
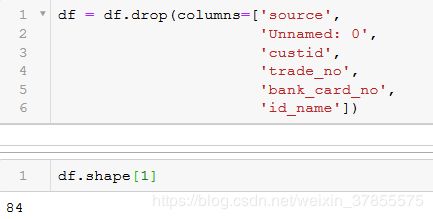
缺失值处理
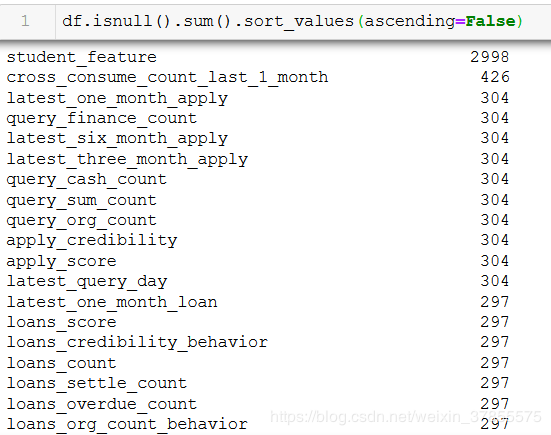
对每个字段的缺失值进行统计,再按缺失值数量大小排序:
或者通过计算缺失值的比例来看
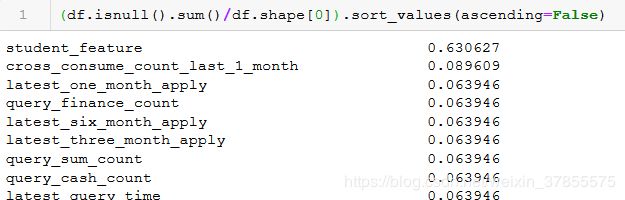
可见,student_feature 有2998个缺失值,缺失值占比63%,这个字段需要删掉。
![]()
对于缺失值的处理,这里参考一片文章:
http://blog.sina.com.cn/s/blog_1523c35670102xlcf.html
这里使用最填充法去处理缺失值,即填充均值,众数或者中位数。
一般来说,如果是数值型变量,若存在的变量值是正态分布则选择均值填充,若是偏态分布,则选择中位数填充;如果不是数值型变量,则选择众数填充。
由于均值又受到异常值和利群值的影响,所以先看看数值型的数据分布和离群数据。
