使用python下载网站漫画
最近想回顾一下七龙珠,结果发现腾讯已经收费,而且是按节收费,无奈看看其他网站,找到了一个网站,可以在线看,但是无法下载,最后决定使用python下载下来
首先要分析网站源码,查看源代码
![]()
1~42部的URL是从
http://comic.kukudm.com/comiclist/141/1343/到
http://comic.kukudm.com/comiclist/141/1384/
而每一页的URL是从1.htm到xx.htm
得到每部的网址后,下一步就是看图片的URL
rsp = req.get(url, timeout = 2)
rsp.encoding = 'utf-8'
print rsp.text打印出来的漫画图片源码如下:
document.write(" ");
");
可以看出网站源码并不直接图片的源地址,而是需要通过浏览器编译运行才能图片的真实地址,通过F12调试浏览器,得出源地址如下:
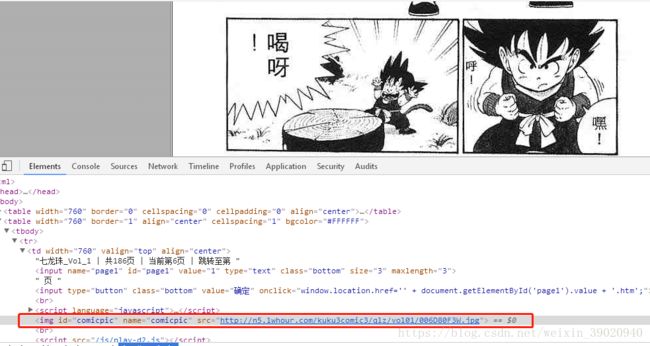
多找几个,可以得出漫画的真实网址是http://n5.1whour.com/加对应网页源码的后缀拼接出来的,代码可以这么写
image_pre_url = "http://n5.1whour.com/"
# url http://comic2.kukudm.com/comiclist/141/1343/1.htm
# filename 001.jpg
@retry(stop_max_attempt_number=3, stop_max_delay=10000)
def downloadImg(url, filename):
print url
rsp = req.get(url, timeout = 2)
rsp.encoding = 'utf-8'
image_posturl = re.findall("kuku3comic3.*.jpg", rsp.text)
image_url = image_pre_url + str(image_posturl[0])这里面的retry是引用了python的retrying模块,可以通过注释的模式设置函数内部重试,还可以设置最大时长
找到了章节网址和每个图片的网址,剩下就是下载了,代码如下
r = req.get(image_url, stream=True, timeout = 2)
with open(filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
f.close()
print 'download finished',image_url至此,就可以完成漫画下载