Apache Spark之架构概述(章节一)
作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy
背景介绍
Spark是一个快如闪电的统一分析引擎(计算框架)用于大规模数据集的处理。Spark在做数据的批处理计算,计算性能大约是Hadoop MapReduce的10~100倍,因为Spark使用比较先进的基于DAG 任务调度,可以将一个任务拆分成若干个阶段,然后将这些阶段分批次交给集群计算节点处理。
MapReduce VS Spark
MapReduce作为第一代大数据处理框架,在设计初期只是为了满足基于海量数据级的海量数据计算的迫切需求。自2006年剥离自Nutch(Java搜索引擎)工程,主要解决的是早期人们对大数据的初级认知所面临的问题。

整个MapReduce的计算实现的是基于磁盘的IO计算,随着大数据技术的不断普及,人们开始重新定义大数据的处理方式,不仅仅满足于能在合理的时间范围内完成对大数据的计算,还对计算的实效性提出了更苛刻的要求,因为人们开始探索使用Map Reduce计算框架完成一些复杂的高阶算法,往往这些算法通常不能通过1次性的Map Reduce迭代计算完成。由于Map Reduce计算模型总是把结果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延长。
2009年Spark在加州伯克利AMP实验室诞生,2010首次开源后该项目就受到很多开发人员的喜爱,2013年6月份开始在Apache孵化,2014年2月份正式成为Apache的顶级项目。Spark发展如此之快是因为Spark在计算层方面明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使用内存对数据做计算,而且计算的中间结果也可以缓存在内存中,这就为后续的迭代计算节省了时间,大幅度的提升了针对于海量数据的计算效率。

Spark也给出了在使用MapReduce和Spark做线性回归计算(算法实现需要n次迭代)上,Spark的速率几乎是MapReduce计算10~100倍这种计算速度。

不仅如此Spark在设计理念中也提出了One stack ruled them all战略,并且提供了基于Spark批处理至上的计算服务分支例如:实现基于Spark的交互查询、近实时流处理、机器学习、Grahx 图形关系存储等。
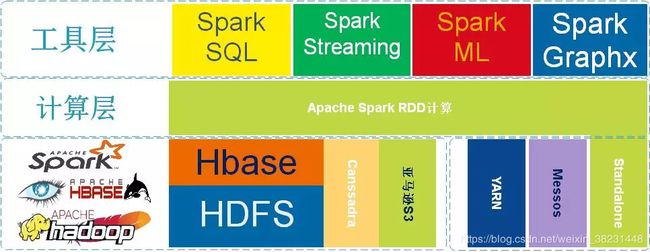
从图中不难看出Apache Spark处于计算层,Spark项目在战略上启到了承上启下的作用,并没有废弃原有以hadoop为主体的大数据解决方案。因为Spark向下可以计算来自于HDFS、HBase、Cassandra和亚马逊S3文件服务器的数据,也就意味着使用Spark作为计算层,用户原有的存储层架构无需改动。
计算流程
因为Spark计算是在MapReduce计算之后诞生,吸取了MapReduce设计经验,极大地规避了MapReduce计算过程中的诟病,先来回顾一下MapReduce计算的流程。
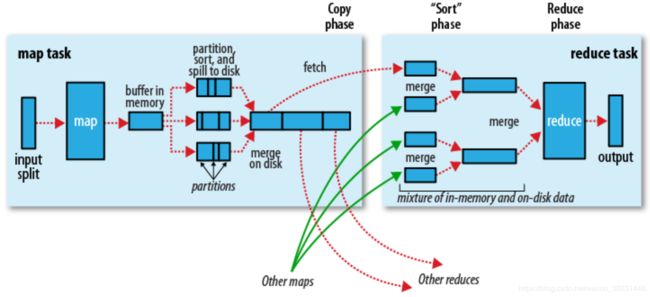
总结一下几点缺点:
1)MapReduce虽然基于矢量编程思想,但是计算状态过于简单,只是简单的将任务分为Map state和Reduce State,没有考虑到迭代计算场景。
2)在Map任务计算的中间结果存储到本地磁盘,IO调用过多,数据读写效率差。
3)MapReduce是先提交任务,然后在计算过程中申请资源。并且计算方式过于笨重。每个并行度都是由一个JVM进程来实现计算。
通过简单的罗列不难发现MapReduce计算的诟病和问题,因此Spark在计算层面上借鉴了MapReduce计算设计的经验,提出了DGASchedule和TaskSchedual概念,打破了在MapReduce任务中一个job只用Map State和Reduce State的两个阶段,并不适合一些迭代计算次数比较多的场景。因此Spark 提出了一个比较先进的设计理念,任务状态拆分,Spark在任务计算初期首先通过DGASchedule计算任务的State,将每个阶段的Sate封装成一个TaskSet,然后由TaskSchedual将TaskSet提交集群进行计算。可以尝试将Spark计算的流程使用一下的流程图描述如下:

相比较于MapReduce计算,Spark计算有以下优点:
1)智能DAG任务拆分,将一个复杂计算拆分成若干个State,满足迭代计算场景
2)Spark提供了计算的缓冲和容错策略,将计算结果存储在内存或者磁盘,加速每个state的运行,提升运行效率
3)Spark在计算初期,就已经申请好计算资源。任务并行度是通过在Executor进程中启动线程实现,相比较于MapReduce计算更加轻快。
目前Spark提供了Cluster Manager的实现由Yarn、Standalone、Messso、kubernates等实现。其中企业常用的有Yarn和Standalone方式的管理。
环境搭建
Hadoop环境
- 设置CentOS进程数和文件数(重启生效)
[root@CentOS ~]# vi /etc/security/limits.conf
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800
优化linux性能,修改这个最大值,重启CentOS
- 配置主机名(重启生效)
[root@CentOS ~]# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
[root@CentOS ~]# rebbot
- 设置IP映射
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.40.128 CentOS
- 防火墙服务
# 临时关闭服务
[root@CentOS ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# service iptables status
iptables: Firewall is not running.
# 关闭开机自动启动
[root@CentOS ~]# chkconfig iptables off
[root@CentOS ~]# chkconfig --list | grep iptables
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
- 安装JDK1.8+
[root@CentOS ~]# rpm -ivh jdk-8u171-linux-x64.rpm
[root@CentOS ~]# ls -l /usr/java/
total 4
lrwxrwxrwx. 1 root root 16 Mar 26 00:56 default -> /usr/java/latest
drwxr-xr-x. 9 root root 4096 Mar 26 00:56 jdk1.8.0_171-amd64
lrwxrwxrwx. 1 root root 28 Mar 26 00:56 latest -> /usr/java/jdk1.8.0_171-amd64
[root@CentOS ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source ~/.bashrc
- SSH配置免密
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
4b:29:93:1c:7f:06:93:67:fc:c5:ed:27:9b:83:26:c0 root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| |
| o . . |
| . + + o .|
| . = * . . . |
| = E o . . o|
| + = . +.|
| . . o + |
| o . |
| |
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.40.128)' can't be established.
RSA key fingerprint is 3f:86:41:46:f2:05:33:31:5d:b6:11:45:9c:64:12:8e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'centos,192.168.40.128' (RSA) to the list of known hosts.
root@centos's password:
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@CentOS ~]# ssh root@CentOS
Last login: Tue Mar 26 01:03:52 2019 from 192.168.40.1
[root@CentOS ~]# exit
logout
Connection to CentOS closed.
- 配置HDFS|YARN
将hadoop-2.9.2.tar.gz解压到系统的/usr目录下然后配置[core|hdfs|yarn|mapred]-site.xml配置文件。
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://CentOS:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}value>
property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>CentOS:50090value>
property>
<property>
<name>dfs.datanode.max.xcieversname>
<value>4096value>
property>
<property>
<name>dfs.datanode.handler.countname>
<value>6value>
property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>CentOSvalue>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
- 配置hadoop环境变量
[root@CentOS ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME
export CLASSPATH
export PATH
export M2_HOME
export MAVEN_OPTS
export HADOOP_HOME
[root@CentOS ~]# source .bashrc
- 启动Hadoop服务
[root@CentOS ~]# hdfs namenode -format # 创建初始化所需的fsimage文件
[root@CentOS ~]# start-dfs.sh
[root@CentOS ~]# start-yarn.sh
Spark环境
下载spark-2.4.1-bin-without-hadoop.tgz解压到/usr目录,并且将Spark目录修改名字为spark-2.4.1然后修改spark-env.sh和spark-default.conf文件.
- 配置Spark服务
[root@CentOS ~]# vi /usr/spark-2.4.1/conf/spark-env.sh
# Options read in YARN client/cluster mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
HADOOP_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
YARN_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
SPARK_EXECUTOR_CORES=2
SPARK_EXECUTOR_MEMORY=1G
SPARK_DRIVER_MEMORY=1G
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
export HADOOP_CONF_DIR
export YARN_CONF_DIR
export SPARK_EXECUTOR_CORES
export SPARK_DRIVER_MEMORY
export SPARK_EXECUTOR_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH=$(hadoop classpath):$SPARK_DIST_CLASSPATH
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs:///spark-logs"
[root@CentOS ~]# vi /usr/spark-2.4.1/conf/spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///spark-logs
在HDFS上创建
spark-logs目录,用于作为Sparkhistory服务器存储数据的地方。
- 启动Spark history server
[root@CentOS spark-2.4.1]# ./sbin/start-history-server.sh
- 访问
http://主机ip:18080访问Spark History Server