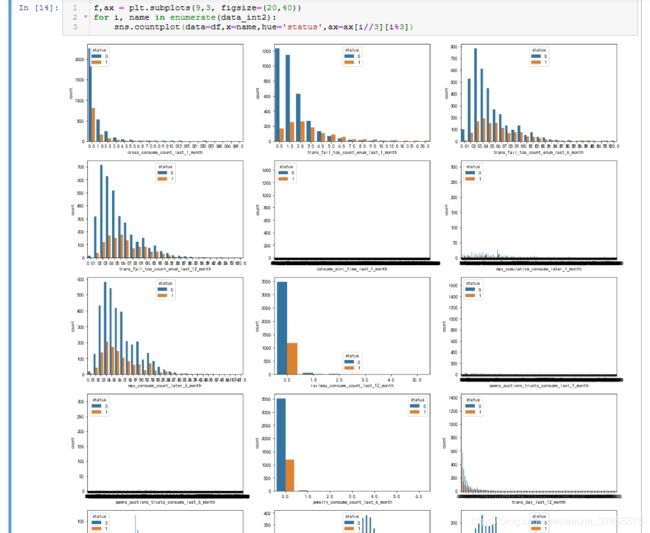
为了画图方便,这里将所有的数值型字段分层三部分:
![]()
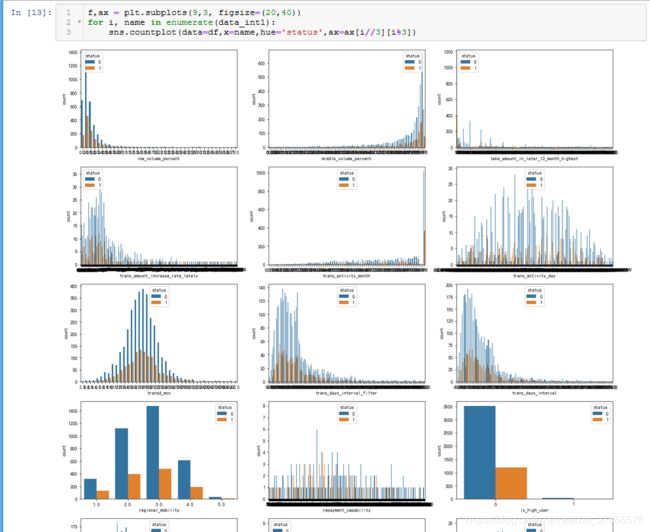
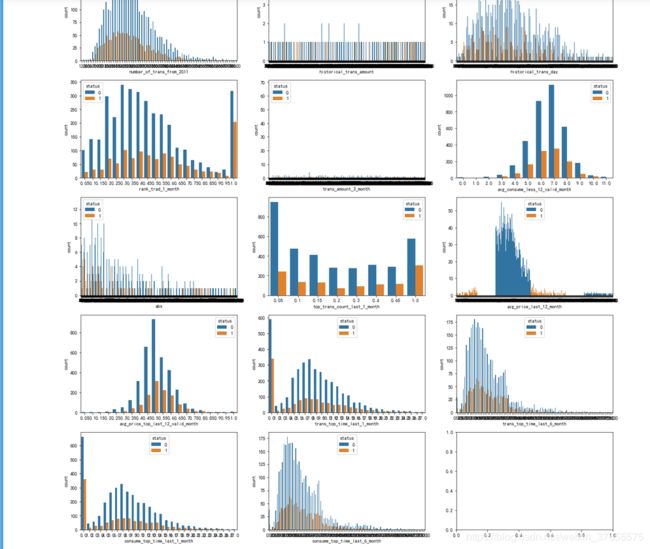
异常情况:16,23,25这三个图出现最左/最右暴增的情况,即data_int1[15,22,24] ==>> rank_trad_1_month, trans_top_time_last_1_month, consume_top_time_last_1_month。。。待以后进一步分析。
第21个图出现分段情况,即'avg_price_last_12_month'
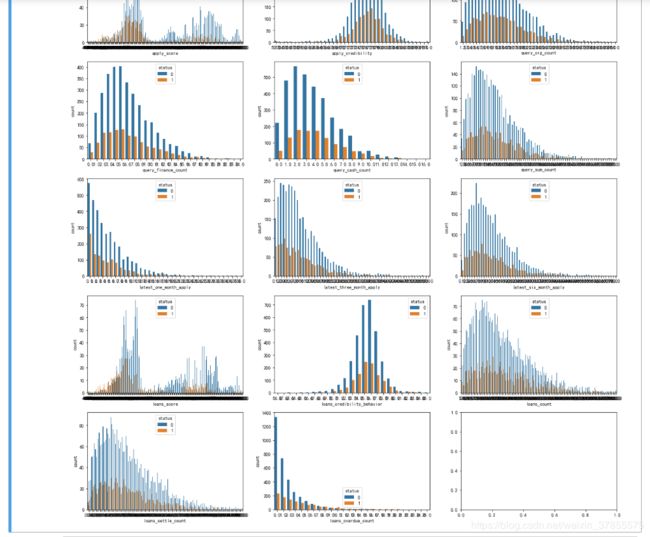
第二段没有特殊情况出现。
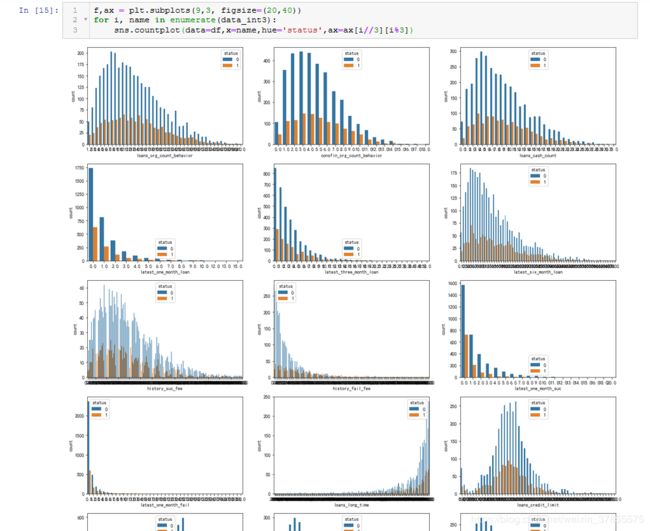
