LAPGAN应用:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
本篇blog的内容基于原始论文Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks(NIPs2015)和《生成对抗网络入门指南》第六章。
基于cGAN的思想,这里的拉普拉斯对抗网络(LAPGAN)是在GAN基础上生成高质量图片,解决目前GAN生成数据质量差的问题。
一、拉普拉斯金字塔
1. 上采样和下采样
下采样:对原始图像的模糊和压缩。下采样为2的话,就是讲jxj的图像转化成j/2xj.2的大小。上采样同理。
2. 高斯金字塔
定义高斯金字塔为![]() ,
,![]() 为原始图像,之后每一个
为原始图像,之后每一个 ![]() 都是
都是 ![]() 的下采样,呈现一个从大到小的金字塔。
的下采样,呈现一个从大到小的金字塔。
3. 拉普拉斯金字塔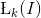
拉普拉斯金字塔的每一项是高斯金字塔的相邻两项之差。
![]()
![]() 表示上采样
表示上采样
二、 还原高清图像
![]() 的最后一项
的最后一项 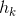 相当于像素不变,对原始图像的模糊,而 是图像在这一过程中的损失。通过模糊图像和拉普拉斯金字塔的参数和不断地上采样和差值补充,最终还原重建高清图像:
相当于像素不变,对原始图像的模糊,而 是图像在这一过程中的损失。通过模糊图像和拉普拉斯金字塔的参数和不断地上采样和差值补充,最终还原重建高清图像:
![]()
简而言之,就是先对原始图像下采样,然后再上采样,计算到他们的损失 ,也就是拉普拉斯金字塔。
三、 LAPGAN: Laplacian Generative Adversarial Networks
通过生成模型来产生拉帕拉斯金字塔系数
从生成器产生的最初的图片数据 ![]() ,经过一些列的基于条件的生成模型
,经过一些列的基于条件的生成模型 ![]() ,每一层都在生成对应的拉普拉斯金字塔系数
,每一层都在生成对应的拉普拉斯金字塔系数 ![]() ,而每一层的输出图像由 与
,而每一层的输出图像由 与 ![]() 相加而成。过程如图
相加而成。过程如图


从生成噪声 ![]() 和使用生成模型
和使用生成模型 ![]() 来生成
来生成 ![]() , 上采样生成
, 上采样生成 ![]() 并作为条件变量(橙色线)来生成模型
并作为条件变量(橙色线)来生成模型![]() 。然后和噪声
。然后和噪声 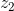 通过生成模型生成图像
通过生成模型生成图像 ![]() , 再和
, 再和 ![]() 一起生成
一起生成 ![]() ,上采样生成
,上采样生成 ![]() 。
。
可以看到绿线是上采样过程,橙线是生成模型根据噪声和上采样后的图像生成的过程
四、 LAPGAN结构

在图中的每一层都可以看作是一个单独训练的cGAN,其中每个网络的条件数据是根据真实图片经过上采样和下采样后的模糊图片。好处是很难产生“记忆”来训练数据,避免重复输出训练集中图片的问题。
五、实验室实验
-
论文一共使用了CIFAR10、STL10、LSUN三个数据集做实验
-
使用了原始GAN、LAPGAN以及class conditional LAPGAN生成图像对比

CC-LAPGAN是不仅将模糊图像作为条件,也将图片本身的分类信息作为条件输入,以此优化网络。
 LAPGAN逐层生成效果
LAPGAN逐层生成效果
六、LAPGAN代码
-
CIFAR-10数据集下载说明
import tensorflow as tf
import sys
sys.path.append('../')
# import tfutil as t
tf.set_random_seed(777)
# In image_utils, up/down_sampling
def image_sampling(img, sampling_type='down'):
shape = img.get_shape() # [batch, height, width, channels]
if sampling_type == 'down':
h = int(shape[1] // 2)
w = int(shape[2] // 2)
else: # 'up'
h = int(shape[1] * 2)
w = int(shape[2] * 2)
return tf.image.resize_images(img, [h, w], tf.image.ResizeMethod.BILINEAR)
class tfutil:
def conv2d(x, f=64, k=3, s=1, pad='SAME', reuse=None, is_train=True, name='conv2d'):
"""
:param x: input
:param f: filters
:param k: kernel size
:param s: strides
:param pad: padding
:param reuse: reusable
:param is_train: trainable
:param name: scope name
:return: net
"""
return tf.layers.conv2d(inputs=x,
filters=f, kernel_size=k, strides=s,
kernel_initializer=w_init,
kernel_regularizer=w_reg,
bias_initializer=b_init,
padding=pad,
reuse=reuse,
name=name)
def dense(x, f=1024, reuse=None, name='fc'):
"""
:param x: input
:param f: fully connected units
:param reuse: reusable
:param name: scope name
:param is_train: trainable
:return: net
"""
return tf.layers.dense(inputs=x,
units=f,
kernel_initializer=w_init,
kernel_regularizer=w_reg,
bias_initializer=b_init,
reuse=reuse,
name=name)
class LAPGAN:
def __init__(self, s, batch_size=128, height=32, width=32, channel=3, n_classes=10,
sample_num=10 * 10, sample_size=10,
z_dim=128, gf_dim=64, df_dim=64, d_fc_unit=512, g_fc_unit=1024):
"""
# General Settings
:param s: TF Session
:param batch_size: training batch size, default 128
:param height: input image height, default 32
:param width: input image width, default 32
:param channel: input image channel, default 3 (RGB)
:param n_classes: the number of classes, default 10
- in case of CIFAR, image size is 32x32x3(HWC), classes are 10.
# Output Settings
:param sample_size: sample image size, default 8
:param sample_num: the number of sample images, default 64
# Model Settings
:param z_dim: z noise dimension, default 128
:param gf_dim: the number of generator filters, default 64
:param df_dim: the number of discriminator filters, default 64
:param d_fc_unit: the number of fully connected filters used at Disc, default 512
:param g_fc_unit: the number of fully connected filters used at Gen, default 1024
"""
self.s = s
self.batch_size = batch_size
self.height = height
self.width = width
self.channel = channel
self.n_classes = n_classes
self.sample_size = sample_size
self.sample_num = sample_num
self.image_shape = [self.height, self.width, self.channel]
self.z_dim = z_dim
self.gf_dim = gf_dim
self.df_dim = df_dim
self.d_fc_unit = d_fc_unit
self.g_fc_unit = g_fc_unit
# Placeholders
self.y = tf.placeholder(tf.float32, shape=[None, self.n_classes],
name='y-classes') # one_hot
self.x1_fine = tf.placeholder(tf.float32, shape=[None, self.height, self.width, self.channel],
name='x-images')
self.x1_scaled = image_sampling(self.x1_fine, 'down')
self.x1_coarse = image_sampling(self.x1_scaled, 'up')
self.x1_diff = self.x1_fine - self.x1_coarse
self.x2_fine = self.x1_scaled # [16, 16]
self.x2_scaled = image_sampling(self.x2_fine, 'down')
self.x2_coarse = image_sampling(self.x2_scaled, 'up')
self.x2_diff = self.x2_fine - self.x2_coarse
self.x3_fine = self.x2_scaled # [8, 8]
self.z = []
self.z_noises = [32 * 32, 16 * 16, self.z_dim]
for i in range(3):
self.z.append(tf.placeholder(tf.float32,
shape=[None, self.z_noises[i]],
name='z-noise_{0}'.format(i)))
self.do_rate = tf.placeholder(tf.float32, None, name='do-rate')
self.g = [] # generators
self.g_loss = [] # generator losses
self.d_reals = [] # discriminator_real logits
self.d_fakes = [] # discriminator_fake logits
self.d_loss = [] # discriminator_real losses
# Training Options
self.d_op = []
self.g_op = []
self.beta1 = 0.5
self.beta2 = 0.9
self.lr = 8e-4
self.saver = None
self.merged = None
self.writer = None
self.bulid_lapgan() # build LAPGAN model
def discriminator(self, x1, x2, y, scale=32, reuse=None):
"""
:param x1: image to discriminate
:param x2: down-up sampling-ed images
:param y: classes
:param scale: image size
:param reuse: variable re-use
:return: logits
"""
assert (scale % 8 == 0) # 32, 16, 8
with tf.variable_scope('discriminator_{0}'.format(scale), reuse=reuse):
