Message Passing Interface(MPI)
一 定义
MPI和Openmp是常用的应用在CPU上的并行化框架。
MPI是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。
特点:
-
A partitioned address space 每个线程只能通过调用api去读取非本地数据。所有的交互(Non-local Memory)都需要协同进行(握手)。
-
Supports only explicit parallelization 只支持显性的并行化,用户必须明确的规定消息传递的方式。
二 最基本的操作Send & Receive
MPI所有的操作都是基于Send & Receive上进行的。
协议 Protocols For Send/Receive:
| Blocking Operations |
Non-Blocking Operations |
|
| Buffered |
Sending process returns after data has been copied into communication buffer |
Sending process returns after initiating DMA transfer to buffer. This operation may not be completed on return |
| Non-Buffered |
Sending process blocks until matching receive operation has been encountered |
None |
1)Blocking Non-Buffered Send/Receive:(握手)

死锁的发生Deadlocks in Blocking Non-Buffered Operations:

P0等待P1的recv,P1又在等待P0的recv,导致无休止的等待。
2) Blocking Buffered Send/Receive:
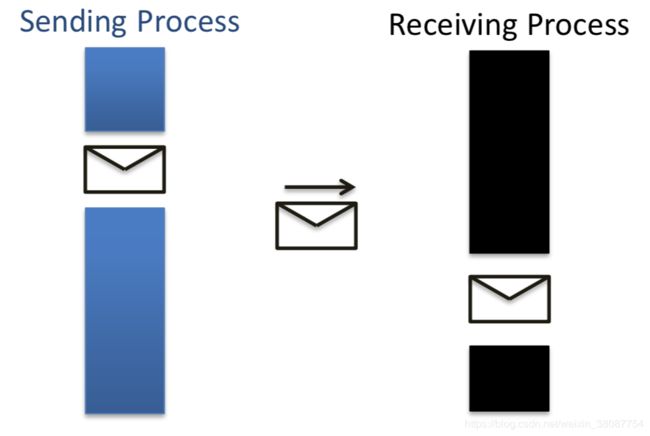
虽会缓解阻塞情况下idle time的情况,但如果buffer存满,依旧需要等待另一方的消耗掉存储的data。recv存满的话会通知sender不要再传了。
死锁的发生(概率很低):

会出现在p0和p1速度差异大,而且恰好都存在如上操作。而且根本原因是,Recv操作会一直阻塞为确保SC(semantic consistency)。
3)Non-Blocking Message Passing:
确保语义安全以后才会返回。通过check-status operation去确保。

