NPL知识总结
NPL知识总结
第一章NLP基础
- NLP(Natural Language Processing,自然语言处理)研究用计算机来处理、理解以及运用人类语言(如中文、英文等),达到人与计算机之间进行有效通讯。
- 自然语言理解包括:音系学、词态学、句法学、语义学、语用学
自然语言生成三阶段:文本规划、语句规划、实现
- NLP应用领域:机器翻译、情感分析、智能问答、文摘生成、文本分类、舆论分析、知识图谱。
- NLP发展的3个阶段:1956年以前是萌芽期,1980-1999快速发展期,21世纪突飞猛进期。
AI三次浪潮:1956-1976逻辑主义为核心,1976-2006神经网络,2006-now大数据的深度学习
- 术语:
- 分词(segment)是最小的能够独立活动的语言成分
- 词性标注(part-of-speech tagging)把分好的词标为动词、名词等
- 命名实体(NER, Named Entity Recognition)人名、地名、机构名、专有名词
- 句法分析(syntax parsing)目的:解析句子中各个成分的依赖关系。往往是一种基于规则的专家系统。
- 指代消解(anaphora resolution)他她它等代词的消除
- 情感识别(emotion recognition)本质是分类问题
- 纠错(correction)N-Gram、字典树、有限状态机等方法进行纠错
- 问答系统(QA system)类似Siri
- 语料库:中文维基百科、搜狗新闻语料库、IMDB(Internet Movie Database)互联网电影资料库。
- NLP三个层面:
- 词法分析
- 句法分析
- 语义分析
- NLP进步取决于:海量的数据,深度学习算法的革新。(从基于规则的发放->基于统计学的方法->深度学习神经网络方法)
第二章NLP前置技术
- Python+Anaconda+Pycharm+numpy(用法自学)
- 正则表达式:python re库(re.search(regex, text) #text是全文,regex是关键点 )
| \ |
转义 |
| ^ |
行首 |
| $ |
行尾 |
| * |
任意次 |
| + |
》=1次 |
| ? |
0或1次 |
| . |
任意字符 |
第三章中文分词技术
- 分词3种方法:规则分词、统计分词、混合分词(规则+统计)
对比规则分词,其他分词方法不需要耗费人力维护词典,能较好的处理歧义,和未登录词,是主流方法,但效果依赖于训练语料的质量,计算量大。
- 规则分词主要通过维护词典:
- 正向最大匹配法(Maximum Match Method)左到右,左边最大匹配后切左边
- 逆向最大匹配法(Reverse Maximum Method)右到左,右边最大匹配后切右边
- 双向最大匹配法(Bi - directction Matching method)正方去分词数量少的那个(分词数量一样则返回单字较少的那个)
例题一、假设字典为:{"轻工业", "工业", "质量", "产品", "大幅度",“提升”,”年轻“} ,年份单独分词。
现有句子:"2013 年轻工业产品质量大幅度提升",
1.采用正向最大匹配法的分词结果是 2013|年 轻 |工 业 |产 品 |质 量 |大幅度|提 升
2. 采用逆向最大匹配法的分词结果是 2013|年 |轻工业 |产 品 |质 量 |大幅度 |提 升
3. 采用双向最大匹配法的分词结果是 2013|年 轻 |工 业 |产 品 |质 量 |大幅度|提 升 (分词数同但单字少)
3. 统计分词思想:把每个词看做是单字,相连的字在不同文本出现的次数越多,则相连的字可能是一个词。
步骤:(1)建立统计语言模型
①一元模型:各词之间都是相互独立的,这无疑是完全损失了句中的词序信息。
②二元模型:当前词只与前面的一个词有关。
③三元模型:n≥2,保留词序信息丰富,但计算成本成指数增长。
分母出现0的情况,配合相应的平滑算法(如拉普拉斯平滑算法)
- 对句子进行单词划分,然后计算概率,取最大概率的分词方式。
隐含马尔可夫模型(HMM):将句子的分词转换为BMES的串。
两个独立性假设:①输出观察值之间严格独立。②状态的转移过程中当前状态只与前一状态有关。
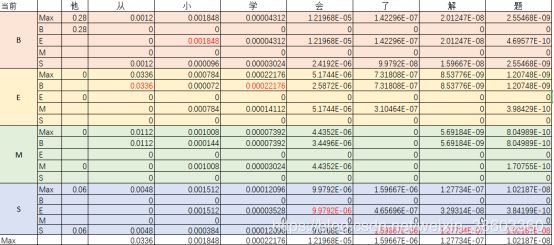
例题假设有 HMM 模型,初始状态概率向量、状态转移概率矩阵、观测概率矩阵分别如下:
求句子的分词标注为 “SBEBESBE”的概率。

答:P(SBEBESBE|他从小学会了解题)=P(他从小学会了解题|SBEBESBE)P(SBEBESBE)/P(他从小学会了解题)
P(他从小学会了解题)为常数,忽略。