if scale == 8:
x1 = tf.reshape(x1, [-1, scale * scale * 3]) # tf.layers.flatten(x1)
h = tf.concat([x1, y], axis=1)
h = tfutil.dense(h, self.d_fc_unit, name='disc-fc-1')
h = tf.nn.relu(h)
h = tf.layers.dropout(h, 0.5, name='disc-dropout-1')
h = tfutil.dense(h, self.d_fc_unit // 2, name='d-fc-2')
h = tf.nn.relu(h)
h = tf.layers.dropout(h, 0.5, name='disc-dropout-2')
h = tfutil.dense(h, 1, name='disc-fc-3')
else:
x = x1 + x2
y = tfutil.dense(y, scale * scale, name='disc-fc-y')
y = tf.nn.relu(y)
y = tf.reshape(y, [-1, scale, scale, 1])
h = tf.concat([x, y], axis=3) # (-1, scale, scale, channel + 1)
h = tfutil.conv2d(h, self.df_dim * 1, 5, 1, pad='SAME', name='disc-conv2d-1')
h = tf.nn.relu(h)
h = tf.layers.dropout(h, 0.5, name='disc-dropout-1')
h = tfutil.conv2d(h, self.df_dim * 1, 5, 1, pad='SAME', name='disc-conv2d-2')
h = tf.nn.relu(h)
h = tf.layers.dropout(h, 0.5, name='disc-dropout-2')
h = tf.layers.flatten(h)
h = tfutil.dense(h, 1, name='disc-fc-2')
return h
def generator(self, x, y, z, scale=32, reuse=None, do_rate=0.5):
"""
:param x: images to fake
:param y: classes
:param z: noise
:param scale: image size
:param reuse: variable re-use
:param do_rate: dropout rate
:return: logits
"""
assert (scale % 8 == 0) # 32, 16, 8
with tf.variable_scope('generator_{0}'.format(scale), reuse=reuse):
if scale == 8:
h = tf.concat([z, y], axis=1)
h = tfutil.dense(h, self.g_fc_unit, name='gen-fc-1')
h = tf.nn.relu(h)
h = tf.layers.dropout(h, do_rate, name='gen-dropout-1')
h = tfutil.dense(h, self.g_fc_unit, name='gen-fc-2')
h = tf.nn.relu(h)
h = tf.layers.dropout(h, do_rate, name='gen-dropout-2')
h = tfutil.dense(h, self.channel * 8 * 8, name='gen-fc-3')
h = tf.reshape(h, [-1, 8, 8, self.channel])
else:
y = tfutil.dense(y, scale * scale, name='gen-fc-y')
y = tf.reshape(y, [-1, scale, scale, 1])
z = tf.reshape(z, [-1, scale, scale, 1])
h = tf.concat([z, y, x], axis=3) # concat into 5 dims
h = tfutil.conv2d(h, self.gf_dim * 1, 5, 1, name='gen-deconv2d-1')
h = tf.nn.relu(h)
h = tfutil.conv2d(h, self.gf_dim * 1, 5, 1, name='gen-deconv2d-2')
h = tf.nn.relu(h)
h = tfutil.conv2d(h, self.channel, 5, 1, name='gen-conv2d-3')
h = tf.nn.tanh(h)
return h
def bulid_lapgan(self):
# Generator & Discriminator
g1 = self.generator(x=self.x1_coarse, y=self.y, z=self.z[0], scale=32, do_rate=self.do_rate)
d1_fake = self.discriminator(x1=g1, x2=self.x1_coarse, y=self.y, scale=32)
d1_real = self.discriminator(x1=self.x1_diff, x2=self.x1_coarse, y=self.y, scale=32, reuse=True)
g2 = self.generator(x=self.x2_coarse, y=self.y, z=self.z[1], scale=16, do_rate=self.do_rate)
d2_fake = self.discriminator(x1=g2, x2=self.x2_coarse, y=self.y, scale=16)
d2_real = self.discriminator(x1=self.x2_diff, x2=self.x2_coarse, y=self.y, scale=16, reuse=True)
g3 = self.generator(x=None, y=self.y, z=self.z[2], scale=8, do_rate=self.do_rate)
d3_fake = self.discriminator(x1=g3, x2=None, y=self.y, scale=8)