三 Interface
初始化操作:
MPI_Init 只能调用一次。
如何设置rank数? 基于全局最大线程数量,自动设定的。
global environment setting "OMP_NUM_THREADS" for all your MPI processes
MPI_Finalize
MPI的都是建立在recv&send之上的,需要规定门牌号,往哪传,传什么。
1)Communication domain 和 rank (门牌号)
Communication domain:
Communication domain(变量名 MPI_Comm)规定了各个线程允许通信的范围。默认是MPI_COMM_WORLD,包含了所有的线程。可以自定义通信域,一个线程可以属于不同的通信域(存在overlap)。
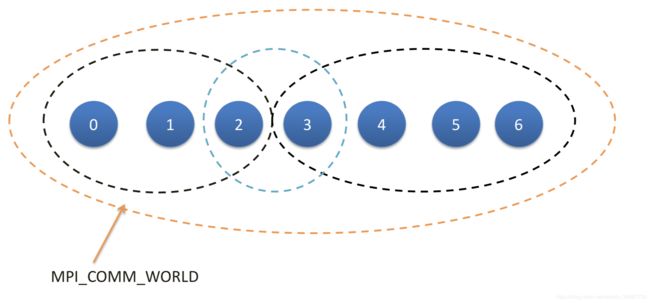
int MPI_Comm_size(MPI_Comm comm, int *size) 返回通信域的线程数
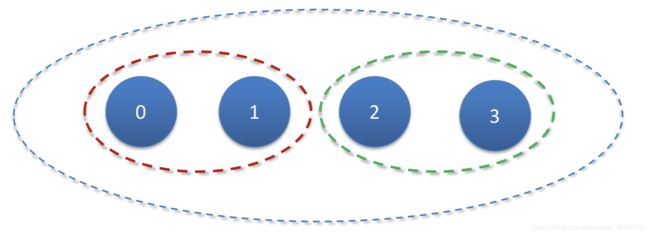
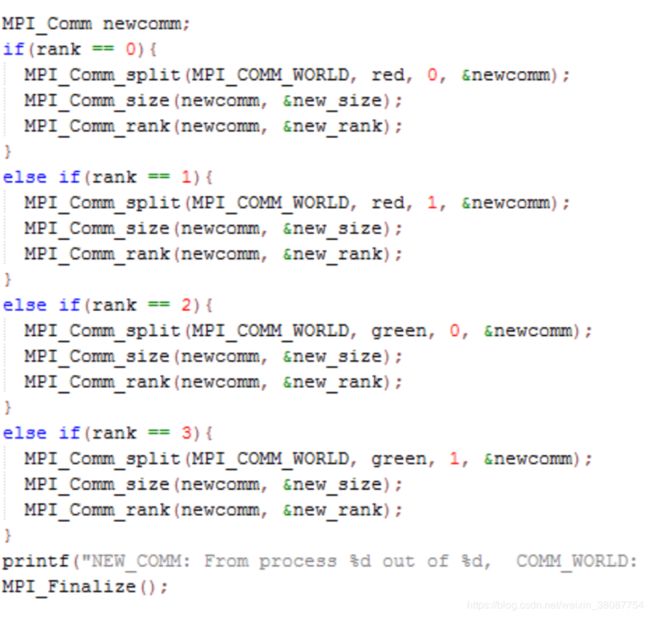
MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm *newcomm)对通信域的重新划分,要求原先通信域的所有线程都要显性的调用该函数去划分。每个线程给自己添加个颜色,API会匹配颜色来进行划分。
Code eg:

Rank:
The MPI_Comm_rank determines the label of the calling process
int MPI_Comm_rank(MPI_Comm comm, int *rank)返回一个整数(0 - 通信域的大小 - 1)
2)send&recv
Blocking:
-
int MPI_Send(void*buf,intcount,MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
-
int MPI_Recv(void*buf,intcount,MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
count: the number of entries in the buffer从buufer中取多少
tag:distinguish different messages对msg标记
Non-Blocking:
-
MPI_Isend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request)
-
MPI_Irecv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request)
非阻塞仅仅是完成请求就直接返回一个request obj,用于MPI_Test和MPI_Wait functionstrack该request是否完成。
3)组通信
Gather & Scatter:
Gather多对一:
MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype senddatatype, void *recvbuf, int recvcount, MPI_Datatype recvdatatype, int target, MPI_Comm comm)

每个process传送的data大小和类型必须相同。

Scatter(一对多):
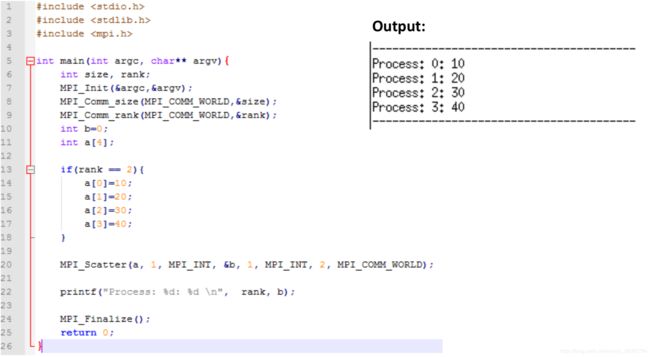
Broadcast & Reduction:
和上面两个不同的是,gather和scatter是发不同的数据,broadcast和reduction是发送相同数据。
MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int source, MPI_Comm comm)
从域内一个线程发送相同的内容到组内其他所有线程。

MPI_Reduce (void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int target, MPI_Comm comm)
需要注意的一点是,reduce包括target在内,全部都要进行reduce操作。

Barrier:
MPI_Barrier(MPI_Comm comm)
规定组内所有线程的同步点。