Quantopian 入门系列二 - 流水线 (下)

本文含 8225 字,28 图表截屏
建议阅读 42 分钟
本贴接着上贴〖Quantopian 入门系列二 - 流水线 (上)〗的内容,讨论下面目录的 5- 8 节:
简介
因子
筛选器
分类器
掩码法
数据集
自定义因子
回测
5
掩码法
现在我们已经会用筛选器(filter)来忽略某些资产,比如要筛选出的 30 天平均金额大于 $10,000,000 的股票,我们可以把 high_dollar_volume 过滤器传给 screen 参数,见以下代码的高亮部分。

这种在最后关头做筛选的做法绝对没错,但是效率不高。如果 SimpleMovingAverage 这个函数运算比较昂贵,那么一开始我们把很多时间浪费在我们不想要的资产身上。
现在介绍另一种高效的筛选方法,叫做掩码(masking)法,我们既可以掩码因子(mask factors)也可以掩码筛选器(mask filters)。
它之所以高效就是因为我们不用等到最后筛选,在计算因子时就可以同时做筛选了。
首先引入所有需要的包:

掩码因子
我们只需要改变 make_pipeline() 里面几行代码的顺序。一开始就定义好 dollar_volume 并设置好 high_dollar_volume 筛选器,然后再把它传递给 SimpleMovingAverage 函数里的 mask 参数,见以下代码的高亮部分。

通过掩码方法,SimpleMovingAverage 只用在 2000+ 个资产上,而之前用在 8000+ 个资产上,效率一下子就提高了 4 倍左右。
掩码筛选器
掩码方法也可以应用于筛选器,比如 top,bottom 和 percentile_between 等。
掩码在组合筛选器中用处最大。举例,假设我们要层层筛选资产:
首先在全部资产中选出平均交易额排名在前 10% 的资产(集合 1)
接着在集合 1 中选出开盘价排名最高的前 50 个资产(集合 2)
最后在集合 2 中选出收盘价排名前 10% 的资产(最终目标集合)
我们可以执行以下操作:
用 AverageDollarVolume 计算出平均交易额因子。
用 percentile_between(90,100) 筛选出平均交易额排名前 10% 的资产,起名为 high_dollar_volume。(如果要筛选排名前 a% 的资产,应该用 percentile_between(100-a,100))
用 top(50, mask=xxx) 在上面集合中继续筛选出开盘价排名前 50 的资产,起名为 top_open_price。(用掩码方法把 high_dollar_volume 传递给 top() 里的 mask 参数)
用 percentile_between(90,100) 在上面集合中继续筛选收盘价出排名前 10% 的资产,起名为 high_close_price。(用掩码方法把 top_open_price传递给 percentile_between() 里的 mask 参数)
具体代码如下:
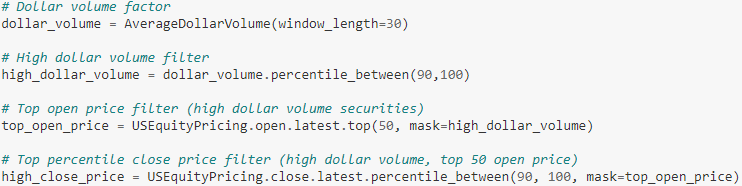
全部整理在 make_pipeline() 函数中,将 high_close_price 作为终极筛选器传递给 screen 参数。

