YOLOv4 解读:CV 同学必读的目标检测技巧大合集
Title: YOLOv4: Optimal Speed and Accuracy of Object Detection(2020)
Link: Paper Code
Tips:
- 了解提升 CNN 性能有哪些 trick(1.Introduction)
- 了解目标检测模型的通用框架和提升性能的方法(2. Rekated work)
- YOLOv4 的框架及方法(3.4 YOLOv4)
- 学习 ablation study 的实验设置(4. Experiments)
Summary:
本文提出的 YOLOv4 是对 YOLOv3 的一个改进。它的改进方法就是总结了几乎所有的检测技巧,又提出一点儿技巧,然后经过筛选,排列组合,挨个实验(ablation study)哪些方法有效。经过大量的实验,总能找出有效果的方法。
这实际是一种技巧的堆叠,没有提出实质性的新内容,但确实提高了性能。
值得注意的是文章第二部分相关工作,简直就是目标检测的一个简单综述,阅读该部分,你就能了解模型及方法,如果它提到的每个方法你都了解,说明你在这个方向的研究较全面深入(我没达到)。
值得学习的就是严谨的实验方法。
相关文章:
一文读懂 YOLOv1,v2,v3,v4 发展史
YOLOv1 解读:使用 unified system/ one-stage 实现目标检测
YOLOv2 解读:使 YOLO 检测更精准更快,尝试把分类检测数据集结合使用
YOLOv3 解读:小改动带来的性能大提升
论文目录
- Abstract
- 1. Introduction
- 2. Related work
- 2.1. Object detection models
- 2.2. Bag of freebies
- 2.3. Bag of specials
- 3. Methodology
- 3.1. Selection of architecture
- 3.2. Selection of BoF and BoS
- 3.3. Additional improvements
- 3.4. YOLOv4
- 4. Experiments
- 4.1. Experimental setup
- 4.2. Influence of different features on Classifier training
- 4.3. Influence of different features on Detector training
- 4.4. Influence of different backbones and pre-trained weightings on Detector training
- 4.5. Influence of different mini-batch size on Detector training
- 5. Results
- 6. Conclusions
Abstract
有很多提升 CNN 性能的功能,有些是通用的,有些是专用的。
作者总结了一些功能——
- universal features:Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT) and Mish-activation
- new features:WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, DropBlock regularization, and CIoU loss
通过实验验证它们的效果,最后组合了几个有效的方法来提升模型性能,得到的 YOLOv4 在精度和速度上都有提升。
1. Introduction
Goal
设计生产中可用的目标检测器,它检测速度快,可并行优化计算,并且训练和使用简单。
Contributions
- 设计了一个高效的目标检测模型。你只要有 1080 Ti 或 2080 Ti GPU 就能训练一个又快又准的 object detector。
- 验证了两个 state-of-the-art 方法 Bag-of- Freebies 和 Bag-of-Specials 在目标检测的效果。
- 修改了几个state-of-the-art 方法,使它们在单 GPU 上训练更有效。
Results
YOLOv4的检测结果如下,可以看出它比 YOLOv3 在精度(AP)和速度(FPS)上都有很大提升。
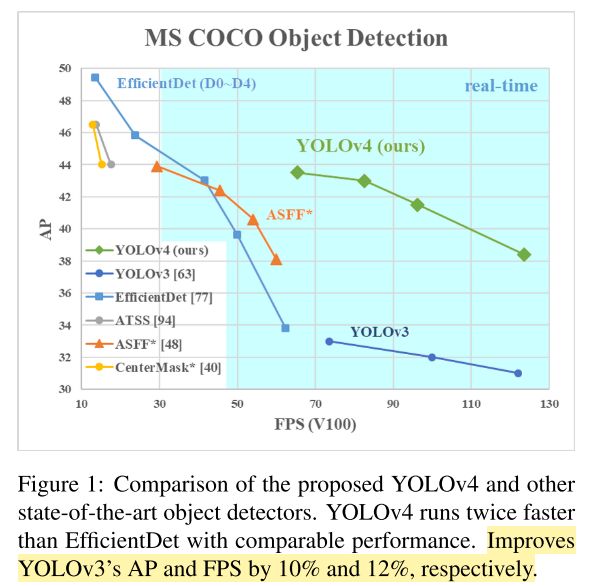
2. Related work
这部分就是目标检测领域的一个综述,一定要理解!
2.1 介绍了通用模块,2.2 和 2.3 介绍了常用的改进方法。
2.1. Object detection models
目标检测的通用模型通常包含两部分:CNN + 预测类别位置的部分。CNN 可称为模型的骨干网络(backbone),预测部分就是网络的输出部分称为 head。
再加上输入的要检测的图片,就形成了 输入→网络→输出 的流程,作者形象地比喻为input→backbone→heads。
近几年,有些学者在 backbone 和 head 之间插入一些 layer,主要用于收集不同阶段的特征图。这个选项可以看作流程中的 neck,所以模型的整个流程概括为 input→backbone→neck→heads,通用的模型是由这三 / 四部分组成的。
下面介绍 backbone 和 head 的分类。
最后附上作者总结的模型组成:

2.2. Bag of freebies
We call these methods that only change the training strategy or only increase the training cost as “bag of freebies.”
