Apache Kafka Stream
Kafka Streams
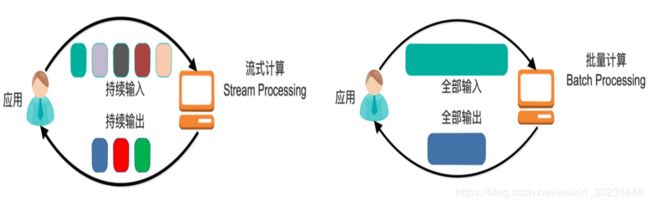
流计算定义
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。批量处理模型中,一般先有全量数据集,然后定义计算逻辑,并将计算应用于全量数据。特点是全量计算,并且计算结果一次性全量输出。
Kafka Stream
Kafka Streams是一个客户端库,用于处理和分析存储在Kafka中的数据。它建立在重要的流处理概念之上,正确区分EventTime和ProcessTime,Widows计算,可以实现对应用状态高效管理和实时查询。Kafka Streams进入门槛低。可以在单机上验证流处理的概念。同时可以利用Kafka的并行加载模型,实现流处理并行扩展,也就意味着用户只需要将自己流处理程序运行多份即可达到并行计算的目的。
Kafka Streams优点:简单、轻巧易部署、无缝对接Kafka、基于分区实现计算并行、基于幂等和事务特性实现精确计算、单个记录毫秒级延迟计算-实时性高、提供了两套不同风格的流处理API-(High level-Domain Specific Language|DSL开箱即用;low-level Processor API.)
名词解析
Topology:表示一个流计算任务,等价于MapReduce中的job。不同的是MapReduce的job作业最终会停止,但是Topology会一直运行在内存中,除非人工关闭该Topology。
stream:它代表了一个无限的,不断更新的Record数据集。流是有序,可重放和容错的不可变数据记录序列,其中数据记录被定义为键值对。
所谓的流处理是通过Topology编织程序对stream中Record元素的处理的逻辑/流程。这种计算和早期MapReduce计算的最大差异是该计算的实时性比较高,可以满足绝大多数的实时计算场景。Kafka Stream以它的轻量级、容易部署、低延迟等特点在微服务领域相比较 专业的 Storm、spark streaming和Flink 而言有着不可替代的优势。有关Storm、SparkStreaming和Flink的内容随着课程的深入会在后续章节再展开讨论。
架构
Kafka Streams通过构建Kafka生产者和消费者库并利用Kafka的本机功能来提供数据并行性,分布式协调,容错和操作简便性,从而简化了应用程序开发。
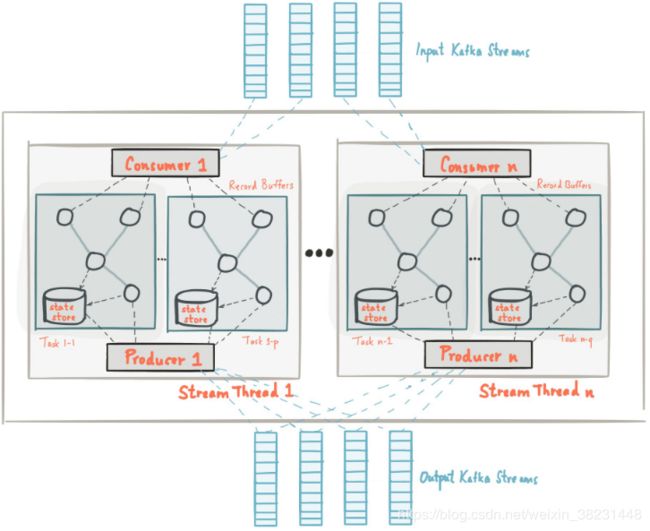
Kafka的消息分区用于存储和传递消息, Kafka Streams对数据进行分区以进行处理。 Kafka Streams使用partition和Task的概念作为基于Kafka Topic分区的并行模型的逻辑单元。在并行化的背景下,Kafka Streams和Kafka之间有着密切的联系:
- 每个stream分区都是完全有序的数据记录序列,并映射到Kafka Topic分区。
- stream中的数据记录映射到该Topic的Kafka消息。
- 数据记录的key决定了Kafka和Kafka Streams中数据的分区,即数据如何路由到Topic内的特定分区。
任务并行度
应用程序的处理器Topology通过将其分解为多个Task来扩展。更具体地说,Kafka Streams基于应用程序的输入流分区创建固定数量的任务,每个任务分配来自输入流的分区列表。分区到任务的分配永远不会改变,因此每个任务都是应用程序的固定平行单元。然后,任务可以根据分配的分区实例化自己的Topology;它们还为每个分配的分区维护一个缓冲区,并从这些记录缓冲区一次一个地处理消息。因此,流任务可以独立并行地处理,无需人工干预。
用户可以启动多个KafkaStream实例,这样等价启动了多个Stream Tread,每个Thread处理1~n个Task。一个Task对应一个分区,因此Kafka Stream流处理的并行度不会超越Topic的分区数。需要值得注意的是Kafka的每个Task都维护这自身的一些状态,线程之间不存在状态共享和通信。因此Kafka在实现流处理的过程中扩展是非常高效的。
容错
Kafka Streams构建于Kafka本地集成的容错功能之上。 Kafka分区具有高可用性和复制性;因此当流数据持久保存到Kafka时,即使应用程序失败并需要重新处理它也可用。 Kafka Streams中的任务利用Kafka消费者客户端提供的容错功能来处理故障。如果任务运行的计算机故障了,Kafka Streams会自动在其余一个正在运行的应用程序实例中重新启动该任务。
此外,Kafka Streams还确保local state store也很有力处理故障容错。对于每个state store,Kafka Stream维护一个带有副本changelog的Topic,在该Topic中跟踪任何状态更新。这些changelog Topic也是分区的,该分区和Task是一一对应的。如果Task在运行失败并Kafka Stream会在另一台计算机上重新启动该任务,Kafka Streams会保证在重新启动对新启动的任务的处理之前,通过重播相应的更改日志主题,将其关联的状态存储恢复到故障之前的内容。
实战编程
所有资料均参考:https://kafka.apache.org/22/documentation/streams/developer-guide/
Processor API
Processor API允许开发人员定义和连接自定义Processor并与state store进行交互。使用Processor API,可以定义一次处理一个接收record的任意流处理器,并将这些处理器与其关联的状态存储连接起来,以组成代表自定义处理逻辑的处理器拓扑。
Stream Processor是流处理Topology中的节点,表示单个处理步骤。使用Processor API,您可以定义一次处理一个接收记录的任意流处理器,并将这些处理器与其关联的状态存储连接以组成处理器拓扑。可以通过实现Processor接口来定义自定义流处理器,该接口提供process()API方法。在每个接收的记录上调用process()方法。
public interface Processor<K, V> {
void init(ProcessorContext context);
void process(K key, V value);