看看流水线在 2019-11-25 上运行的结果(需要将起始日和终止日都设成 2019-11-25),发现满足上述那么多条件的资产只有 5 个,因为 50 × 10% = 5。
result = run_pipeline(make_pipeline(), '2019-11-25', '2019-11-25')
print('Number of securities that passed the filter: %d' % len(result))
Number of securities that passed the filter: 56
数据集
当我们创建流水线时,我们需要选定一个输入(inputs),而输入是由 DataSets 和 BoundColumns 联合确定的。
DataSets 是集合型变量,它帮助流水线找到计算时用的数据。之前我们用到的 USEquityPricing 就是一个 DataSet。
BoundColumn 是用一组列标签从 DataSet 获取得到的子集。之前我们用到的 USEquityPricing.close 就是一个 BoundColumn。
数据类型
在定义流水线计算时,知道输入数据的类型(data type, dtype)可以方便我们选择不同的操作。 例如,USEquityPricing 返回时浮点型,因此我们在 USEquityPricing.close 的结果上执行算术运算,比如计算 5 天平均值。
一般来讲,如果计算结果是
因子,那么数据类型是浮点型(float)
筛选器,那么数据类型是布尔型(bool)
分类器,那么数据类型是字符串(str)或整型(int)
定价数据
美股定价数据(pricing data)的可用 USEquityPricing 字段获得,而 USEquityPricing 里面有 5 个 BoundColumns:
USEquityPricing.open
USEquityPricing.high
USEquityPricing.low
USEquityPricing.close
USEquityPricing.volume
每一栏的数据都是浮点型数据。
基本面数据
Quantopian 也提供基本面数据(fundamental data),数据来源大多来自晨星(morning star)。在基本面数据下包含 900 多个 BoundColumns,具体详情可参考《Quantopian Fundamentals Reference 》。
https://www.quantopian.com/docs/data-reference/morningstar_fundamentals
使用基本面数据需要引入:
from quantopian.pipeline.data.morningstar import Fundamentals
另类数据
Quantopian 除了提供定价数据和基本面数据外,还有提供许多数据集,包括市场共识(market consensus)或新闻情绪(news sentiment)等,这些数据统称为另类数据(alternative data)。
另类数据的命名空间(namespace)为 quantopian.pipeline.data,两个例子如下:
quantopian.pipeline.data.psychsignal(交易情绪)
quantopian.pipeline.data.sentdex(社交平台上留言情绪)
与 USEquityPricing 相似,上面列出的两个数据集也带有 BoundColumns。Pyschignal 数据集含有 8 个 BoundColumns:
asof_date(数据类型datetime64[ns])bear_scored_messages(数据类型float)bearish_intensity(数据类型float)bull_bear_msg_ratio(数据类型float)bull_minus_bear(数据类型float)bull_scored_messages(数据类型float)bullish_intensity(数据类型float)total_scanned_messages(数据类型float)
Sentdex 数据集含有 8 个 BoundColumns:
asof_date(数据类型datetime64[ns])sentiment_signal(数据类型float)
BoundColumns 在我们自定义因子时尤为有用,下节来看看自定义因子。
7
自定义因子
在上贴〖Quantopian 入门系列二 - 流水线 (上)〗第 2 节里,我们探索了一组内置因子(build-in factors),而 Quantopian 里流水线中最强大的功能之一是允许我们可以自定义因子。
自定义因子(custom factor)本质上还是因子,因此它的构造函数也接受 input, window_length 和 mask 参数,并返回每日的 Factor 对象。
自定义因子:标准差
第一个自定义的例子是标准差(standard deviation),在 Quantopian 中要自定义因子最好的方法是将 quantopian.pipeline.CustomFactor 子类化来定义自己想要的类,并实现其类下的 compute() 方法,通用模板如下:
def compute(self, today, asset_ids, out, *inputs):
out[:] = ...
其中
*inputs 是一个 M x N 的 numpy 数组,M 是窗口的长度,而 N 是资产的个数。注意 * 符号表示这个 inputs 可以是任意数目,这个数目由你想获取特征的个数决定(即 BoundColumns 的个数)
self 是子类的实例本身
today 是一个包含时间戳的数据帧,compute() 函数就在这些时间戳上运行
asset_ids 是一组资产的整数型 ID,ID 的个数等于 inputs 的列数 N
out 是一组大小为 N 的空数组,里面的元素最终由 compute() 函数来填满
在流水线里的 CustomFactor 子类下面的实例会每天执行 compute() 函数,下面我们自定义标准差因子来计算资产过去 5 天的收盘价的标准差。
首先引入 CustomFactor 和 numpy。
from quantopian.pipeline import CustomFactor
import numpy
我们用 numpy.nanstd() 的方法来计算标准差,注意下面代码 compute() 函数中最后一个参数 values 就是 *inputs,只不过本例中 *input 只有一个。

