利用神经网络解决NLP问题【W2V+SVM】&【W2V+CNN】_完整项目_CodingPark编程公园
文章介绍
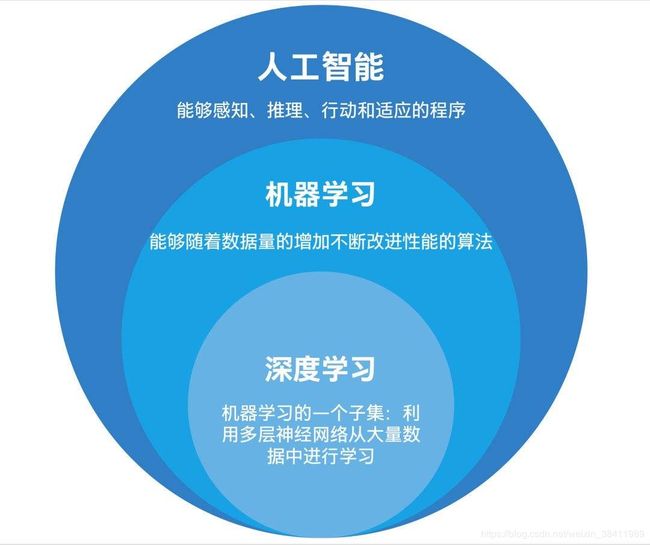
本文讲述利用 Word2Vec把文字向量化,随后分别利用SVM与CNN进行学习与测试
W2V+SVM
- 监视数据
我们先读入数据,看一下数据长什么样子 - 分割测试/训练集
这里我们注意,我们需要三样东西:
corpus是全部我们『可见』的文本资料。我们假设每条新闻就是一句话,把他们全部flatten()了,我们就会得到list of sentences。
同时我们的X_train和X_test可不能随便flatten,他们需要与y_train和y_test对应。
同时我们再把每个单词给分隔开 - 预处理
小写化
删除停止词
删除数字与符号
lemma - 训练NLP模型-Word2Vec
- 用NLP模型表达我们的X - 平均值法
我们的vec是基于每个单词的,怎么办呢?
由于我们文本本身的量很小,我们可以把所有的单词的vector拿过来取个平均值 - 建立机器学习ML模型
我们来看看比较适合连续函数的方法:SVM

W2V+CNN
- 监视数据
我们先读入数据,看一下数据长什么样子 - 分割测试/训练集
这里我们注意,我们需要三样东西:
corpus是全部我们『可见』的文本资料。我们假设每条新闻就是一句话,把他们全部flatten()了,我们就会得到list of sentences。
同时我们的X_train和X_test可不能随便flatten,他们需要与y_train和y_test对应。
同时我们再把每个单词给分隔开 - 预处理
小写化
删除停止词
删除数字与符号
lemma - 训练NLP模型-Word2Vec
- 用NLP模型表达我们的X - 大matrix法
我们的vec是基于每个单词的,怎么办呢?
由于我们文本本身的量很小,我们可以把所有的单词的vector拿过来取个平均值 - 建立机器学习ML模型
CNN模型
预备知识

在安装Keras之前,需安装其后端引擎,在TensorFlow, Theano, or CNTK之中选择一个即可。我选择的是TensorFlow。
- TensorFlow安装说明
笔者直接输入sudo pip install tensorflow就安装成功了
打开终端:输入: 提示输入密码的话是笔记本登录时的密码。
sudo easy_install pip ,下载好之后
输入:
sudo easy_install --upgrade six
安装TensorFlow,这个过程比较久,取决于网速。(不输入sudo命令会报错,权限不够。)
输入:
sudo pip install tensorflow
安装后会出现存在numpy的操作错误,因此需要输入命令:
sudo pip install --ignore-installed tensorflow
若要卸载tensorflow,用命令
pip uninstall tensorflow
- 安装keras
笔者直接输入sudo pip install keras就安装成功了
输入命令:
sudo pip install keras
同样会出现上面的错误,继续输入:
sudo pip install --ignore-installed keras
至此,Mac上安装keras就结束了。
代码实战
cross_val_score进行交叉验证
from sklearn import datasets # 自带数据集
from sklearn.model_selection import train_test_split, cross_val_score # 划分数据 交叉验证
from sklearn.neighbors import KNeighborsClassifier # 一个简单的模型,只有K一个参数,类似K-means
import matplotlib.pyplot as plt
iris = datasets.load_iris() # 加载sklearn自带的数据集-安德森鸢尾花卉数据集
x = iris.data # 这是数据
print()
print('x -> ', x)
y = iris.target # 这是每个数据所对应的标签
print()
print('y -> ', y)
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=1 / 3, random_state=3) # 这里划分数据以1/3的来划分 训练集训练结果 测试集测试结果
k_range = range(1, 61)
cv_scores = [] # 用来放每个模型的结果值
for n in k_range:
knn = KNeighborsClassifier(n) # knn模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GridSearchCV
scores = cross_val_score(knn, train_x, train_y, cv=10,
scoring='accuracy') # cv:选择每次测试折数 accuracy:评价指标是准确度,可以省略使用默认值,具体使用参考下面。
cv_scores.append(scores.mean())
plt.plot(k_range, cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy') # 通过图像选择最好的参数
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=3) # 选择最优的K=3传入模型
best_knn.fit(train_x, train_y) # 训练模型
print()
print('best_knn.score -> ', best_knn.score(test_x, test_y)) # 看看评分
利用神经网络解决NLP问题 - 完整代码
import pandas as pd
import numpy as np
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.metrics import roc_auc_score
from sklearn.svm import SVR
from sklearn.model_selection import cross_val_score
from datetime import date
import matplotlib.pyplot as plt
import re