测试环境
[root@CentOS spark-2.4.1]# ./bin/spark-submit
--master yarn
--deploy-mode client
--class org.apache.spark.examples.SparkPi
--num-executors 2
--executor-cores 3
/usr/spark-2.4.1/examples/jars/spark-examples_2.11-2.4.1.jar
得到结果
19/04/21 03:30:39 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 6609 ms on CentOS (executor 1) (1/2)
19/04/21 03:30:39 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 6403 ms on CentOS (executor 1) (2/2)
19/04/21 03:30:39 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/04/21 03:30:39 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 29.116 s
19/04/21 03:30:40 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 30.317103 s
`Pi is roughly 3.141915709578548`
19/04/21 03:30:40 INFO server.AbstractConnector: Stopped Spark@41035930{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
19/04/21 03:30:40 INFO ui.SparkUI: Stopped Spark web UI at http://CentOS:4040
19/04/21 03:30:40 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
19/04/21 03:30:40 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
IDEA构建
Maven环境
- 创建Maven工程,添加以下插件
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>4.0.1version>
<executions>
<execution>
<id>scala-compile-firstid>
<phase>process-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.2version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
<executions>
<execution>
<phase>compilephase>
<goals>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
- 引入jar依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
WordCount代码
import org.apache.spark.{SparkConf, SparkContext}
object WordCountDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("word-count")
.setMaster("yarn")
val sc = new SparkContext(conf)
sc.textFile("hdfs:///demo/words/")
.flatMap(line=>line.split("\\W+"))
.map(word=>(word,1))
.reduceByKey((v1,v2)=>v1+v2)
.collect()
.foreach(println)
sc.stop()
}
}
在HDFS上传测试数据
[root@CentOS ~]# vi words.txt
this is a demo
welcome learn spark
good good study
day day up
[root@CentOS ~]# hdfs dfs -mkdir -p /demo/words/
[root@CentOS ~]# hdfs dfs -put words.txt /demo/words/
将以上代码使用
package指令打包生成spark-rdd-1.0-SNAPSHOT.jar,上传到Spark集群,运行如下脚本
[root@CentOS spark-2.4.1]# ./bin/spark-submit --master yarn --deploy-mode client --num-executors 2 --executor-cores 3 --class com.jiangzz.demo01.WordCountDemo /root/spark-rdd-1.0-SNAPSHOT.jar
等待片刻
(learn,1)
(this,1)
(is,1)
(day,2)
(welcome,1)
(up,1)
(spark,1)
(a,1)
(demo,1)
(good,2)
(study,1)
查看http://ip:18080查看任务执行的DAG图。

本地仿真
为了方便测试Spark的计算,Spark提供了本地仿真测试,也就是说任务不需要提交给Spark集群,直接在本地测试效果即可。
val conf = new SparkConf()
.setAppName("word-count")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("file:///D:/demo/words")
.flatMap(line=>line.split("\\W+"))
.map(word=>(word,1))
.reduceByKey((v1,v2)=>v1+v2)
.collect()
.foreach(println)
sc.stop()
Spark Shell
除了使用spark-submit来实现任务提交,也Spark提供了一个更具备交互的操作,用户可以使用spark shell直接测试Spark交互脚本。
[root@CentOS spark-2.4.1]# ./bin/spark-shell --master yarn --deploy-mode client --num-executors 2 --executor-cores 3
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/04/21 05:22:34 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://CentOS:4040
Spark context available as 'sc' (master = yarn, app id = application_1555787247306_0004).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.1
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("hdfs:///demo/words").flatMap(line => line.split("\\W+")).map(word=>(word,1)).reduceByKey((v1,v2)=> v1+v2).collect()
如果用户只是为了测试Spark逻辑用户也可以使用spark-shell运行在local模式下
[root@CentOS spark-2.4.1]# ./bin/spark-shell --master local --deploy-mode client --num-executors 2 --executor-cores 3
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://CentOS:4040
Spark context available as 'sc' (master = local, app id = local-1555798100615).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.1
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("hdfs:///demo/words").flatMap(line => line.split("\\W+")).map(word=>(word,1)).reduceByKey((v1,v2)=> v1+v2).collect()
res0: Array[(String, Int)] = Array((learn,1), (up,1), (this,1), (spark,1), (is,1), (a,1), (day,2), (demo,1), (good,2), (welcome,1), (study,1))
scala>
更多精彩内容关注