针对 P(他从小学会了解题|SBEBESBE)P(SBEBESBE)做马尔科夫假设,则
P(他从小学会了解题|SBEBESBE)= P(他|S)P(从|B)P(小|E)P(学|B)P(会|E)P(了|S)P(解|B)P(题|E)
P(SBEBESBE)= P(B|S)P(E|B)P(B|E)P(E|B)P(S|E)P(B|S)P(E|B)
因此,原式=P(他|S)P(B|S) P(从|B)P(E|B) P(小|E)P(B|E) P(学|B)P(E|B) P(会|E)P(S|E) P(了|S)P(B|S) P(解|B)P(E|B) P(题|E)
=0.2*0.2*0.1*0.6*0.1*0.55*0.1*0.6*0.1*0.45*0.2*0.2*0.05*0.6*0.1=4.2768*e-11
求句子的分词标注为“SSBESBE”的概率。
P(“SSBESSBE”|” 他从小学会了解题”)= P(他从小学会了解题|SSBESSBE)P(SSBESSBE)
=P(他|S)P(从|S)P(小|B)P(学|E)P(会|S)P(了|S)P(解|B)P(题|E)
*P(S|S)P(B|S)P(E|B)P(S|E)P(S|S)P(B|S)P(E|B)
=0.2*0.1*0.1*0.2*0.1*0.2*0.05*0.1*0.8*0.2*0.6*0.45*0.8*0.2*0.6 =1.65888e-10
Veterbi算法:在HMM中,求解maxP(他从小学会了解题|SBEBESBE)P(SBEBESBE)的常用方法,是一种动态规划方法,核心思想:如果最优路径经过oj,那么从节点到oj-1点也是最优路径。

条件随机场(CRF,Conditional Random Field):若干个位置组成的整体,当给某一个位置按照某种分布随机赋予一个值,该整体就被称为随机场。+给定条件
不仅考虑上一个状态,还考虑后面一个状态。
HMM是有向图,而线性链条件随机场(linear-chain conditional random field)是无向图。HMM每个状态依赖上一个状态,而线性链条件随机场依赖于当前状态的周围节点状态。
CRF能够捕捉全局的信息,并能够进行灵活的特征设计,因此比HMM效果好,但复杂度高。
- 中文分词工具- jieba
优点:社区活跃、功能丰富、提供多种语言实现、使用简单。
三种分词模式:精确模式、全模式、搜索引擎模式
第四章:词性标注与命名实体识别
- 词性标注:标注名词、形容词等
- Jieba分词中的词性标注
- 正则表达式找出汉字
- 基于前缀字典构建有向无环图找出最大概率路径,同时在词典中找出词性
- 不符合正则表达式用x,m,eng来表示
- 命名实体识别(NER, Name Entities Recognition)目的:识别预料中人名、地名、组织机构名等命名实体。3大类(实体类、时间类、数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)
- 命名实体识别难点:各类命名实体的数量众多、命名实体构成规律复杂、嵌套情况复杂、长度不确定。
- 命名实体3种方法:基于规则的命名实体识别、基于统计的命名实体识别、混合方法
- 序列标注方式是目前命名实体识别中的主流方法。
第五章:关键词提取算法(Key phrase extraction)
- TF-IDF算法(term frequency–inverse document frequency,词频-逆文档频次算法)


TF-IDF = TF*IDF
关键词提取
一、假设有如下 5 篇文章:
P1:夜来风雨声,花落知多少。
P2:人面不知何处去,桃花依旧笑春风。
P3:春花秋月何时了?往事知多少。
P4:问君能有几多愁?恰似一江春水向东流。
P5:寂寞空庭春欲晚,梨花满地不开门。
(1)计算下列字的 TF-IDF 值。
P1-“春”:TF=0/10 IDF=log(5/5), TF-IDF=0*0=0
P1-“花”:TF=1/10 IDF=log(5/5), TF-IDF=0*0=0
P1-“风”:TF=1/10 IDF=log(5/3), TF-IDF=1/10*log(5/3)
- PageRank算法是一种网页排名算法
- 一个网页被越多的其他网页链接,w增
- 一个网页被一个权值越高的网页链接,w增
- TextRank算法来源于谷歌的PageRank算法。脱离语料库背景,仅对单篇文章分析后提取关键字。利用窗口对所有词进行连接,计算词的得分。
- LSA(Latent Semantic Analysis,潜在语义分析)和LSI(Latent Semantic Index,潜在语义索引)二者都是对文档的潜在语义进行分析,LSI在分析后利用分析结果建立相关索引。通,过SVD(奇异值分解)将词、文档映射到一个低纬的语义空间,挖掘词的浅层语义信息(如:老虎,浅层语义是动物)
- LDA(Latent Dirichlet Allocation,隐含迪利克雷分布),理论基础是贝叶斯理论。
第六章:句法分析
- 句法分析(Parsing)存在的问题:歧义、搜索空间
- 句法分析数据集:宾州树库(PTB,Penn TreeBank),中文的有(中文宾州树库,CTB,Chinese TreeBank,清华树库,TCT,Tsinghua TreeBank)
- 句法分析评测方法:PARSEVAL评测体系,指标有:准确率、召回率、交叉括号数。
- 基于PCFG(Probabilistic Context Free Grammar)的句法分析
- 基于最大间隔马尔可夫网络的句法分析
- 基于CRF的句法分析
- 基于移进-规约的句法分析模型
第七章:文本向量化
- 词袋(Bag Of Word,BOW)
P1:我爱中国
P2:我爱我的中国 分词库为{我,爱,的,中,国}
P1 的词袋向量为:[1 1 0 1 1]
P2 的词袋向量为:[2 1 1 1 1]
存在问题:维度灾难、无法保留词序信息、存在语义鸿沟的问题。
分布假说(distributional hypothesis)提出解决了上述问题。核心思想:上下文相似的词,其语义也相似。
- 生成词向量的3种神经网络模型
- 神经网络语言模型(Neural Network Language Model)解决了词袋模型带来的数据稀疏、语义鸿沟问题。
目标:构建一个语言概率模型
- C&W模型:给短语打分
目标:生成词向量
- CBOW(Continuous Bag Of-Word)模型:无隐含层,用词向量的平均值代替NNLM模型各个拼接的词向量。
- Skip-gram模型:无隐含层,从目标词w的上下文选择一个词,将其词向量组成上下文的表示。
Skip-gram和CBOW实际上是word2vec两种不同思想的实现:CBOW目标是根据上下文来预测当前词语的概率,Skip-gram根据当前词预测上下文概率。
3. doc2vec是word2vec的升级,不仅提取文本的语义信息,而且提取了文本的语序信息。
第八章:情感分析技术
- 情感分析应用:电子商务、舆请分析、市场呼声、消费者呼声。
- 情感分析的基本方法:词法分析(文本转为单词序列,进行加分减分得结果)、机器学习方法、混合分析、
- 长短时记忆网络(LSTM, Long Short Term Memory)是RNN一种。能对时序数据进行精准建模得网络。
第九章:NLP中用到得机器学习算法
- 分类算法:朴素贝叶斯、SVM、逻辑回归
SVM目的:找超平面(二位就是一条线),将两个数据集分开。
核函数解决线性不可分问题。
优点:低泛化,可解释、计算复杂度低
缺点:对参数和核函数选择敏感,原始SVM只能二分类
- 聚类算法:k-means算法
- 随机选择c个类别得初始中心
- 进行第k次迭代,讲样本归类
- 利用均值等方法更新中心
- 若中心不变则停止
补充:
自然语言处理(Natural Language Processing,NLP)
自然语言生成(Natural Language Generation,NLG)
知识图谱(Knowledge Graph/Vault)
分词(Segment)
词性标注(part-of-speech tagging)
命名实体识别(Named Entity Recognition,NER)
句法分析(syntax parsing)
互联网电影资料库(Internet Movie Database,IMDB)
逆/正向最大匹配((Reverse)Maximum Match Method)
条件随机场(CRF,Conditional Random Field)
TF-IDF算法(term frequency–inverse document frequency,词频-逆文档频次算法)
PCFG(Probabilistic Context Free Grammar)概率上下文无关文法
神经网络语言模型(Neural Network Language Model)
词袋(Bag Of Word,BOW)
CBOW(Continuous Bag Of-Word)
长短时记忆网络(LSTM, Long Short Term Memory)
循环神经网络recurrent neural network ( RNN)
卷积神网络(Convolutional Neural Network, CNN)
LSA(Latent Semantic Analysis,潜在语义分析)
LSI(Latent Semantic Index,潜在语义索引)
LDA(Latent Dirichlet Allocation,隐含迪利克雷分布)