『金融数据结构』「3. 基于事件采样」

本文是 AFML 系列的第三篇
金融数据类型
从 Tick 到 Bar
基于事件采样
在上贴〖从 Tick 到 Bar〗里,我们已经会从「异质」的 tick 数据采样出「同质」的 bar 数据。当数据太多时,传统 (非深度) 机器学习算法的表现会有上限,如下图的红线所示。

这时减少数据量并发掘出更好特征的数据才能使机器学习算法取得好效果。通常有两种方法:
无脑型下采样(downsampling)
基于事件采样(event-based sampling)
第一种又可细分为线性等分采样(linspace sampling) 和均匀采样(uniform sampling)。它们虽然可以做到减少数据量,但是采样数据的方法都没有金融含义支撑,线性等分采样过于简单,均匀采样过于随机。 因此本帖来看看第二种基于事件采样,即背后有金融含义支撑的采样方法。
想想投资组合经理买卖是不是通常发生在特定事件发生后,如
结构性突破 (structural break):均值回归模式 → 动量模式
市场微观结构 (market microstructure ):FIX 信息
这些事件通常伴随着下面三种场景
宏观统计数据公布
波动率急剧增加
价格大幅偏离均衡水平
本帖内容很简单,只围绕着一个公式展开。但困难的是当我用标普 500 价值股 ETF的高频 tick 的数据的时候,做了很多数据处理的工作。这些很麻烦但又非常重要,因此我也想将这个处理数据的完整过程记录下来,防止以后再踩坑。
首先引入 datetime, numpy, pandas, matplotlib, seaborn 等必要的包,并定义我最喜欢的一些颜色 (看过我盘一盘 Python 系列的读者应该知道我的喜好  )。
)。
from datetime import datetimeimport numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport seaborn as sns
dt_hex = '#2B4750' # darkteal, RGB = 43,71,80r_hex = '#DC2624' # red, RGB = 220,38,36g_hex = '#649E7D' # green, RGB = 100,158,125tl_hex = '#45A0A2' # teal, RGB = 69,160,162tn_hex = '#C89F91' # tan, RGB = 200,159,145
此外我还会用两个额外的工具包 mlfinlab 和 pathlib ,到使用它们的时候再解释。
1.1
源数据
我们使用的标普 500 价值股 ETF (IVE) tick 级别的数据从来自以下链接。
http://www.kibot.com/free_historical_data.aspx
想投资指数就可以买 ETF。比如我看好美国股票市场,但又不想投资个股,那么可以投资标普 500 指数,用的金融工具就是其 ETF,代号为 IVE。
今天 (2019 年 8 月 1 日) 下载 IVE 的数据是从
2009 年 9 月 28 日早上 9:30
到
2019 年 7 月 31 日下午 16:00
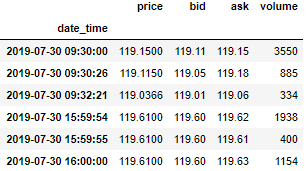
数据存在 txt 格式,如下图所示 (注意最后三条数据的时间晚于下午 16:00,但是成交量为 0)。

1.2
处理数据
文本 txt 里面的 6 栏数据没有标题栏,我们去上面链接找到每一栏分别是
日期、时间、价格、买价、卖价、成交量
如下图所示:

接下来我们用 pandas 读取将数据转换成 DataFrame,并做一些处理,用的是下面 IO 函数。

第 2 行定义好 6 栏数据的名称,'date', 'time', 'price', 'bid', 'ask', 'volume'。
第 4-9 行是核心代码。
第 4 行用 read_csv 函数来从路径为 in_path 的文本读取数据。
第 5行将上面定义好的数据栏名称作为 DataFrame 的 columns。
第 6 行将日期 (date) 和时间 (time) 合并,用 assign 函数将合并栏起名为 date_time 栏。从 txt 文本可看出
![]()
日期的格式是 '%m/%d/%Y',时间的格式是'%H:%M:%S'。
第 8 行用 drop 函数把date 和 time 栏删掉,因为已经有 date_time 栏了,信息重复了。
第 9 行把用 set_index 函数把 date_time 栏作为 index。
五行代码就把处理完了,Python 写起来真的很方面。现在有个问题是数据太大了,用快 7000000 条数据。储存成 csv 供以后加载速度会慢,因此我们选择将 DataFrame 存储成 Parquet 格式。原理不需要理解,Parquet 格式的数据变小了很多,加载也快了很多。
第 10 行就是用 to_parquet 做上面说的事,唯一需要注意是要选取 engin 参数为 'pyarrow' 或者 'fastparquet'。运行报错了的先装 pyarrow 工具包。
pip install -U pyarrow运行代码完成读取和存储步骤。读取的 txt 和 parquet 文件都放在【.../data/】路径中,PurePath() 可以自动帮你找到当前目录,我们只有加写后缀即可。首先从 pathlib 里引入 PurePath 工具包。
from pathlib import PurePath