Bag of freebies 是指改变训练策略或仅增加训练成本的那些方法,没有 inference cost。因为传统的目标检测器都是离线训练的,因此最好能在训练时采取一些方法提高检测准确率。
本小节介绍了四种场景的 Bag of freebies。
data augmentation
图片数量有限时,通过数据增广就可以提高数据的数量和多样性。图片类型多了,模型就能对不同环境下的图片更鲁棒(robust)。
- Photometric distortions 改变图片的亮度、对比度、饱和度,geometric distortions 改变图像尺寸裁剪,翻转等。
- Random erase 和 CutOut 能随意选取图像的一个矩形区域,或随机把图片的一部分填零(就像图片缺失一部分)。
- Hide-and-seek 和 grid mask 随机选几个矩形区域填零。
- MixUp 利用两幅图片通过重叠等方式生成新图,CutMix 裁剪图片然后把它补在另一幅图的矩形区域生成新图。
- Style transfer GAN 也可用于数据增广。
data imbalance
不同类别数量不均衡,一般可以通过样例挖掘解决,但这种分方法不适用于 one-stage 方法。
- 这里提到的解决方法是使用 focal loss。
execute labeling
用 one-hot hard representation 很难表达不同类别之间的关系,这里提到两种方法:
- label smoothing 把 hard label 转换成 soft-lable 用于训练,可以使模型更 robust。
- the concept of knowledge distillation 用于设计 the label refinement network。
the objective function of Bounding Box (BBox) regression
如何定义边界框回归任务的目标函数?传统的目标检测器使用 Mean Square Error (MSE) 定义预测结果与ground truth之间的差距(例如坐标,高宽,或者偏移量等确定框位置尺寸的量),这些方法实际把这些定点当作独立的变量,没有考虑目标的完整性。
为更好处理这个问题,这里提到的方法有:
- IoU loss,考虑预测框和 GT 框的重叠效果,IOU 是一个尺寸不变的表示。
- GIoU loss,还考虑了目标的形状和方向。
- DIoU loss 考虑了目标中心的距离,CIoU loss 同时考虑了重叠区域,中心点距离和纵横比,收敛更快,效果更精确。
2.3. Bag of specials
For those plugin modules and post-processing methods that only increase the inference cost by a small amount but can significantly improve the accuracy of object detection, we call them “bag of specials”.
Bag of specials 指网络中的插件模块或后处理方法,增加了 inference cost(注意 bag of feerbies 没有没有),这些模块和方法也能增加目标检查的精度。
本小节介绍了五种场景的 bag of specials。
enlarge receptive field
增强感受野的通用模块是 SPP,ASPP 和 RFB。
SPP 模块从 Spatial Pyramid Matching (SPM) 衍生,它把 SPM 集成到 CNN 并用 最大池化代替了词包操作。
attention mechanism
目标检测中常用的注意力模块有两类:channel-wise attention 和 point- wise attention,他们的代表分别为 Squeeze-and-Excitation (SE) 和 Spatial Attention Module (SAM) 。
feature integration
早期的方法有 skip connection 和 hyper-column,自从多尺度检测方法如 FPN 提出来,一些轻量级的集成特征金字塔的方法提出来,比如 SFAM, ASFF,和 BiFPN。
good activation function
好的激活函数能使梯度快速传播,同时不耗费过多的计算资源。比如 ReLU 以及它衍生出的 LReLU, PReLU,ReLU6,Scaled Exponential Linear Unit (SELU) ,Swish,hard-Swish 和 Mish。