void close();
}
WordCountProcessor
public class WordCountProcessor implements Processor<String,String> {
private ProcessorContext context;
private KeyValueStore<String, Long> kvStore;
@Override
public void init(ProcessorContext context) {
this.context=context;
kvStore = (KeyValueStore) context.getStateStore("Counts");
//定时调用,并且数据传入到下游
this.context.schedule(Duration.ofSeconds(15),
PunctuationType.WALL_CLOCK_TIME, (long timestamp)->{
System.out.println("schedule :"+ new Date().toString());
KeyValueIterator<String, Long> iter = this.kvStore.all();
while (iter.hasNext()) {
KeyValue<String, Long> entry = iter.next();
context.forward(entry.key, entry.value);
}
iter.close();
context.commit();
});
}
@Override
public void process(String key, String value) {
String[] words = value.split("\\W+");
for (String word : words) {
Long count= 0L;
if(kvStore.get(word)!=null){
count = kvStore.get(word);
}
kvStore.put(word,count+1);
}
}
@Override
public void close() {
}
}
Properties props=new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "CentOS:9092,CentOS:9093,CentOS:9094");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//构建拓扑
Topology topology=new Topology();
Map<String, String> changelogConfig = new HashMap();
changelogConfig.put("min.insync.replicas", "1");
changelogConfig.put("cleanup.policy","compact");
//创建state,存储状态信息
StoreBuilder<KeyValueStore<String, Long>> countStore = Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("Counts"),
Serdes.String(),
Serdes.Long())
.withLoggingEnabled(changelogConfig);
//构建计算拓扑
topology.addSource("s1","topic01")
.addProcessor("p1",()-> new WordCountProcessor(), "s1")
.addStateStore(countStore,"p1")
.addSink("sk1","wordcount",
new StringSerializer(),new LongSerializer(),"p1");
//提交计算流程
KafkaStreams kafkaStreams=new KafkaStreams(topology,props);
kafkaStreams.start();
如果运行失败抛出 错误请自行安装:https://download.microsoft.com/download/9/3/F/93FCF1E7-E6A4-478B-96E7-D4B285925B00/vc_redist.x64.exe 插件,以为内系统默认会使用RocksDB在本地应用对数据状态做持久化,在做持久化的时候系统会调用本地的rockdb.dll动态链接库做本地实现,如果电脑上没有安装vc_redist.x64.exe,会导致java无法调用rockdbjni导致程序报错。
Streams DSL(重点)
Kafka Streams DSL(Domain Specific Language)构建于Streams Processor API之上。它是大多数用户推荐的,特别是初学者。大多数数据处理操作只能用几行DSL代码表示。在 Kafka Streams DSL 中有这么几个概念
- KStream:表示数据流,所有的在topic中的记录被认定为是一个INSERT操作。
- KTable:表示changelog数据流,每一则记录被解释称为一个update,如果你要将KTable存储到Kafka topic中,你可能想要启用Kafka的日志压缩功能,例如:节省存储空间。但是,在KStream的情况下启用日志压缩是不安全的,因为只要日志压缩开始清除相同key的旧数据记录,就会破坏数据的语义。KTable还提供了按key查找数据记录的当前value的功能。此表查找功能可通过join操作以及“交互式查询”获得。
KStream是一个数据流,可以认为所有记录都通过Insert only的方式插入进这个数据流里。而KTable代表一个完整的数据集,可以理解为数据库中的表。由于每条记录都是Key-Value对,这里可以将Key理解为数据库中的Primary Key,而Value可以理解为一行记录。可以认为KTable中的数据都是通过Update only的方式进入的。如果KTable对应的Topic中新进入的数据的Key已经存在,那么从KTable只会取出同一Key对应的最后一条数据,相当于新的数据更新了旧的数据。
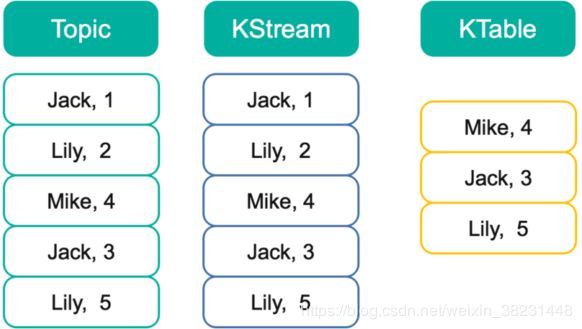
