十大最受欢迎的AI模型
来源:mush博客
虽然人工智能和机器学习为企业改善运营和最大化收入提供了充足的可能性,但没有“免费午餐”。
在 “没有免费的午餐”问题是古老的“没有一个放之四海而皆准的所有”问题的AI / ML行业适应。企业面临的一系列问题是巨大的,用于解决这些问题的ML模型的种类非常广泛,因为有些算法在处理某些类型的问题方面比其他算法更好。如上所述,人们需要清楚地了解每种类型的ML模型的优点,今天我们列出了10种最流行的AI算法:
1.线性回归
2.逻辑回归
3.线性判别分析
4.决策树
5.天真的贝叶斯
6. K-最近邻居
7.学习矢量量化
8.支持向量机
9.套袋和随机森林
10.深度神经网络
我们将在下面解释所有这些算法的基本功能和应用领域。但是,我们必须事先解释机器学习的基本原理。
所有机器学习模型旨在学习一些函数(f),它提供输入值(x)和输出值(y)之间最精确的相关性.Y = F(X)
最常见的情况是,当我们有一些历史数据X和ÿ时,可以部署AI模型以提供这些值之间的最佳映射。结果不能100%准确,否则,这将是一个简单的数学计算,无需机器学习。相反,我们训练的f函数可用于使用新X预测新Y,从而实现预测分析。各种ML模型通过采用多种方法实现了这一结果,但上述主要概念仍未改变。
线性回归
到目前为止,线性回归在数学统计中使用了200多年。算法的要点是找到这样的系数值(B),它们对我们试图训练的函数f的精度产生最大的影响。最简单的例子是
y = B0 + B1 * x,
其中B0 + B1是有问题的函数
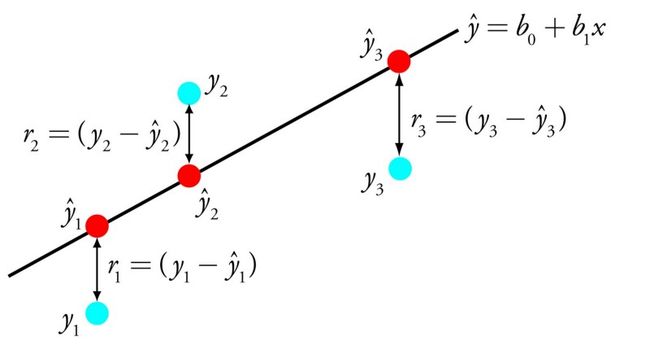
通过调整这些系数的权重,数据科学家可以获得不同的训练结果。成功使用该算法的核心要求是在其中没有太多噪声(低值信息)的清晰数据,并删除具有相似值(相关输入值)的输入变量。
这允许使用线性回归算法来对金融,银行,保险,医疗保健,营销和其他行业中的统计数据进行梯度下降优化。
后勤回归
物流回归是另一种流行的AI算法,能够提供二进制结果。这意味着模型可以预测结果并指定Ÿ值的两个类别之一。该函数也基于改变算法的权重,但由于非线性逻辑函数用于转换结果的事实而不同。此函数可以表示为将真值与虚值分开的小号形线。
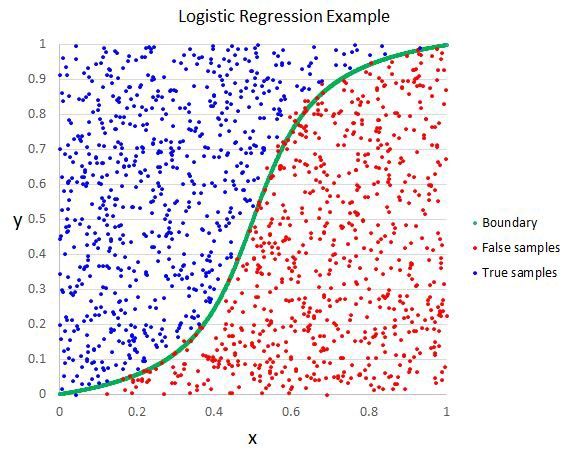
成功要求与线性回归相同 – 删除相同的值输入样本并减少噪声量(低值数据)。这是一个非常简单的功能,可以相对快速地掌握,非常适合执行二进制分类。
线性判别分析(LDA)
这是逻辑回归模型的一个分支,可以在输出中存在两个以上的类时使用。在该模型中计算数据的统计特性,例如每个类别的平均值和所有类别的总方差。预测允许计算每个类的值并确定具有最大值的类。为了正确,该模型要求根据高斯钟形曲线分布数据,因此应事先去除所有主要异常值。这是一个非常简单的数据分类模型,并为其构建预测模型。
决策树
这是最古老,最常用,最简单和最有效的ML模型之一。它是一个经典的二叉树,在模型到达结果节点之前,拆分每次都有“ 是”或“ 否”决定。

该模型易于学习,不需要数据规范化,可以帮助解决多种类型的问题。
朴素贝叶斯
。朴素贝叶斯算法是一个简单但非常强大的模型,解决用于复杂各种问题它可以计算出两种类型的概率:
1.每个班级出现的机会
2.给定一个独立类的条件概率,给出一个额外的X修饰符。

该模型被称为天真,因为它假设所有输入数据值彼此无关。虽然这不能在现实世界中发生,但是这种简单的算法可以应用于多种标准化数据流,以高精度地预测结果。
K-Nearest Neighbors
这是一个非常简单且非常强大的ML模型,使用整个训练数据集作为表示字段。通过检查具有相似值的ķ个数据节点的整个数据集(所谓的邻居)并使用欧几里德数(可以基于值差异容易地计算)来确定结果值的预测来确定结果值。
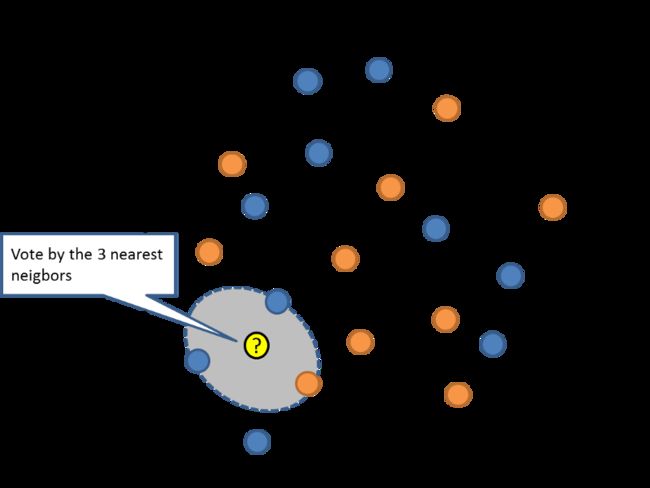
这样的数据集可能需要大量的计算资源来存储和处理数据,当存在多个属性并且必须不断地进行策划时会遭受精度损失。但是,它们工作速度极快,在大型数据集中查找所需值时非常准确和高效。
学习矢量量化
KNN唯一的主要缺点是需要存储和更新大型数据集。学习矢量量化或LVQ是演化的KNN模型,神经网络使用码本向量来定义训练数据集并编码所需的结果。如上所述,矢量首先是随机的,并且学习过程涉及调整它们的值以最大化预测精度。

如上所述,找到具有最相似值的向量导致预测结果值的最高准确度。
支持向量机
该算法是数据科学家中讨论最广泛的算法之一,因为它为数据分类提供了非常强大的功能。所谓的超平面的英文用不同的值分隔数据输入侧节点的线,从这些点到超平面的向量可以请立即获取iTunes它(当同一类的所有数据实例都在超平面的同一侧时)或者无视它(当数据点在同类平面之外时)。

最好的超平面将是具有最大正向量并且分离大多数数据节点的超平面。这是一个非常强大的分类机器,可以应用于各种数据规范化问题。
随机决策森林或套袋
随机决策森林由决策树组成,其中多个数据样本由决策树处理并且结果被聚合(如收集袋中的许多样本)以找到更准确的输出值。

不是找到一条最佳路线,而是定义多条次优路线,从而使整体结果更加精确。如果决策树解决了您所追求的问题,那么随机森林是一种方法中的调整,可以提供更好的结果。
深度神经网络

DNN是最广泛使用的AI和ML算法之一。有在显著改善深基于学习的文本和语音应用程序,机器感知深层神经网络和OCR,以及使用深度学习授权加强学习和机器人的运动,与DNNs的其他杂项应用程序一起。
关于10种最流行的AI算法的最终思考
如您所见,有各种各样的AI算法和ML模型。有些更适合数据分类,有些则优于其他领域。没有适合所有尺寸的型号,因此为您的箱子选择最佳型号至关重要。
如何知道这个型号是否合适?考虑以下因素:
- 您需要处理的3 V大数据(输入的数量,种类和速度)
- 您可以使用的计算资源数量
- 您可以花在数据处理上的时间
- 数据处理的目标
如上所述,如果某种模型以超过两倍的处理时间为代价提供94%的预测精度,那么与86%的精确算法相比,选择的种类就会大大增加。
然而,最大的问题通常是缺乏设计和实施数据分析和机器学习解决方案所需的高级专业知识。这就是为什么大多数企业选择专门从事大数据和AI解决方案的托管服务提供商之一。