d3_real = self.discriminator(x1=self.x3_fine, x2=None, y=self.y, scale=8, reuse=True)
self.g = [g1, g2, g3]
self.d_reals = [d1_real, d2_real, d3_real]
self.d_fakes = [d1_fake, d2_fake, d3_fake]
# Losses
with tf.variable_scope('loss'):
for i in range(len(self.g)):
self.d_loss.append(tfutil.sce_loss(self.d_reals[i], tf.ones_like(self.d_reals[i])) +
tfutil.sce_loss(self.d_fakes[i], tf.zeros_like(self.d_fakes[i])))
self.g_loss.append(tfutil.sce_loss(self.d_fakes[i], tf.ones_like(self.d_fakes[i])))
# Summary
for i in range(len(self.g)):
tf.summary.scalar('loss/d_loss_{0}'.format(i), self.d_loss[i])
tf.summary.scalar('loss/g_loss_{0}'.format(i), self.g_loss[i])
# Optimizer
t_vars = tf.trainable_variables()
for idx, i in enumerate([32, 16, 8]):
self.d_op.append(tf.train.AdamOptimizer(learning_rate=self.lr,
beta1=self.beta1, beta2=self.beta2).
minimize(loss=self.d_loss[idx],
var_list=[v for v in t_vars if v.name.startswith('discriminator_{0}'.format(i))]))
self.g_op.append(tf.train.AdamOptimizer(learning_rate=self.lr,
beta1=self.beta1, beta2=self.beta2).
minimize(loss=self.g_loss[idx],
var_list=[v for v in t_vars if v.name.startswith('generator_{0}'.format(i))]))
# Merge summary
self.merged = tf.summary.merge_all()
# Model Saver
self.saver = tf.train.Saver(max_to_keep=1)
self.writer = tf.summary.FileWriter('./model/', self.s.graph)from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import tensorflow as tf
import numpy as np
import sys
import time
sys.path.append('../')
import image_utils as iu
from datasets import DataIterator
from datasets import CiFarDataSet as DataSet
np.random.seed(1337)
results = {
'output': './gen_img/',
'model': './model/LAPGAN-model.ckpt'
}
train_step = {
'epoch': 200,
'batch_size': 64,
'logging_interval': 1000,
}
def main():
start_time = time.time() # Clocking start
# Training, test data set
ds = DataSet(height=32,
width=32,
channel=3,
ds_path='C:/Users/adward//Desktop/GAN_learning/chap6',
ds_name='cifar-10')
ds_iter = DataIterator(ds.train_images, ds.train_labels,
train_step['batch_size'])
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as s:
# LAPGAN model
model = LAPGAN(s, batch_size=train_step['batch_size'])
# Initializing variables
s.run(tf.global_variables_initializer())
# Load model & Graph & Weights
saved_global_step = 0
ckpt = tf.train.get_checkpoint_state('./model/')
if ckpt and ckpt.model_checkpoint_path:
model.saver.restore(s, ckpt.model_checkpoint_path)
saved_global_step = int(ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1])
print("[+] global step : %s" % saved_global_step, " successfully loaded")
else:
print('[-] No checkpoint file found')
sample_y = np.zeros(shape=[model.sample_num, model.n_classes])
for i in range(10):
sample_y[10 * i:10 * (i + 1), i] = 1
global_step = saved_global_step
start_epoch = global_step // (len(ds.train_images) // model.batch_size) # recover n_epoch
ds_iter.pointer = saved_global_step % (len(ds.train_images) // model.batch_size) # recover n_iter