以上图为例,假设有一个KStream和KTable,基于同一个Topic创建,并且该Topic中包含如下图所示5条数据。此时遍历KStream将得到与Topic内数据完全一样的所有5条数据,且顺序不变。而此时遍历KTable时,因为这5条记录中有3个不同的Key,所以将得到3条记录,每个Key对应最新的值,并且这三条数据之间的顺序与原来在Topic中的顺序保持一致。
GlobalKTable:和KTable类似,不同点在于KTable只能表示一个分区的信息,但是GlobalKTable表示的是全局 的状态信息。
构建Source Stream
- KStream
StreamsBuilder builder = new StreamsBuilder();
KStream wordCounts = builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.Long() /* value serde */
));
Transformations(stateless)
Branch
KStream<String, String>[] branches = builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
)
)
.branch(
(k, v) -> v.contains("login"),
(k, v) -> v.contains("cart"),
(k, v) -> true
);
KStream<String, String> loginStream = branches[0];
KStream<String, String> cartStream = branches[1];
KStream<String, String> otherStream = branches[2];
Filter
过滤满足条件的数据,将满足条件的结果向后传递,该方法类似的方法还有filterNot
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.filter((k,v)->v.contains("login"))
.peek((k,v)-> System.out.println(k+" ->" +v));
filterNot
指定排除策略,将满足条件的记录过滤掉。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.filterNot((k,v)->v.contains("login"))
.peek((k,v)-> System.out.println(k+" ->" +v));
fatMap
获取一条记录并生成零个,一个或多个记录。您可以修改记录键和值,包括其类型。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMap((String key, String value) -> {
List<KeyValue<String, Integer>> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(new KeyValue<>(token,1));
}
return result;
}
)
.peek((k,v)-> System.out.println(k+" ->" +v));
flatMapValues
获取一条记录并生成零个,一个或多个记录,同时保留原始记录的key。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.print(Printed.toSysOut());
foreach
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.foreach(((key, value) -> System.out.println(key +"\t"+value)));
groupByKey
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMap((String key, String value) -> {
List<KeyValue<String, Integer>> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(new KeyValue<>(token,1));
}
return result;
}
)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
)
)
.reduce((v1,v2)->v1+v2)
.toStream()
.print(Printed.toSysOut());
groupBy
等价于selectKey(…).groupByKey()
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMap((String key, String value) -> {
List<KeyValue<String, Integer>> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(new KeyValue<>(token,1));
}
return result;
}
)
.groupBy((key,value)->key,Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.reduce((v1,v2)->v1+v2)
.toStream()
.print(Printed.toSysOut());
map
获取一条记录并生成一条记录。您可以修改记录键和值,包括其类型。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<String>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.map((k,v)-> new KeyValue<>(v,1))
.groupBy((key,value)->key,Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.reduce((v1,v2)->v1+v2)