从下图显示了 txt 和 parquet 文件的大小可看出,数据从 300 MB压缩到 47 MB。

存好 parquet 格式之后为了方面以后直接读取。看看这高频数据量,6927699 条 tick 数据。
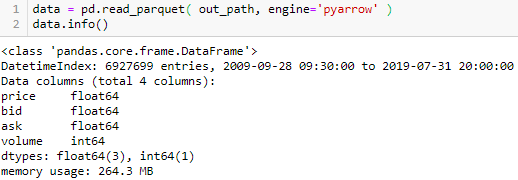
让我们看看数据的前 10 行。
data.iloc[:10,:]
发现出来什么问题么?有很多重复的数据!要么是 date_time 重复了,要么是整行重复了。一开始我以为是操作错误,准备用 drop_duplicate 函数将重复值删去,后来发现有太多类似情况,不可能全是操作错误,后来读到了下面这句话。
![]()
蓝色高亮部分说的是上面 tick 数据并没有整合,而是一条一条收集的。其实每条数据的时间戳 (timestamp) 不见得刚好精准到秒,有的可能发生在毫秒,比如在 8:30:00:001 和 8:30:00:057 时点上交易的两条数据都被记录成8:30:00 上交易。这样一个 date_time 很可能对应若干条数据。
我们进一步要做的是在每个 date_time 做一些整合 (aggregrate) 操作,那么就要召回老朋友 pandas 里面的 groupby + aggregate 函数了。


代码很简单,先用 groupby(data.index) 在 date_time 分组,在每个不同 date_time 值下得到一个 DataFrame。
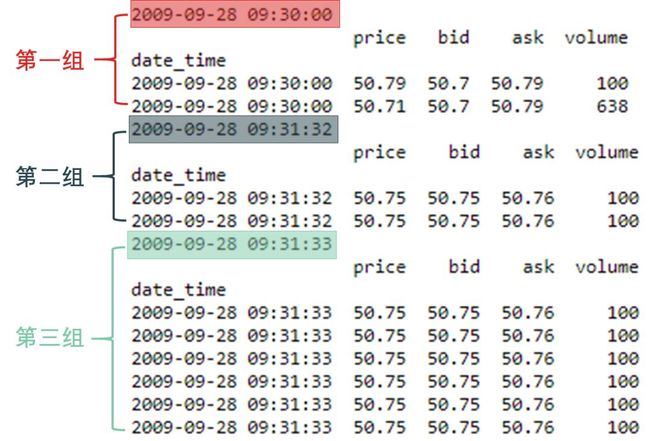
下一步就用 aggregate 来整合了,关键是以什么样的方式来整合呢?
price, bid, ask 栏按求平均的方式整合,用 mean 函数
volume 栏按求和的方式整合,用 sum 函数
其实对于 price, bid, ask 栏 更好地整合方式使用 vwap,但需要用到 volume 栏的数据,我弄了半天没有成功就放弃了,会弄的人请留言 
具体代码见第 1-4 行,以字典的形式来设定 - {栏名称 : 函数名},比如 {'price' : 'mean'}。
从整合前到整合后的过程图如下:

最后看看数据里有没有什么异常值 (outlier),用 seaborn 里面的 boxplot 看一秒看出来,如下面代码和图。
fig = plt.figure( figsize=(8,4), dpi=100 )sns.boxplot(data.price)plt.show()
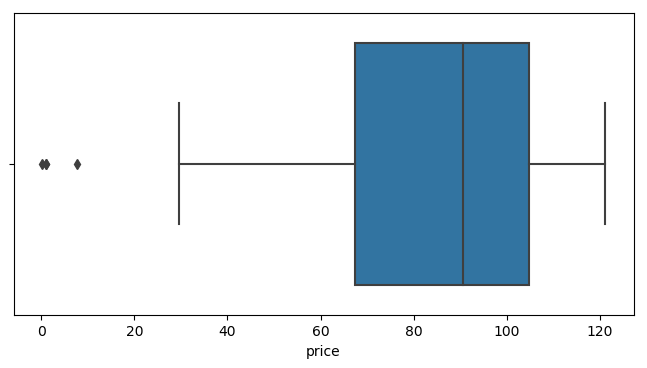
从上图最左边几个点的值 IVE 的价格有几个在 0-10 之间,显然是错误记录。我们用 median absolute deviation (MAD) 的方法来确定异常值,公式如下
![]()
其中
x^ 是 x 的中位数
MAD 是 xi - x^ 的中位数
0.6745 是正态分布的 75 分位值
下面代码就把上面公式实现一遍,算出分数 score 和阈值 threshold 比,当 score > threshold 时认定有异常值。

找出异常值的索引 idx 并看有几个。
idx = mad_outlier( data.price.values )data.loc[idx]

在百万条数据中只有 4 个,可直接删除。首先看看不带异常数据的 boxplot,一切正常。
fig = plt.figure( figsize=(8,4), dpi=100 )sns.boxplot( data.loc[~idx].price )plt.show()

现在可以大胆的删除这 4 条异常数据。
data = data.loc[~idx]data.info()
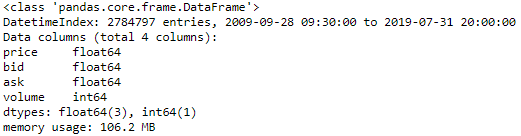
最后我们还发现有些数据的成交量为零,也将其删除。
data = data.loc[data.volume != 0]data.info()

经过整合重复的 date_time 和删除 price 和 volume 的异常值后,6927699 条数据减少到 2782620 条,现在数据已经是干净的了,可以对其进行骚操作了。
2.1
Tick 数据
我们拿 2019 年 7 月 30 日的数据举例。
s_date='2019-07-30 8:00:00'e_date='2019-07-30 17:00:00'df = data.loc[s_date:e_date]df.head(3).append(df.tail(3))
首先不做任何采样,画出 tick 数据的价格折线图。
plt.figure( figsize=(16,8), dpi=72 )data.loc[s_date:e_date].price.plot( color=r_hex )
为了快,我们在 pandas 的 DataFrame 上直接用里面的 plot 函数,而没有用 matplotlib.pyplot。
从上贴〖从 Tick 到 Bar〗可知,在量化中,很多时候并不需要每条 tick 的高频信息,我们需要的是从中进行有效的采样,最常见的是 dollar bar (等成交额采样)。
2.1
Dollar Bar 数据
假设我们关注分钟级别的数据,那么如果在 2019 年 7 月 30 日内要采样 Time Bar 数据时,需要 390 个 Bar,计算如下:
num_time_bars = (df.index[-1] - df.index[0]).total_seconds() / 60num_time_bars
390当天总成交额为
total_dollar = np.sum(df['price']*df['volume'])total_dollar
47727823.56948571总成交额平分到 390 个 Bar 上,每个 Bar 大概包含 119300 的成交额 (精确到百)
dollar_per_bar = total_dollar / num_time_barsdollar_per_bar = int(round( dollar_per_bar, -2))dollar_per_bar
119300接着我们使用 mlfinlab 里面的内置函数 get_dollar_bars 来做等交易额采样。首先引入其工具包。
import mlfinlab as mlget_dollar_bars 该函数只能从 csv 中读取数据,而且
columns 也只能是含 'date_time', 'price' 和 'volume',因此第 2 行将 'bid' 和 'ask' 栏用 drop 函数删除
不能有 index,因此第 4 行设置 index=False
我们写了下面函数来生成符合 get_dollar_bars 条件的 csv。
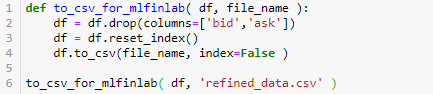
refined_data.csv 的前 10 行展示如下:

现在可以愉快的用 mlfinlab 的内置函数 get_dollar_bars 函数生成 dollar bar 了。
查看一下 dollar bar 的头三行和尾三行。
dollar.head(3).append(dollar.tail(3))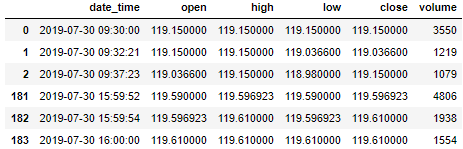
画出 dollar bar 的折现图。

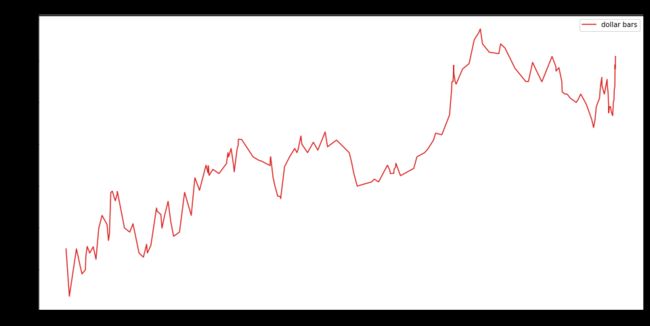
Dollar bar 折线图比起 tick 折线图是不是没那么多上下波动,少了好多噪音。
2.3
基于事件采样
在进行「基于事件采样」之前,我们现在看 AFML 书中第 40 页中这样一句话 (红色高亮部分)。

上句话中 CUSUM filter 决定什么样的事件被触发 (方法很多,书中这一章给出一个方法)。作者拿 CUSUM filter 和 Bollinger bands 相比,发现后者没有像前者触发出很多“有价值”的事件 (multiple events are not triggered )。
第一次读,不知道作者在说什么,那就可视化实际数据来慢慢探索两者的差别吧。
首先回顾下 Bollinger bands 是什么,在〖盘一盘 PyEcharts〗第 1.3 节有详细解释。
价格就在这个区间的上限和下限之间进行波动。而这条带状区间的宽窄也会随着价格波动幅度的大小而变化。
价格涨跌幅度加大时,带状区变宽。
价格涨跌幅度变小时,带状区变窄。
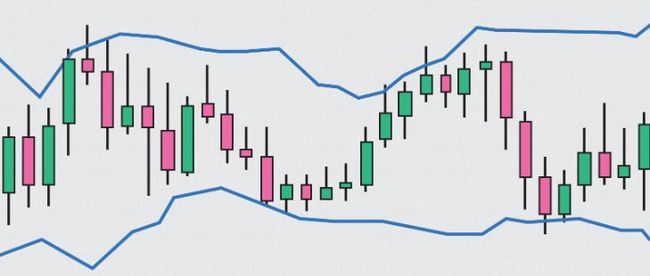
布林线由三条曲线组成,分别是上轨线 (upper band)、中轨线 (mid band) 和下轨线 (lower band)。上图只画出上轨线和下轨线。
一般来说,下轨对价格有支撑作用,上轨对价格有阻力作用
当价格穿越上轨 (冲破阻力了),买入
当价格穿越下轨 (冲破支撑了),卖出
因此根据布林带我们可以找到一些触发事件 (用来买卖),首先根据其定义求出上轨、下轨和中轨。
N = 20K = 2mean = dollar.close.rolling(N).mean()stdev = dollar.close.rolling(N).std()upper_band = mean + K*stdevlower_band = mean - K*stdev
设定「10 日 MA 」和「2 倍波动率」
上轨线 = 10 日 MA + (10 日波动率 x 2)
中轨线 = 10 日 MA
下轨线 = 10 日 MA - (10 日波动率 x 2)
将上轨、下轨、中轨和价格序列整合成一个 DataFrame, df_bb。

