使用pandas操作DataFrames(二)
目录
第二部分:高级索引
一、索引对象和标记数据
1.1 索引值和名称
1.2 更改DataFrame的索引
1.3 更改索引名称标签
1.4 构建索引,然后构建DataFrame
二、层次化索引
2.1 使用MultiIndex提取数据
2.2 设置和排序MultiIndex
2.3 使用.loc []和非唯一索引
2.4 索引MultiIndex的多个级别
第二部分:高级索引
在学习了使用DataFrames的基础知识后,学习更高级的索引技术。 将了解MultiIndexes或层次化索引,并了解如何与它们进行交互并从中提取数据。
一、索引对象和标记数据
1.1 索引值和名称
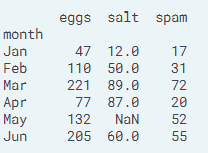

1.2 更改DataFrame的索引
索引是不可变对象。 这意味着如果要更改或修改DataFrame中的索引,则需要更改整个索引。 使用列表生成式来创建新索引。
# Create the list of new indexes: new_idx
new_idx = [month.upper() for month in sales.index]
# Assign new_idx to sales.index
sales.index = new_idx
# Print the sales DataFrame
print(sales)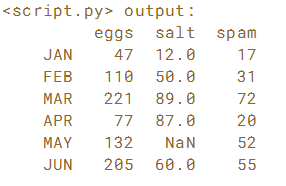
1.3 更改索引名称标签
在上一个练习中,索引未标记名称。 在本练习中,将其名称设置为“MONTHS”。同样,如果所有列都以某种方式相关,则可以为列提供标签。
# Assign the string 'MONTHS' to sales.index.name
sales.index.name = 'MONTHS'
# Print the sales DataFrame
print(sales)
# Assign the string 'PRODUCTS' to sales.columns.name
sales.columns.name = 'PRODUCTS'
# Print the sales dataframe again
print(sales)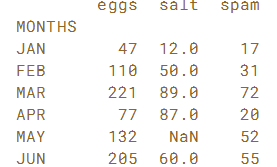
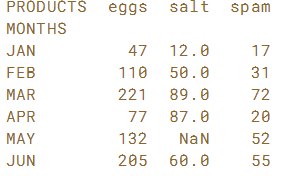
在第一个DataFrame中,索引只有行标签,而在第二个DataFrame中,索引和列都有标签。
1.4 构建索引,然后构建DataFrame
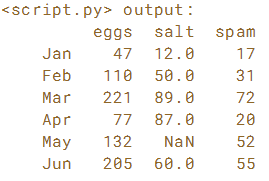
可以单独构建DataFrame和索引,然后将它们组合在一起。 如果采用这种方法,请注意,因为生成DataFrame或索引时的任何错误都可能导致数据和索引不正确对齐。在本练习中,提供了销售数据框,没有月份索引。 单独构建此索引,然后将其分配给销售DataFrame。 在开始之前,在IPython Shell中打印销售数据框,并注意它缺少月份信息。
# Generate the list of months: months
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun']
# Assign months to sales.index
sales.index = months
# Print the modified sales DataFrame
print(sales)
二、层次化索引
2.1 使用MultiIndex提取数据
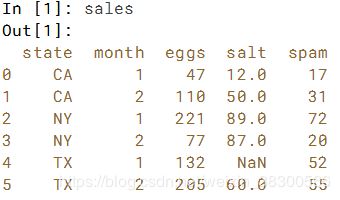
在视频中,Dhavide解释了层次索引或MultiIndex的概念。 一直在使用的销售数据框架已扩展到现在包括状态信息。 在IPython Shell中,打印新的销售DataFrame以检查数据。 注意MultiIndex!从MultiIndex的最外层提取元素就像单级索引一样。 可以使用.loc []访问。

# Print sales.loc[['CA', 'TX']]
print(sales.loc[['CA','TX']])
# Print sales['CA':'TX']
print(sales['CA':'TX'])

2.2 设置和排序MultiIndex
在上一个练习中,MultiIndex已创建并排序。 现在,你要自己做! 使用MultiIndex,应始终确保索引已排序。 只有在知道数据已在索引字段中排序后,才能跳过此步骤。首先,在IPython Shell中打印预加载的sales DataFrame,以验证没有MultiIndex。
.set_index()会将DataFrame的一个或多个列转化成行索引,并创建一个新的DataFrame。默认情况下那些列会从DataFrame中移除,但也可以留下来,使用drop=False
.sort_index()可以对行或列索引进行排序。对于DataFrame,可以根据任意一个轴上的索引进行排序,数据默认是按升序排序。
.sort_index(axis=1,ascending=False) 也可能根据一个或多个列中的值进行排序,将一个或多个列的名字传给by参数即可。
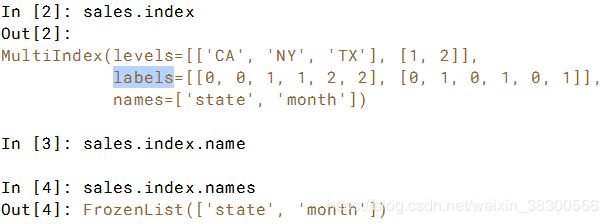
# Set the index to be the columns ['state', 'month']: sales
sales = sales.set_index(['state','month'])
# Sort the MultiIndex: sales
sales = sales.sort_index()
# Print the sales DataFrame
print(sales)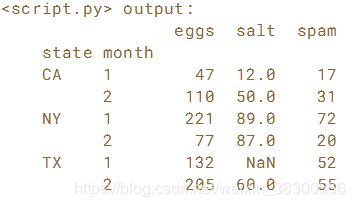
2.3 使用.loc []和非唯一索引
最好有一个唯一标识每一行的有意义的索引。 尽管pandas在DataFrames中不需要唯一的索引值,但如果索引值确实是唯一的,它会更好。
# Set the index to the column 'state': sales
sales = sales.set_index(['state'])
# Print the sales DataFrame
print(sales)
# Access the data from 'NY'
print(sales['NY':'NY'])
print(sales.loc['NY'])因为有非唯一索引,所以返回两行。
2.4 索引MultiIndex的多个级别
查找索引数据是快速有效的。 基于MultiIndex最外层的查找工作就像在具有单级索引的DataFrame上查找一样。基于MultiIndex的内部级别查找数据可能有点棘手。 在本练习中,使用sales DataFrame执行一些日益复杂的查找。
所有这些查找中最棘手的是当想要访问索引的某些内部级别。 在这种情况下,您需要在最外层维度的切片参数中使用切片(无)而不是通常的:,或使用pd.IndexSlice。可以参考pandas文档以获取更多详细信息。
特别注意元组(slice(None), slice('2016-10-03', '2016-10-04'))
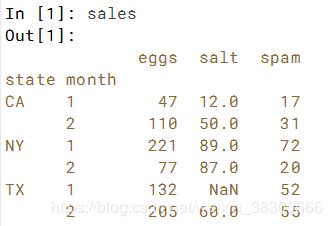
- Look up data for the New York column (
'NY') in month1. - Look up data for the California and Texas columns (
'CA','TX') in month2. - Look up data for all states in month
2. Use(slice(None), 2)to extract all rows in month2.
# Look up data for NY in month 1: NY_month1
NY_month1 = sales.loc[('NY',1)]
# Look up data for CA and TX in month 2: CA_TX_month2
CA_TX_month2 = sales.loc[(['CA','TX'],2),:]
# Look up data for all states in month 2: all_month2
all_month2 = sales.loc[(slice(None),2),:]CA_TX_month2 = sales.loc[(['CA','TX'],2),:],此处要加上:。