.toStream()
.print(Printed.toSysOut());
mapValues
获取一条记录并生成一条记录,同时保留原始记录的key。您可以修改记录值和值类型。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.mapValues((v)-> v+"_hello")
.print(Printed.toSysOut());
Merge
将两个流的记录合并为一个较大的流。要求流中的数据必须key,value保持一致。
KStream<String, String> stream1 = builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
));
KStream<String, String> stream2 = builder.stream(
"topic02", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
));
stream1.merge(stream2).print(Printed.toSysOut());
Peek
通常用于debug调试,不会影响后续流的处理,类似foreach但是foreach表示流处理的截止,数据流不会向后传递。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.peek((k,v)-> System.out.println(k+"\t"+v))
.filter((k,v)->v.contains("login"))
.peek((k,v)-> System.out.println(k+" ->" +v));
SelectKey
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.print(Printed.toSysOut());
Transformations(Stateful)
有状态Transformation依赖于处理输入和生成输出的状态,并且需要与流处理器相关联的state store。例如,在aggregating 操作中,window state store用于收集每个window的最新聚合结果。在join操作中,窗口状态存储用于收集到目前为止在定义的window边界内接收的所有记录。状态存储是容错的。如果发生故障,Kafka Streams保证在恢复处理之前完全恢复所有状态存储。
DSL中可用的有状态转换包括:
- Aggregating
- Joining
- Windowing (as part of aggregations and joins)
- Applying custom processors and transformers, which may be stateful, for Processor API integration
下图显示了它们之间的关系:

aggregate
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.aggregate(
() -> 0, //初始值
(key,value,agg)-> value+agg,//局部计算
Materialized., Integer, KeyValueStore<Bytes, byte[]>>as("word-counts-store")
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Integer())
)
.toStream()
.print(Printed.toSysOut());
Reduce
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.reduce((v1,v2)->v1+v2,
Materialized.,Integer,KeyValueStore<Bytes,byte[]>>as("reduce-word-count")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Integer()
)
)
.toStream()
.print(Printed.toSysOut());
Window
Window使用户可以控制如何将具有相同键的记录分组,以进行有状态操作,例如aggregate或join等。
DSL支持以下类型的窗口:
| Window name | Behavior | Short description |
|---|---|---|
| Tumbling time window | Time-based | Fixed-size, non-overlapping, gap-less windows |
| Hopping time window | Time-based | Fixed-size, overlapping windows |
| Sliding time window | Time-based | Fixed-size, overlapping windows that work on differences between record timestamps |
| Session window | Session-based | Dynamically-sized, non-overlapping, data-driven windows |
Tumbling time windows
翻滚窗口将流元素按照固定的时间间隔,拆分成指定的窗口,窗口和窗口间元素之间没有重叠。在下图不同颜色的record表示不同的key。可以看是在时间窗口内,每个key对应一个窗口。

StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.windowedBy(TimeWindows.of(Duration.ofSeconds(5)))
.reduce((v1,v2)->v1+v2,
Materialized.,Integer, WindowStore<Bytes,byte[]>>as("reduce-w-window-count")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Integer()
)
)
.toStream()