最后在 make_pipeline() 实例化我们自定义的因子 std_dev。
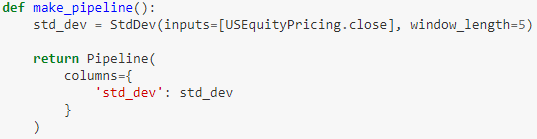
运行该流水线,并打印出首尾 5 行。
result = run_pipeline(make_pipeline(), '2019-11-25', '2019-11-25')
result.head().append(result.tail())

自定义因子:均值
在自定义因子时,我们可以在 CustomFactor 的子类下重设默认参数 inputs 和 window_length。
在下例中,我们用 numpy.nanmean() 的方法来计算均值,将默认参数 inputs 和 window_length 设为
inputs = [USEquityPricing.close, USEquityPricing.open]
window_length = 10
这样就可以定义一个计算收盘价和开盘价的 10 天均值差的子类了。
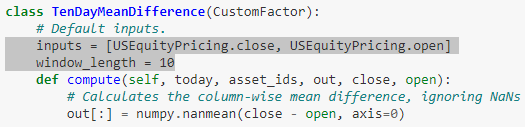
如果在调用 TenDayMeanDifference 类时不设定任何参数,那么 compute() 函数就是用其默认值,即
inputs = [USEquityPricing.high, USEquityPricing.high]
window_length = 10
# Computes the 10-day mean difference between
# the daily open and close prices.
close_open_diff = TenDayMeanDifference()
我们也可以通过在构造函数中设定指定参数,来手动覆盖(override)默认值。假设这时我们想看最高价和最低价,将 inputs 设成 [USEquityPricing.high, USEquityPricing.low] 即可,window_length 仍用其默认值 10。
# Computes the 10-day mean difference between
# the daily high and low prices.
high_low_diff
= TenDayMeanDifference(inputs=[USEquityPricing.high,
USEquityPricing.low])
自定义因子:动量
我们自定义动量为 n 天前的收盘价除以最新的收盘价,其中 n 等于 window_length。
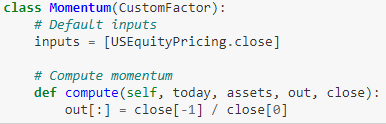
现在我们创建两个动量因子,10 天和 20 天动量。此外再定义个正动量筛选器(当 10 天和 20 天动量之差为正返回 True,此外返回 False)。

接下来,把计算出来的 positive_momentum 因子构建成筛选器,并传到流水线里的 screen 参数。

运行此流水线将输出 10 天和 20 天动量为正的资产的标准差和 10 天、20 天的动量。
result = run_pipeline(make_pipeline(), '2019-11-25', '2019-11-25')
result.head().append(result.tail())

到此我们已经捋清流水线里面所有的知识点,下节我们做一个完整的交易策略算法并附上回测结果。
8
回测
筛选器
首先让我们创建一个完整的筛选器,只选择满足以下所有条件的证券:
新股(primary share)
普通股(common stock)
不是存托凭证(ADR / GDR)
不在场外交易(OTC)
不是待发行(when-issued, WI)
不是有限合伙(LP)
不是交易所交易基金(ETF)
筛选逻辑
选择新股和普通股是每个公司的代表性资产。
ADR 和 GDR 是在美国股票市场上在其他交易所交易的股票的发行。通常由于汇率波动,它们存在外汇风险,因此我们将它们剔除。
大多数经纪商交易不参与 OTC,WI 和 LP 股票,因此我们将它们剔除。
我们来创建一个满足以上所有条件的综合筛选器 tradeable_stocks。
from quantopian.pipeline.data import Fundamentals
from quantopian.pipeline.filters.fundamentals import IsPrimaryShare
primary_share = IsPrimaryShare()
common_stock = Fundamentals.security_type.latest.eq('ST00000001')
not_depositary = ~Fundamentals.is_depositary_receipt.latest
not_otc = ~Fundamentals.exchange_id.latest.startswith('OTC')
not_wi = ~Fundamentals.symbol.latest.endswith('.WI')
not_lp_name = ~Fundamentals.standard_name.latest.matches('.* L[. ]?P.?$')
not_lp_balance_sheet = Fundamentals.limited_partnership.latest.isnull()
have_market_cap = Fundamentals.market_cap.latest.notnull()
# Filter for stocks that pass all of our previous filters.
tradeable_stocks = (
primary_share
& common_stock
& not_depositary
& not_otc
& not_wi
& not_lp_name
& not_lp_balance_sheet
& have_market_cap
)
接着,我们可以把 tradeable_stocks 传给 mask 参数来创建一个新的筛选器,叫做 base_universe。
base_universe
= AverageDollarVolume(window_length=20,
mask=tradeable_stocks)
.percentile_between(70, 100)
内置筛选
我们在上面自定义了一系列的筛选条件得到一个可交易的集合 base_universe,但每次这样做太麻烦。在 Quantopian 中有自己内置的一个可交易的集合,叫做 QTradableStocksUS。
from quantopian.pipeline.filters import QTradableStocksUS
base_universe = QTradableStocksUS()
基于 base_universe,现在我们可以构建一个股票多空组合,多和空是根据 10 天和 30 天的收盘价移动平均差值所决定。具体代码如下:
# 10-day close price average.
mean_10
= SimpleMovingAverage(inputs=[USEquityPricing.close],
window_length=10,
mask=base_universe)
# 30-day close price average.
mean_30
= SimpleMovingAverage(inputs=[USEquityPricing.close],
window_length=30,
mask=base_universe)
percent_difference = (mean_10 - mean_30) / mean_30
# Create a filter to select securities to short.
shorts = percent_difference.top(75)
# Create a filter to select securities to long.
longs = percent_difference.bottom(75)
securities_to_trade = (shorts | longs)
上面代码的 16 和 18 行将 percent_difference 值最大的 75 个股票选出来做空,把 percent_difference 值最小的 75 个股票选出来做多,很明显这是个均值回归(mean-reversion)的策略。因为 percent_difference 越大,10 天 MA 越比 30 天 MA 大,价格短期向上,如果追趋势那应该做多,如果赌回归那应该做空。
将 securities_to_trade 传给 screen 参数,定义下面的流水线。

运行该流水线得到每只股票被做多或做空的布尔值,结果如下:
result = run_pipeline(make_pipeline(), '2019-11-25', '2019-11-25')
result.head().append(result.tail())

回测
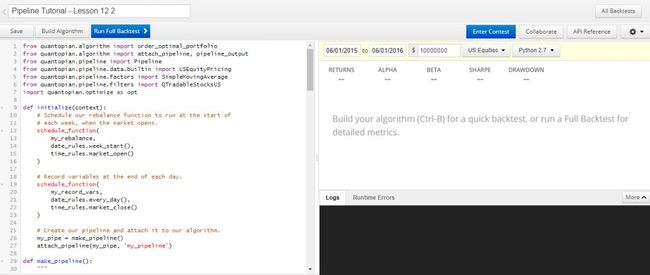
在研究环境中用 make_pipeline() 把流水线已创建好,我们可以将它搬到回测环境中,并加上 initialize(), before_trading_start(), schedule_function() 等。回测环境界面如下:
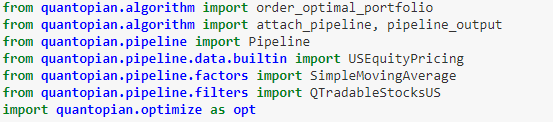
首先引入所有必要的包:
make_pipeline() 直接可从研究环境复制到回测环境中。