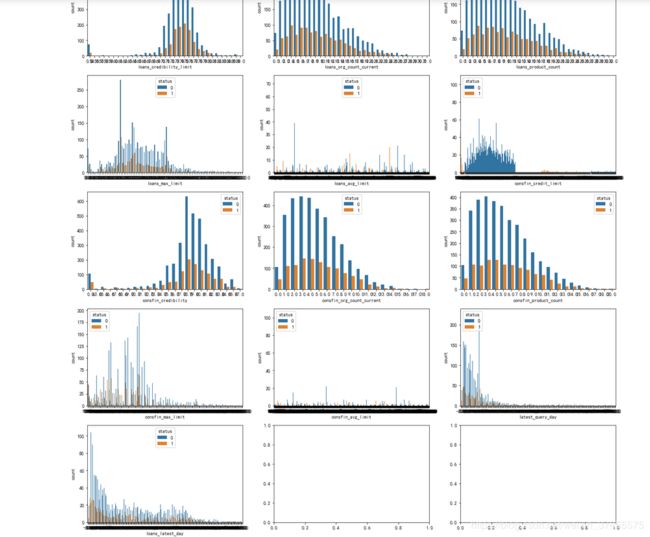
第18个图出现分段情况,即 'consfin_credit_limit'
对于出现分段情况的 'avg_price_last_12_month','consfin_credit_limit',很奇怪的是通过画大图分析,却没有看到它们分段的情况。。。暂时不去探究了。
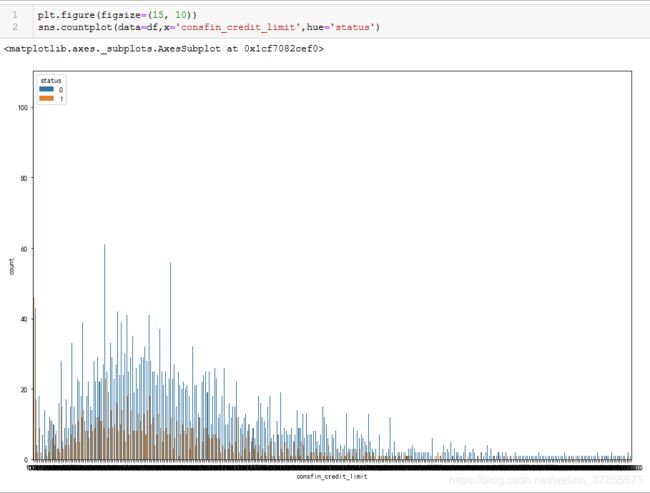
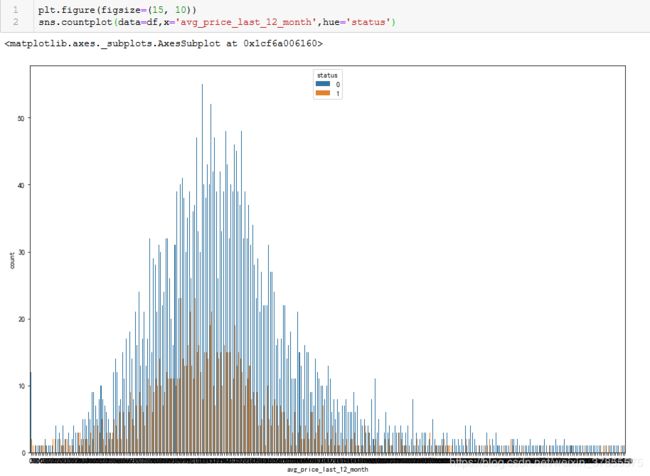
考虑以上图形基本都呈偏态分布,所以最后使用中位数对数值类型的缺失值进行填充。
接下的步骤:
填充数值类缺失值
对于时间日期类特征的分析,填充时间类缺失值
填充标签类缺失值
数据类型转换,将标签类型的字段转为数值类型,参考 https://zhuanlan.zhihu.com/p/87203369
--- 未完待续 ---