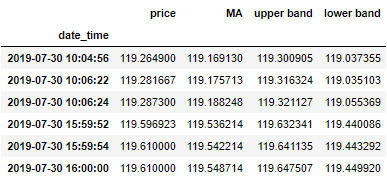
接着写两个函数,即
up_cross 来识别上轨被击破,price(t-1) < UB(t-1) 和 price(t) > UB(t) 两个条件要同时满足
down_cross 来识别下轨被击破,price(t-1) > LB(t-1) 和 price(t) < LB(t) 两个条件要同时满足

由下图运行结果可知,上轨被击破 5 次,下轨被击破 2 次。
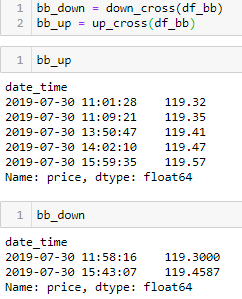
将这些「触发事件」点在布林带图中画出来。

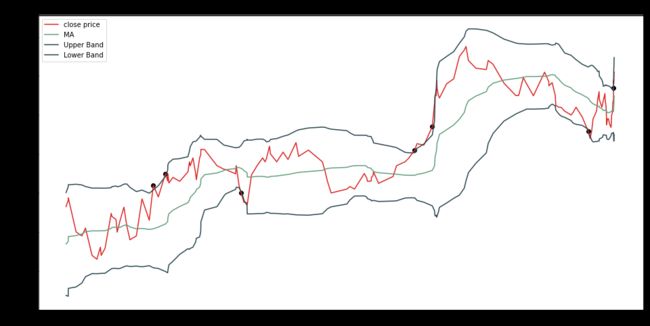
看了这幅图我大概明白 AFML 作者的意思了,在很多上下轨没有击破的时候也有些包含重要特征的事件点,但是根据布林带的触发条件,并没有采样出来。
接下来看看作者在书中提出的 CUSUM Filter。
CUSUM 其实就是 cumulative sum 的缩写,就是某个变量的累加,而 filter 是过滤器,两个词放在一次,实际上就是一种「当一个变量累加到某个程度,触发事件」的检测方法。
本质很朴素,但是书却写的晦涩难懂,妈的搞量化金融的都是这个 __ 样吗?
数学表达式如下:

其中 yt 是一组独立同分布变量 (收益率或波动率等等),而 St 是 yt 是累积量:
S+ 表达式中有和 0 取最大值,因此代表向上累积量
S- 表达式中有和 0 取最小值,因此代表向下累积量
那么累积到到什么时候停止呢?或者什么时候触发事件呢?这时需要定义一个阈值 h,当
S+ > h 并重设 S+ 为 0
S- < -h 并重设 S- 为 0
重设为 0 意思就是这一波过去了,重新再累积玩呗。上式中 Et-1[yt] 有很多表达形式,最简单就是
Et-1[yt] = yt-1
上面意思弄懂了,下面代码可以秒懂 (我注释写的挺详细的)。

给分钟级别的收益率定为 0.04% 作为触发事件的条件,来看看 2019 年 7 月 30 日内有多少个样本。看结果有不少呢,比布林带的多。

将这些「事件」点和价格一起画出来。


图中的深青色的点就是我们需要采样的点。当然不同的阈值 h 会得到不同的样本,用到机器学习中,h 也是个超参数,需要被调节。
处理数据永远是最花精力和时间的,机器学习是,量化金融也是,数据科学更是。你获取的源数据格式和你想用的格式总是差别很远,务必在处理数据上下功夫,要不然胡乱使用一通模型只会 Garbage In Garbage Out。
我们已经学会了如何从「非结构性」的杂乱金融数据转换成同质的「结构性」的数据,但是直接把它们丢进机器学习 (ML) 模型中还是会出问题的,原因有二:
一些 ML 模型,比如支撑向量机 (Support Vector Machine, SVM),随样本量变化的表现不稳定。
ML 模型在输入好的特征后,得到的精度才最佳。
为了让 ML 模型表现稳和精度高,我们需要更聪明的采样方法,基于事件采样就是其中之一。
要能更深入了解基于事件采样,我们可能要等到读完 AMFL 的第 17-19 章了:

Stay Tuned!
.jpg")
机器学习、金融工程、量化投资的干货营;快乐硬核的终生学习者。