初始化要做的三件事:
每周开市前计算重组组合的权重 my_rebalance
每天闭市后计算组合的杠杆和多空头寸 my_record_vars
用 attach_pipeline() 将创建好的流水线附在交易算法上

开盘前要做的两件事:
用 pipeline_output() 获取流水线的输出
根据第一步输出划分多空资产,并检查它们是否可交易
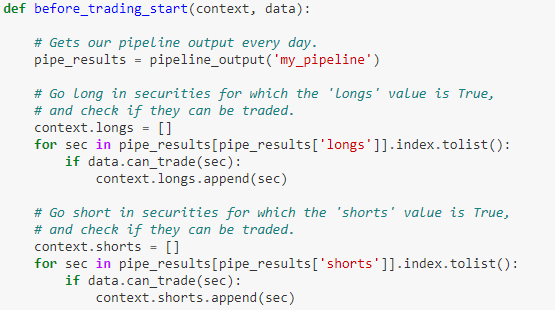
给多头资产赋予 0.5/Nlong 的权重,给空头资产赋予 -0.5/Nshort 的权重,给不能交易的资产赋予 0 权重。

每周开始市场开盘要做的事,在 initialize() 里面的 schedule_function() 里面设定。做的事情就是按多空来分配等权重(equal weights)。

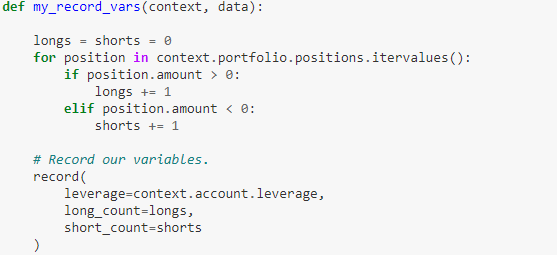
每天结束市场收盘要做的事,在 initialize() 里面的 schedule_function() 里面设定。做的事情就是记录组合里的杠杆(leverage)和多空头寸的数量。
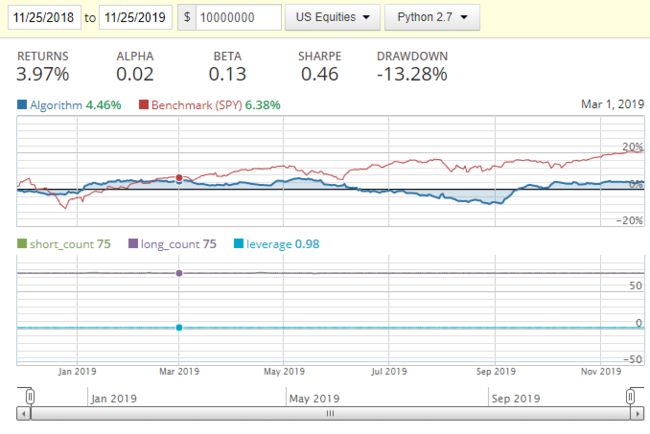
在 2018-11-25 到 2019-11-25 期间做回测,设置如下:
![]()
贝塔 0.13 和大盘基本走势无关,这个很好。收益 3.97%,虽然为正但是远远跑输大盘。夏普 0.46 也很一般。但这些指标的数值都不是重点,交易策略算法可以自由发挥,本帖只是展示如何创建流水线、制定交易算法、和运行回测。
9
总结
流水线就是一个动态选择资产(dynamic security selection)的大杀器,我们可以在多个时点在多个资产中的多维特征上定义一系列运算,整个集合有四个维度:
时点个数(选定起始日和终止日)
特征个数(用 BoundColumns)
资产个数(用 screen 和 mask)
窗口长度(用 window_length)
一图胜千言是我的最爱,不解释。

下帖讲用于因子分析的 Alphalens。Stay Tuned!
