python3爬虫实战之selenium爬取亚马逊商品
环境
- python3.6
- PyCharm
- 科学上网环境
主要内容
1. 思路
先说一下爬取的思路,用selenium打开关键词的搜索页,然后分析搜索页下的商品链接,再用selenium打开商品页,最后返回商品数据即可。
2. 导入模块
from datetime import date
import requests
import time
import re
from PIL import Image
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
import openpyxl
from selenium import webdriver
from selenium.common.exceptions import UnexpectedAlertPresentException
from selenium.webdriver import DesiredCapabilities
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
3. 主要代码
上代码之前有几个需要注意的地方
- 开启科学上网后爬取亚马逊速度会快
- 亚马逊会根据科学上网的地址设置为收货地址
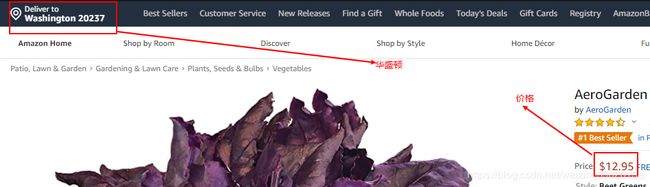
- 有的收货地址商品页会不显示价格,比如下面这个商品

3.1 更换地址
def change_address(postal):
while True:
try:
driver.find_element_by_id('glow-ingress-line1').click()
# driver.find_element_by_id('nav-global-location-slot').click()
time.sleep(2)
except Exception as e:
driver.refresh()
time.sleep(10)
continue
try:
driver.find_element_by_id("GLUXChangePostalCodeLink").click()
time.sleep(2)
except:
pass
try:
driver.find_element_by_id('GLUXZipUpdateInput').send_keys(postal)
time.sleep(1)
break
except Exception as NoSuchElementException:
try:
driver.find_element_by_id('GLUXZipUpdateInput_0').send_keys(postal.split('-')[0])
time.sleep(1)
driver.find_element_by_id('GLUXZipUpdateInput_1').send_keys(postal.split('-')[1])
time.sleep(1)
break
except Exception as NoSuchElementException:
driver.refresh()
time.sleep(10)
continue
print("重新选择地址")
driver.find_element_by_id('GLUXZipUpdate').click()
time.sleep(1)
driver.refresh()
time.sleep(3)
postal:邮编地址,比如美国华盛顿邮编20237
3.2 解析搜索页
def parse_list(page_source, current_url):
html = pq(page_source)
url_front = current_url.split("/s")[0]
item_urls = html("h2 > a.a-link-normal.a-text-normal").items()
for s in item_urls:
url = url_front + s.attr("href")
yield url
page_source:网页源代码current_url:搜索页的网址,做拼接使用
3.3 解析商品详情页
def parse_detail(page_source):
html = pq(page_source)
attr_list = []
# 商品标题
title = html("span#productTitle").text()
# 详细描述
li_list = html("ul.a-unordered-list.a-vertical.a-spacing-none li").items()
li_text_list = []
for li in li_list:
li_text_list.append(li.text().strip())
# 主图
z_img = html("img#landingImage").attr("data-old-hires")
if z_img == "":
z_img = html("img#landingImage").attr("src")
# 价格
price = html('span[id*="priceblock"]').text().replace('\xa0', '')
# 评论数
review_num = ""
review_num_list = html("#acrCustomerReviewText").items()
for rn in review_num_list:
review_num = rn.text()
break
if review_num != "":
review_num = review_num.split(" ")[0]
# 排名
rank1 = ""
rank2 = ""
tr_list = html("#productDetails_detailBullets_sections1 tr").items()
for tr in tr_list:
if "Rank" in tr("th").text():
rank1 = tr("td > span > span:nth-child(1)").text().strip()
rank2 = tr("td > span > span:nth-child(3)").text().strip()
break
if rank1 == "":
first_rank = html("#SalesRank")
if first_rank("b"):
rank2 = html("#SalesRank > ul").text().replace("\xa0", "")
first_rank.remove("b")
first_rank.remove("ul.zg_hrsr")
first_rank.remove("style")
rank1 = first_rank.text()
else:
first_rank = html("div.attrG tr#SalesRank > td.value")
rank2 = html("div.attrG tr#SalesRank > td.value ul.zg_hrsr").text().replace("\xa0", "")
first_rank.remove("ul.zg_hrsr")
first_rank.remove("style")
rank1 = first_rank.text()
if rank1 == "":
b_html = BeautifulSoup(page_source, 'lxml')
tr_list = b_html.select("#productDetails_detailBullets_sections1 tr")
for tr in tr_list:
if 'Rank' in tr.th.text:
rank1_list = tr.select("td > span > span:nth-child(1)")
if rank1_list:
rank1 = rank1_list[0].text.strip()
rank2_list = tr.select("td > span > span:nth-child(3)")
if rank2_list:
rank2 = rank2_list[0].text.strip()
rank_regex = re.compile("\d(.*?)\s")
if rank1 != "":
rank1 = rank_regex.search(rank1).group()
if rank2 != "":
rank2 = rank_regex.search(rank2).group()
score = html("span[data-hook=rating-out-of-text]").text()
if score == "":
try:
score = list(html("#acrPopover > span.a-declarative > a span").items())[0].text()
except Exception as e:
score = ""
if score != "":
score = score.split(" ")[0].replace(",", ".")
asin = ''
attr_list.append(asin)
attr_list.append(z_img)
attr_list.append(title)
attr_list.append(price)
attr_list.append(score)
attr_list.append(int(review_num.strip().replace(',', '')) if review_num else 0)
attr_list.append(int(rank1.strip().replace(',', '')) if rank1 else 0)
attr_list.append(rank2)
return attr_list
page_source:网页源代码- 返回商品asin、主图地址、标题、价格、评分、评论人数、大类排名、小类排名
3.4 调用方法
if __name__ == '__main__':
options = webdriver.ChromeOptions()
options.add_argument('--disable-gpu')
options.add_argument("disable-web-security")
options.add_argument('disable-infobars')
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(chrome_options=options)
wait = WebDriverWait(driver, 20)
Action = ActionChains(driver)
driver.maximize_window()
row = 2
search_page_url = 'https://www.amazon.com/s?k=basketball+hoop&crid=1FVAKJZW1GRRW&sprefix=bas%2Caps%2C405&ref=nb_sb_ss_i_1_3&page={}'
postal = "20237"
for i in range(1, 2):
print("正在爬取", search_page_url.format(i))
driver.get(search_page_url.format(i))
time.sleep(2)
if i == 1:
change_address(postal)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div.s-result-list")))
for url in parse_list(driver.page_source, search_page_url.format(i)):
js = 'window.open("' + url + '&language=en_US");'
driver.execute_script(js)
# 网页窗口句柄集
handles = driver.window_handles
# 进行网页窗口切换
driver.switch_to.window(handles[-1])
page_source = driver.page_source
info_list = parse_detail(driver.page_source)
info_list.append(driver.current_url)
time.sleep(2)
asin_regex = re.compile('/dp/(.*?)/')
asin = asin_regex.findall(driver.current_url)[0]
info_list[0] = asin
print(info_list)
driver.close()
driver.switch_to.window(handles[0])
print("爬取结束")
运行结果:
