pandas介绍——实例分析:泰坦尼克号数据分析(10)
这次利用pandas来做一个实际案例分析。分析的案例这里提供了百度网盘供大家下载。我们要做一个泰坦尼克号的案例分析。
https://pan.baidu.com/s/1cc5olt9ZUCXkvaRx-bP1YQ
这是一个很好的入门教程~案例分析的背景说的是,船要沉了,我们根据各种影响因素,判断船上成员的存活率,比如头等舱的人存活率是不是会更高呢?或者女人比男人活下来的概率更高呢?
下载这个文件后,将其放入jupyter notebook的根目录里面。

在windows系统下,在安装jupyter notebook的时候,应该会建立一个文件夹,用于储存放在jupyter notebook上的文件的,我们只需要简单的将文件下载好然后复制粘贴进来就可以了,然后用命令行打开jupyter notebook后,该文件就会自动出现在这里。
ok下面开始正式操作。
第一步,进入jupyter notebook并且导入文件。
df=pd.read_csv('train.csv')在这里我们把该文件导入了,并命名为df。
那我们看一下它的shape()
df.shape输出:
(891, 12)我们可以看到,这个文件有891行,12列。所以我们可以不用把它全部打开看,只看它前5行暂时就够了
df.head(5)输出:

在这里可以看到,每一个成员具有12个属性,比如Survived这个属性,只有1和0两个值,代表活下来了和死了,Pclass这个属性,代表着乘客的客舱等级等等
总共891个成员,我们利用之前所学的 isnull() 函数来观察一下
# 计算所有空值的总和
# 会发现,Cabin有687个空值
df.isnull().sum()输出:
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
同样,我们观察各个属性的类型
# 在这里可以观察各个元素的属性
# 当然这个结果是系统自动识别的
# 一般来说,Name,Sex等属性应该是String属性
# 但在python里,会自动默认为 object 属性
df.dtypes输出:
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object之前提到的,我们读取这个数据是为了判断,有多少人活下来。我们可以直接读取Survived这个属性的值
# 可以利用属性+value_counts()这个函数来查看元素具体的值
# 可以看到,活下来342个,死了549个
df.Survived.value_counts()输出:
0 549
1 342
Name: Survived, dtype: int64得到了活下来和挂掉的人数,我们可以把它用柱状图画出来
# 可以利用plot()函数画图
# kind='bar'意思为画出柱状图
df.Survived.value_counts().plot(kind='bar')输出:

当然 value_counts ()这个函数还可以读取其他属性的值,我们来看下不同舱位的人分别有多少吧
# 当然我们也可以查看,所有成员的Pclass等级
# 一等舱 216人,二等舱 184人,三等舱 491人
df.Pclass.value_counts()输出:
3 491
1 216
2 184
Name: Pclass, dtype: int64之前用 isnull() 读取空值的时候,会发现结果显示,Cabin这个属性竟然有多达687个空值,意味着有687个成员并没有Cabin这个属性,那么这个属性的价值相比其他属性就相对来说小多了。所以我们可以利用 drop() 这个函数来删除这个属性。
# 之前我们发现 Cabin这个属性存在空值太多
# 所以我们想把这个属性删除
# 利用drop()函数,可以将一列的属性全部删除
df1=df.drop('Cabin',axis=1)然后我们简单查看一下前五行

会发现Cabin这个属性已经没有了
重新观察一下之前输出的 isnull()函数,会发现,Age这个属性,存在177个空值。
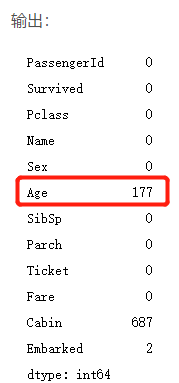
意味着这个文件里并没有将所有成员的年龄记录上,有177个成员并没有Age这个属性。
当然我们可以给它补上。
# fillna()函数意思为,若本来的属性为空值
# 则给空值赋值为20
df1['Age']=df1['Age'].fillna(20)此时再次利用 isnull()查看文件存在多少空值
# 查看此时属性空值的数量
df1.isnull().sum()输出:
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Embarked 2 dtype: int64
现在就只剩下Embarked这个属性还存在2个空值了。我们可以将这两个带有空值的成员也直接删除。注意,此处是把带有Embarked这个属性并且属性为空值的成员给删除了。
# 处理 Embarked里面的两个空值,将非空值重新赋给 df2
df2=df1[df1['Embarked'].notnull()]
df2.isnull().sum()输出:
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Embarked 0 dtype: int64
为了确定现在的成员数,我们再看下shape的结果。

我们可以把刚才几个步骤合在一起写,相对来说看起来会复杂一点
df3=df.drop('Cabin',axis=1).assign(Age=lambda x:x['Age'].fillna(20))
df3=df3.loc[df3['Embarked'].notnull()]
df3.isnull().sum()此时df3和df2是一样的,所以输出结果和刚才也是一样的
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Embarked 0 dtype: int64
刚才我们是对特定的某一个属性进行查看的,我们也可以对多个属性一起看
# 选择特定的行和列的属性进行查看
df1.loc[10:14,['Name','Sex','Survived']]输出:

读取df3的所有的属性名称方法和之前也一样,利用 columns()来查看
# 列出df3所有的属性
df3.columns输出:
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Embarked'],
dtype='object')
那么具体分析男女存活的人数,我们可以利用 pivot_table() 来建立表格
# 建立单独的表格去描述
df3.pivot_table(values='PassengerId',index='Survived',columns='Sex',aggfunc='count')
通过这个表格我们可以看出,女性活下来231人,死去81人。相对男性存活率高多了。证明当时船上还是有很多令人敬佩的绅士的。
那么继续分析活下来的人,选取Survived里面值为1的成员,命名为df4
# 利用loc()来计数活着的人有多少
df4=df3.loc[df3['Survived']==1]
df4.shape输出:

经过上述练习,我们基本完成了对该数据的一个非常简易的分析。还有一些操作可供大家练习~
df['Pclass'].value_counts().plot.bar()输出:

最后简单提一下corr()函数,判断两个属性是否具有相关性
# corr()——皮尔森相关
# 判断两个属性的相关性有多少
# 如果返回值越接近1,代表正相关
# 如果返回值越接近-1,代表负相关
df['Survived'].corr(df['Pclass'])输出:
-0.3384810359610148
可以看出,舱位的高低和存活率的关系。
-0.338是负数,证明是负相关,也就是说,舱位越高(也就是舱的档次越低),死亡概率也大
好了,终于完成了第一个实例的分析~
下一节将会继续介绍pandas的进阶操作~谢谢