爬虫实战(2)--爬取网易云音乐,做一个自己的音乐播放器(上)
爬虫实战(2)--网易云音乐爬取
- 前言
- 环境
- 爬取歌曲列表
前言
经过上一篇爬取学校官网之后,觉得不过瘾,开始动起了网易云音乐的注意,为了更好的入门爬虫,于是开始了我的小项目,做一个播放器,大概是这样子的:
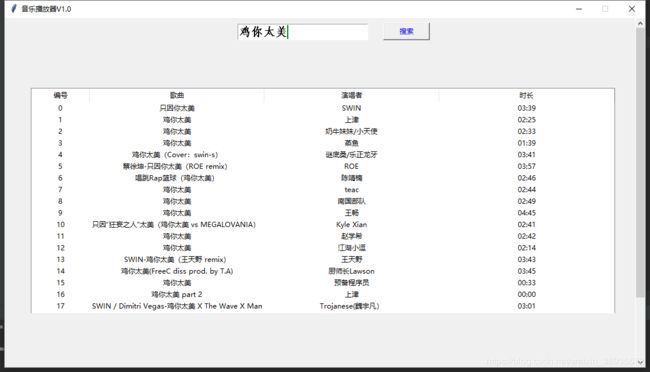
界面比较简陋,不过有 搜索 功能和 播放 功能,用户双击歌曲就可以播放,这个功能还不够完善,但是满足了我的预想,如果各位观众姥爷有兴趣,可以继续完善。
环境
使用语言:python3.6
开发工具:PyChram
第三方库:
- requests (强大的爬虫库)
- BeautifulSoup (用于处理爬取的网页信息)
- PIL (图象处理,本项目用于显示验证码图片)
- pygame(用来播放音乐)
- tkinter(可视化编程)
- selenium(网页调试工具,反爬虫人员的噩梦)
- 下载方法
pip install ***
爬取歌曲列表
首先,浏览网易云音乐官网,随便搜索一首歌

我们看到上面的网址,格式为:
https://music.163.com/#/search/m/?s=歌曲名称&type=1
我们发现参数有两个:
s :歌曲名称
type :选项卡的位置,不写默认为第一个,也就是单曲的位置
可以自己尝试一下,s 参数后面加歌手名或者歌曲名,都可以出想要的结果
于是,搜索这部分的代码不难写,我们尝试直接抓取这个页面:
import requests
rs = requests.session()
find_music_url = 'https://music.163.com/#/search/m/?s='+your_music+'&type=1'
html = rs.get(find_music_url)
print(html.text)
我们用常规工具 requests 尝试抓取,发现网页内容确实是被抓取下来,但是怎么都找不到歌单内容
于是,分析一下发现,歌单的位置处在一个叫 iframe 的标签里面
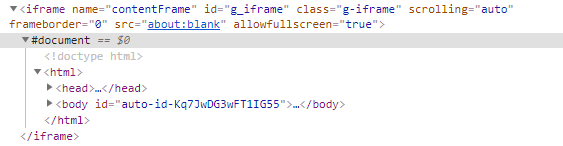
到这里我们知道,他的网页内容是通过 js 加载的,单纯的用 requests库并不能抓取内容,这里提供两个思路:
第一个:
使用之前提到的 selenium(网页调试工具,反爬虫人员的噩梦)库
简单的说,他是模拟人操作浏览器,可以实现各种人为的操作浏览器,包括鼠标点击等
我们可以在js加载结束后,抓取页面内容
第二个:
分析js代码,然后用python实现或者用python调用它,达到我们向服务器发送相对应的参数的目的
抓取json,获取歌单内容
这里我采用的是第一个办法,比较简单快捷,之后的歌曲播放连接采用的是第二个办法,如果想知道过程可以直接阅读后面部分。
使用 selenium 十分简单,代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
driver = None
# 启动浏览器
def open_chrome():
# 调试器配置
chrome_options = Options()
chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
chrome_options.add_argument('--headless') # 浏览器不提供可视化页面.
# 申明是谷歌浏览器
global driver
driver = webdriver.Chrome(chrome_options=chrome_options)
# 查找音乐
def find_music(your_music):
# 访问地址
find_music_url = 'https://music.163.com/#/search/m/?s='+your_music+'&type=1'
driver.get(find_music_url)
driver.switch_to.frame('g_iframe') # 进入iframe
find_music_html = driver.execute_script("return document.documentElement.outerHTML")
# print(html)
# 规范化输出
soup = BeautifulSoup(find_music_html, 'lxml')
# 查找的类名
attrs = {
'class': 'item',
'class': 'f-cb',
'class': 'h-flag'
}
# 查找类名为attrs的内容
find_music1 = soup.findAll(name="div", attrs=attrs)
# 查找后的音乐列表
find_ok_music = []
'''
对部分用 BeautifulSoup做规范化输出,就交由大家自己处理
find_music1 以及是抓取后的歌单内容
我的格式为下面所示
# 查找内容存放
find_my_music = {
'a': a['href'], # 歌曲链接
'b': b[0]['title'], # 歌曲名称
'c': c, # 演唱者
'time': music_time # 歌曲时间
}
'''
return find_ok_music
# 关闭浏览器
def close_chrome():
driver.close() # 关闭浏览器,回收资源
这部分代码的注释还是蛮多的,我相信观众姥爷们很容易就可以看懂。
各部分的功能都做成函数,方便后面调用。
值得注意的一点是,如果你没有下载 chromedriver.exe 编译器会报这个错误
selenium.common.exceptions.WebDriverException:
Message: 'chromedriver' executable needs to be in PATH.
Please see https://sites.google.com/a/chromium.org/chromedriver/home
意思是缺少 chromedriver.exe ,需要到
http://chromedriver.storage.googleapis.com/index.html
下载适合的版本,然后将下载完的压缩包解压,将 chromedriver.exe 文件放在你的python脚本下即可。
注意:我用的是谷歌浏览器,在地址栏输入以下网址可以查看自己浏览器的版本。
chrome://version/
至此,查找功能就完成啦,还是比较简单的,有什么问题可以留言提问哦。
播放功能请看下一篇,祝大家敲码愉快哦~