for epoch in range(start_epoch, train_step['epoch']):
for batch_images, batch_labels in ds_iter.iterate():
batch_x = iu.transform(batch_images, inv_type='127')
z = []
for i in range(3):
z.append(np.random.uniform(-1., 1., [train_step['batch_size'], model.z_noises[i]]))
# Update D/G networks
img_fake, img_coarse, d_loss_1, g_loss_1, \
_, _, _, d_loss_2, g_loss_2, \
_, _, d_loss_3, g_loss_3, \
_, _, _, _, _, _ = s.run([
model.g[0], model.x1_coarse, model.d_loss[0], model.g_loss[0],
model.x2_fine, model.g[1], model.x2_coarse, model.d_loss[1], model.g_loss[1],
model.x3_fine, model.g[2], model.d_loss[2], model.g_loss[2],
model.d_op[0], model.g_op[0], model.d_op[1], model.g_op[1], model.d_op[2], model.g_op[2],
],
feed_dict={
model.x1_fine: batch_x, # images
model.y: batch_labels, # classes
model.z[0]: z[0], model.z[1]: z[1], model.z[2]: z[2], # z-noises
model.do_rate: 0.5,
})
# Logging
if global_step % train_step['logging_interval'] == 0:
batch_x = ds.test_images[np.random.randint(0, len(ds.test_images), model.sample_num)]
batch_x = iu.transform(batch_x, inv_type='127')
z = []
for i in range(3):
z.append(np.random.uniform(-1., 1., [model.sample_num, model.z_noises[i]]))
# Update D/G networks
img_fake, img_coarse, d_loss_1, g_loss_1, \
_, _, _, d_loss_2, g_loss_2, \
_, _, d_loss_3, g_loss_3, \
_, _, _, _, _, _, summary = s.run([
model.g[0], model.x1_coarse, model.d_loss[0], model.g_loss[0],
model.x2_fine, model.g[1], model.x2_coarse, model.d_loss[1], model.g_loss[1],
model.x3_fine, model.g[2], model.d_loss[2], model.g_loss[2],
model.d_op[0], model.g_op[0], model.d_op[1], model.g_op[1], model.d_op[2], model.g_op[2],
model.merged,
],
feed_dict={
model.x1_fine: batch_x, # images
model.y: sample_y, # classes
model.z[0]: z[0], model.z[1]: z[1], model.z[2]: z[2], # z-noises
model.do_rate: 0.,
})
# Print loss
d_loss = (d_loss_1 + d_loss_2 + d_loss_3) / 3.
g_loss = (g_loss_1 + g_loss_2 + g_loss_3) / 3.
print("[+] Epoch %03d Step %05d => " % (epoch, global_step),
" Avg D loss : {:.8f}".format(d_loss),
" Avg G loss : {:.8f}".format(g_loss))
# Training G model with sample image and noise
samples = img_fake + img_coarse
# Summary saver
model.writer.add_summary(summary, global_step) # time saving
# Export image generated by model G
sample_image_height = model.sample_size
sample_image_width = model.sample_size
sample_dir = results['output'] + 'train_{0}.png'.format(global_step)
# Generated image save
iu.save_images(samples, size=[sample_image_height, sample_image_width],
image_path=sample_dir,
inv_type='127')
# Model save
model.saver.save(s, results['model'], global_step)
global_step += 1
end_time = time.time() - start_time # Clocking end
# Elapsed time
print("[+] Elapsed time {:.8f}s".format(end_time))
# Close tf.Session
s.close()
if __name__ == '__main__':
main()
七、运行结果
生成的图片
训练50000次后

训练100000次后

训练150000次后

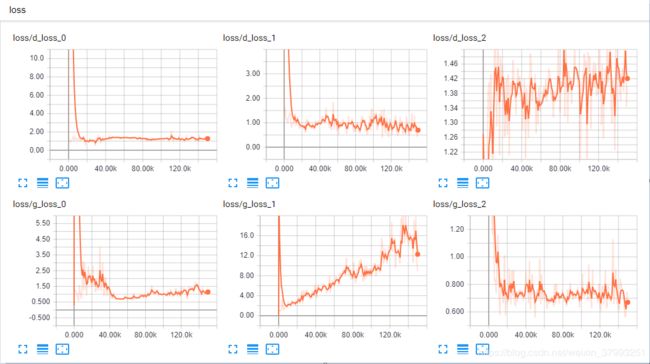
损失函数