post-processing
目标检测后处理的方法是 NMS,它用来过滤不好的预测。相关的方法有 greedy NMS,soft NMS 以及 DIoU NMS。
3. Methodology
3.1. Selection of architecture
网络结构的设计目标:
- 在输入分辨率,卷积层数,参数数目,输出层数之间找到一个最优平衡;
- 选择一些额外的能扩大感受域或利于参数聚合的模块。比如 FPN, PAN, ASFF, BiFPN。
基于目标,通过对比,作者选择 CSPDarknet53 backbone, SPP additional module, PANet path-aggregation neck, and YOLOv3 (anchor based) head 作为 YOLOv4 的架构。
未来可能用一些 Bag of Freebies (BoF) 提高模型精确度。
3.2. Selection of BoF and BoS
训练选择的一些方法:

3.3. Additional improvements
为了时检测器适合在单 GPU 上训练,作者还设计和改进了一些方法:
- 提出新的数据增广方法:Mosaic 和 Self-Adversarial Training (SAT)。Mosaic 混合了四幅不同内容的图片,SAT 是一个两阶段的对抗训练。
- 选择最优超参数
- 修改已有方法使模型更适宜训练:modified SAM, modified PAN, and Cross mini-Batch Normalization (CmBN)
3.4. YOLOv4
详细介绍框架和模型各部分使用到的方法。

4. Experiments
检验选用的不同技术对分类、检测性能的影响,文章列出了 ablation study 的结果。
4.1. Experimental setup
介绍了实验设置,具体看论文。
- ImageNet 分类实验的默认超参数,BoS 实验使用默认值,BoF 实验有一些改动。
- MS COCO 检测实验的默认超参数,除 genetic algorithm 需要探寻参数外,其他实验都用默认值。
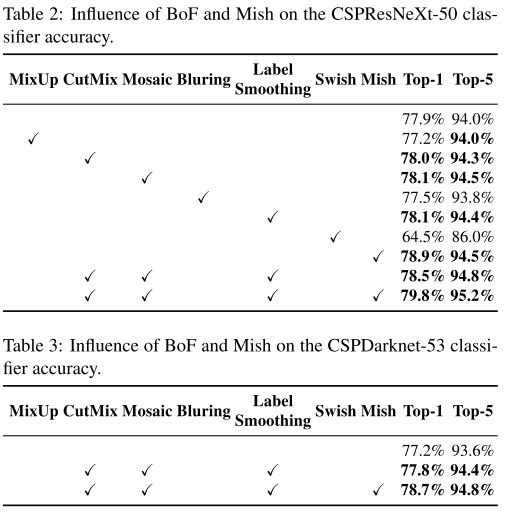
4.2. Influence of different features on Classifier training
表 2 展示不同功能对分类性能的影响。
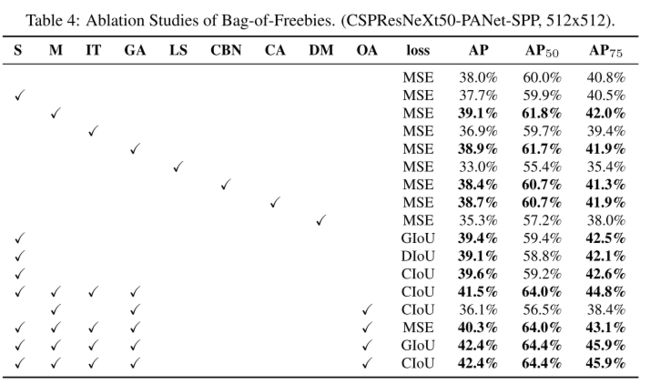
4.3. Influence of different features on Detector training
表 4 展示不同 Bag-of-Freebies (BoF-detector) 对检测性能的影响。表上都是 BoF 的缩写,右图是对缩写的解释。这些方法都是只影响准确率影响速度的方法。
 |
 |

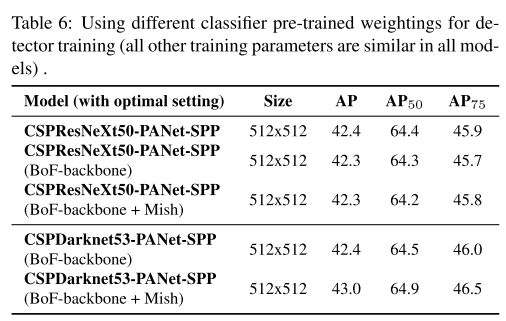
4.4. Influence of different backbones and pre-trained weightings on Detector training
表 6 展示不同骨干网络对检测性能的影响 。经过实验发现,分类准确率高的网络和技巧用于检测不一定效果好。
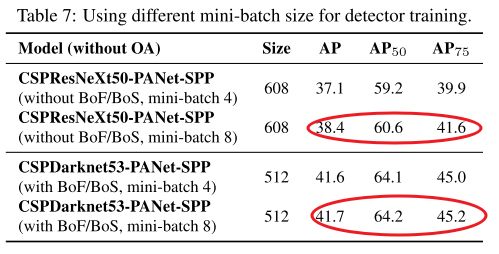
4.5. Influence of different mini-batch size on Detector training
表 7 展示不同 batch-size 对检测性能的影响 。实验发现,使用 BoF 和 BoS 等技巧,batch-size 对性能影响不大,所以没必要用昂贵的 GPU 训练,换句话说,传统 GPU 就能训练出一个很棒的检测器。
5. Results
通过和其他 state-of-the-art 方法比较,YOLOv4 方法位于 Pareto optimality curve ,无论是速度还是准确率都超过最快最准确的检测器。
结果图很多很长,具体去论文找(图 8 和表 8,9,10)
6. Conclusions
本文提出一个 state of the art 检测器,它检测更快(FPS)更精确(MS COCO AP50…95 and AP50)。
作者验证了大量技巧,并选择性地使用这些技巧来提高分类器和检测器的准确性。
这些技巧可用于未来研究和开发。