.print(Printed.toSysOut());
Hopping time windows
Hopping time windows是基于时间间隔的窗口。他们模拟固定大小的(可能)重叠窗口。跳跃窗口由两个属性定义:窗口大小和其提前间隔(又名“hop”)。

StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.windowedBy(TimeWindows.of(Duration.ofSeconds(5))
.advanceBy(Duration.ofSeconds(1)))
.reduce((v1,v2)->v1+v2,
Materialized.,Integer, WindowStore<Bytes,byte[]>>as("reducewindow-w-count")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Integer()
)
)
.toStream()
.print(Printed.toSysOut());
Sliding Window
窗口只用于2个KStream进行Join计算时。该窗口的大小定义了Join两侧KStream的数据记录被认为在同一个窗口的最大时间差。假设该窗口的大小为5秒,则参与Join的2个KStream中,记录时间差小于5的记录被认为在同一个窗口中,可以进行Join计算。
Session Windows
Session Windows用于将基于key的事件聚合到所谓的会话中,其过程称为session化。会话表示由定义的不活动间隔(或“空闲”)分隔的活动时段。处理的任何事件都处于任何现有会话的不活动间隙内,并合并到现有会话中。如果事件超出会话间隙,则将创建新会话。会话窗口的主要应用领域是用户行为分析。基于会话的分析可以包括简单的指标.

如果我们接收到另外三条记录(包括两条迟到的记录),那么绿色记录key的两个现有会话将合并为一个会话,从时间0开始到结束时间6,包括共有三条记录。蓝色记录key的现有会话将延长到时间5结束,共包含两个记录。最后,将在11时开始和结束蓝键的新会话。

StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.windowedBy(SessionWindows.with(Duration.ofSeconds(5)))
.reduce((v1,v2)->v1+v2,
Materialized.,Integer, SessionStore<Bytes,byte[]>>as("session-word-count")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Integer()
)
)
.toStream()
.print(Printed.toSysOut());
Window Final Results
在Kafka Streams中,窗口计算会不断更新其结果。当新数据到达窗口时,向下游发出新计算的结果。但是有时候希望在窗口结束的时候才开始发送最终结果出去,这个时候可以采用suppress方法,该方法会在窗口结束的时候才会将结果发送出去.场景:计算一个小时内活跃度小于3的用户,并且给活跃度小于该阈值的用户进行发送报警。在这个场景中如果不适宜钳制手段,可能在窗口初期所有的用户都可能接收到该报警。
StreamsBuilder builder = new StreamsBuilder();
builder.stream(
"topic01", //输入topic
Consumed.with(
Serdes.String(), /* key serde */
Serdes.String() /* value serde */
))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key,value)->value)
.mapValues((v)->1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.windowedBy(TimeWindows.of(Duration.ofMinutes(1)).grace(Duration.ofSeconds(20)))
.reduce((v1,v2)->v1+v2,
Materialized.,Integer, WindowStore<Bytes,byte[]>>as("session-word-count")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Integer()
)
)
.suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded()))
.toStream()
.peek((k,v)->{
SimpleDateFormat sdf = new SimpleDateFormat("hh:mm:ss");
Window window = k.window();
String start=sdf.format(window.start());
String end=sdf.format(window.end());
System.out.println(start+" - "+end+"\t"+k.key()+":"+v);
});
其中:grace表示延迟,例如本案记录触发的窗口的时间如果是12:00:00~12:01:00触发的窗口,系统会在12:01:20秒的时候触发窗口,期间如果又迟到的元素,还可以加进去计算。在=因为系统会在12:01:20将窗口关闭。
superess表示窗口钳制,也就是再什么时机可以触发窗口向后续的流数据输出窗口统计结果。其中Suppressed.untilWindowCloses表示直到窗口关闭的时候才会触发窗口。如果配置成untilTimeLimit可以指定钳制多久时间将窗口发送出去,这样可以减少更新KTable的时间,提升程序性能。
suppress(Suppressed.untilTimeLimit(Duration.ofMillis(100), Suppressed.BufferConfig.maxBytes(1024).emitEarlyWhenFull()))
SpringBoot 集成 KafkaStream
<properties>
<kafka.version>2.2.0kafka.version>
properties>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.0.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
<version>2.2.5.RELEASEversion>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>${kafka.version}version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-streamsartifactId>
<version>${kafka.version}version>
dependency>
dependencies>
# 生产者
spring.kafka.producer.bootstrap-servers=CentOS:9092,CentOS:9093,CentOS:9094
spring.kafka.producer.acks=all
spring.kafka.producer.retries=1
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 消费者
spring.kafka.consumer.bootstrap-servers=CentOS:9092,CentOS:9093,CentOS:9094
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 流处理
spring.kafka.streams.application-id= springboot-kafka-01
spring.kafka.streams.bootstrap-servers=CentOS:9092,CentOS:9093,CentOS:9094
spring.kafka.streams.properties.commit.interval.ms=100
@SpringBootApplication
@EnableKafkaStreams
@EnableScheduling
public class SpringApplicationTests {
@Autowired
private KafkaTemplate kafkaTemplate;
public static void main(String[] args) {
SpringApplication.run(SpringApplicationTests.class,args);
}
@Scheduled(cron = "00/1 * * * * ?")
public void send(){
System.out.println("--------------------------");
String[] message=new String[]{"this is a demo","hello world","hello boy"};
ListenableFuture future = kafkaTemplate.send("topic02", message[new Random().nextInt(message.length)]);
future.addCallback(o -> System.out.println("send-消息发送成功:" + message), throwable -> System.out.println("消息发送失败:" + message));
}
@KafkaListener(topics = "topic02",id="g1")
public void processMessage(ConsumerRecord<?, ?> record) {
System.out.println("record:"+record);
}
@Bean
public KStream<Windowed<String>, Integer> kStream(StreamsBuilder builder) {
return builder.stream("topic02",
Consumed.with(Serdes.String(), Serdes.String()))
.flatMapValues((String key, String value) -> {
List<String> result = new ArrayList<>();
String[] tokens = value.split("\\W+");
for (String token : tokens) {
result.add(token);
}
return result;
}
)
.selectKey((key, value) -> value)
.mapValues((v) -> 1)
.groupByKey(Grouped.with(
Serdes.String(),
Serdes.Integer()
))
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
.reduce((v1, v2) -> v1 + v2,
Materialized., Integer, WindowStore<Bytes, byte[]>>as("tumbling-word-count")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Integer()
)
)
.suppress(Suppressed.untilTimeLimit(Duration.ofSeconds(10),Suppressed.BufferConfig.unbounded()))
.toStream()
.peek((k, v) -> {
SimpleDateFormat sdf = new SimpleDateFormat("hh:mm:ss");
Window window = k.window();
String start=sdf.format(window.start());
String end=sdf.format(window.end());
System.out.println(start+" - "+end+"\t"+k.key()+":"+v);
});
}
}