from gensim.models.word2vec import Word2Vec
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
'''
整合数据
'''
# 读入数据
data = pd.read_csv('Combined_News_DJIA.csv')
data.head()
# 分割测试/训练集
train = data[data['Date'] < '2015-01-01']
test = data[data['Date'] > '2014-12-31']
X_train = train[train.columns[2:]]
corpus = X_train.values.flatten().astype(str) # flatten() 降维
print("\n打印x_train的corpus -> ", corpus)
X_train = X_train.values.astype(str)
X_train = np.array([' '.join(x) for x in X_train])
X_test = test[test.columns[2:]]
X_test = X_test.values.astype(str)
X_test = np.array([' '.join(x) for x in X_test])
Y_train = train['Label'].values
Y_test = test['Label'].values
corpus = [word_tokenize(x) for x in corpus]
X_train = [word_tokenize(x) for x in X_train]
X_test = [word_tokenize(x) for x in X_test]
print()
print('X_train[:2] -> ', X_train[:2])
print()
print('corpus ->', corpus[:2])
print()
print('检查点1')
'''
预处理
# 小写化
# 删除停止词
# 删除数字与符号
# lemma
'''
# 停止词
stop = stopwords.words('english')
# 数字
def hasNumbers(inputString):
return bool(re.search(r'\d', inputString))
# 特殊符号
def isSymbol(inputString):
return bool(re.match(r'[^\w]', inputString))
# lemma
wordnet_lemmatizer = WordNetLemmatizer()
def check(word):
# 如果需要这个单词,则True
# 如果应该去除,则False
word = word.lower()
if word in stop:
return False
elif hasNumbers(word) or isSymbol(word):
return False
else:
return True
def preprocessing(sen):
res = []
for word in sen:
if check(word):
# 这一段的用处仅仅是去除python里面byte存str时候留下的标识。。之前数据没处理好,其他case里不会有这个情况
word = word.lower().replace("b'", '').replace('b"', '').replace('"', '').replace("'", '')
res.append(wordnet_lemmatizer.lemmatize(word))
return res
corpus = [preprocessing(x) for x in corpus]
X_train = [preprocessing(x) for x in X_train]
X_test = [preprocessing(x) for x in X_test]
print('corpus[10] -> ', corpus[10])
print('X_train[10] -> ', X_train[10])
"""
训练NLP模型
"""
model = Word2Vec(corpus, size=128, window=5, min_count=5, workers=4)
model.save('W2V_CNN_StockAdvanced')
# print('ok -> ', model['ok'])
# 先拿到全部的vocabulary
vocab = model.wv.vocab
print()
print('vocab -> ', vocab)
print()
# 得到任意text的vector
def get_vector(word_list):
res = np.zeros([128])
count = 0
for word in word_list:
if word in vocab:
res += model[word]
count += 1
return res / count
# print("\nget_vector(['hello', 'from', 'the', 'other', 'side'] -> ", get_vector(['hello', 'from', 'the', 'other', 'side']))
wordlist_train = X_train
wordlist_test = X_test
X_train = [get_vector(x) for x in X_train]
X_test = [get_vector(x) for x in X_test]
print()
print('X_train[10] -> ', X_train[10])
# SVM
print('-----SVM-----')
params = [0.1, 0.5, 1, 3, 5, 7, 10, 12, 16, 20, 25, 30, 35, 40] # 拉拢参数
test_scores = []
for param in params:
clf = SVR(gamma=param)
test_score = cross_val_score(clf, X_train, Y_train, cv=3, scoring='roc_auc')
# print(type(test_scores))
test_scores.append(np.mean(test_score))
plt.plot(params, test_scores)
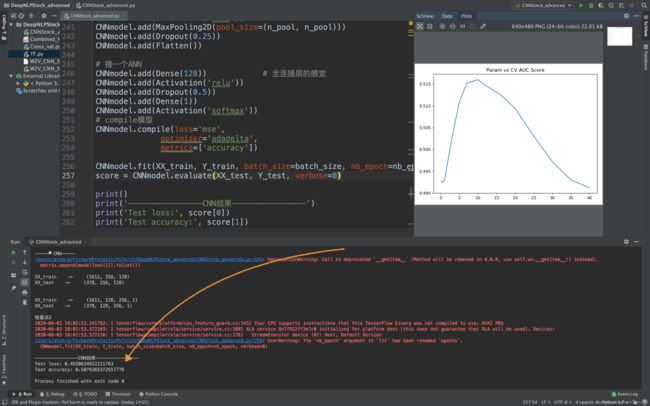
plt.title("Param vs CV AUC Score")
plt.show()
print()
print(' 图片绘制完毕 ✅ ')
print()
print('------测试------')
best_knn = SVR(gamma=12) # 选择最优的12传入模型
best_knn.fit(X_train, Y_train) # 训练模型
print()
print('best_knn.score -> ', best_knn.score(X_test, Y_test)) # 看看评分
print()
# CNN
print()
print('-----CNN-----')
# 严谨处理
# 对于每天的新闻,我们会考虑前256个单词。不够的我们用[000000]补上
# vec_size 指的是我们本身vector的size
def transform_to_matrix(x, padding_size=256, vec_size=128):
res = []
for sen in x:
matrix = []
for i in range(padding_size):
try:
matrix.append(model[sen[i]].tolist())
except:
matrix.append([0] * vec_size)
# 这里有两种except情况,
# 1. 这个单词找不到
# 2. sen没那么长
# 不管哪种情况,我们直接贴上全是0的vec
res.append(matrix)
return res
XX_train = transform_to_matrix(wordlist_train)
XX_test = transform_to_matrix(wordlist_test)
# 搞成np的数组,便于处理
XX_train = np.array(XX_train)
XX_test = np.array(XX_test)
# 看看数组的大小
print()
print('XX_train -> ', XX_train.shape)
print('XX_test -> ', XX_test.shape)
print()
XX_train = XX_train.reshape(XX_train.shape[0], XX_train.shape[2], XX_train.shape[1], 1)
XX_test = XX_test.reshape(XX_test.shape[0], XX_test.shape[2], XX_test.shape[1], 1)
# 看看reshape后数组的大小
print()
print('XX_train -> ', XX_train.shape)
print('XX_test -> ', XX_test.shape)
print()
print('检查点2')
# 设置 参数
batch_size = 32
n_filter = 16
filter_length = 4
nb_epoch = 5
n_pool = 2
# 新建一个sequential的模型
CNNmodel = Sequential()
CNNmodel.add(Convolution2D(n_filter, (filter_length, filter_length), input_shape=(128, 256, 1)))
CNNmodel.add(Activation('relu'))
CNNmodel.add(Convolution2D(n_filter, (filter_length, filter_length)))
CNNmodel.add(Activation('relu'))
CNNmodel.add(MaxPooling2D(pool_size=(n_pool, n_pool)))
CNNmodel.add(Dropout(0.25))
CNNmodel.add(Flatten())
# 接一个ANN
CNNmodel.add(Dense(128)) # 全连接层的感觉
CNNmodel.add(Activation('relu'))
CNNmodel.add(Dropout(0.5))
CNNmodel.add(Dense(1))
CNNmodel.add(Activation('softmax'))
# compile模型
CNNmodel.compile(loss='mse',
optimizer='adadelta',
metrics=['accuracy'])
CNNmodel.fit(XX_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch, verbose=0)
score = CNNmodel.evaluate(XX_test, Y_test, verbose=0)
print()
print('----------------CNN结果----------------')
print('Test loss:', score[0])
print('Test accuracy:', score[1])
特别鸣谢-文章
为什么要做 batch normalization
https://www.jianshu.com/p/3da70e672c8b
word2Vec 获取训练好后所有的词
https://blog.csdn.net/u013061183/article/details/79383167
iris数据集及简介
https://blog.csdn.net/java1573/article/details/78865495?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159115798419725219922171%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=159115798419725219922171&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allbaidu_landing_v2~default-1-78865495.first_rank_ecpm_v1_pc_rank_v3&utm_term=.load_iris%28%29
SVR(Support Vactor Regression)支持向量回归机
https://www.jianshu.com/p/399ddcac2178
特别鸣谢-伙伴
Sun Muye
