3000 字详解 Kylin 查询缓存重构
在过去,由于粗粒度缓存过期策略和外部缓存的缺乏,查询缓存在 Kylin 中的使用效率不高。由于激进的缓存过期策略,有用的缓存经常被不必要地清理。因为查询缓存存储在本地服务器中,它们因而不能在服务器之间共享。同时,由于本地缓存的大小限制,并不是所有有用的查询结果都可以被缓存。
针对这些不足,我们使用签名检查来实现新的查询缓存失效策略,并引入 memcached 作为 Kylin 的分布式缓存,使 Kylin 服务器能够在服务器之间共享缓存。同时添加 memcached 服务器来扩展分布式缓存也是很容易的。
这些功能由 eBay Kylin 团队提出和开发,在此非常感谢他们的贡献。
相关的 JIRA
- KYLIN-2895 Refine Query Cache: https://issues.apache.org/jira/browse/KYLIN-2895
- KYLIN-2899 Introduce segment level query cache:https://issues.apache.org/jira/browse/KYLIN-2899
- KYLIN-2898 Introduce memcached as a distributed cache for queries:https://issues.apache.org/jira/browse/KYLIN-2898
- KYLIN-2894 Change the query cache expiration strategy by signature checking:https://issues.apache.org/jira/browse/KYLIN-2894
- KYLIN-2897 Improve the query execution for a set of duplicate queries in a short period:https://issues.apache.org/jira/browse/KYLIN-2897
- KYLIN-2896 Refine query exception cache:https://issues.apache.org/jira/browse/KYLIN-2896
深度剖析
引入 memcached 作为分布式查询缓存
memcached 是一种自由开放的开源、高性能、分布式内存对象缓存系统。它适用于数据库调用、API 调用或页面渲染等场景,可以用于任意数据(字符串、对象)的内存内键值存储。它简单而有效。它的简单设计便于快速部署,并令其易于开发,并解决了面临大数据缓存的许多问题。它的 API 适用于大多数流行语言。
通过 Kylin-2898,Kylin 使用 memcached 作为分布式缓存服务,并使用EHCache作为本地缓存服务。当在 applicationcontext.xml中配置 RemotelocalFailOvercacheManager 时,对于每个缓存 PUT/GET 操作,Kylin 将首先检查分布式缓存服务是否可用,只有当分布式缓存服务不可用时,才会使用本地缓存服务。
首先,多个查询服务器可以共享查询缓存。对于每个 Kylin 服务器而言,更少的 JVM 内存会被占用,这有助于降低 GC 压力。其次,由于 memcached 是集中式的,所以在多个 Kylin 进程中将避免重复的缓存条目。第三, memcached 具有较大的尺寸和易于扩展的特性,这将有助于减少由于内存容量有限而导致的不得不丢弃掉有用缓存条目的可能性。
为了处理节点故障和扩展 memcached 集群,作者引入了一种一致性散列策略以顺利解决这类问题。Ketama 实现了一致的散列算法,这意味着您可以从 memcached 池中添加或删除服务器,而不需要对所有键进行完全重新映射。详细信息可以在 Ketama consistent hash strategy (https://www.last.fm/user/RJ/journal/2007/04/10/rz_libketama_-_a_consistent_hashing_algo_for_memcache_clients) 中查阅。
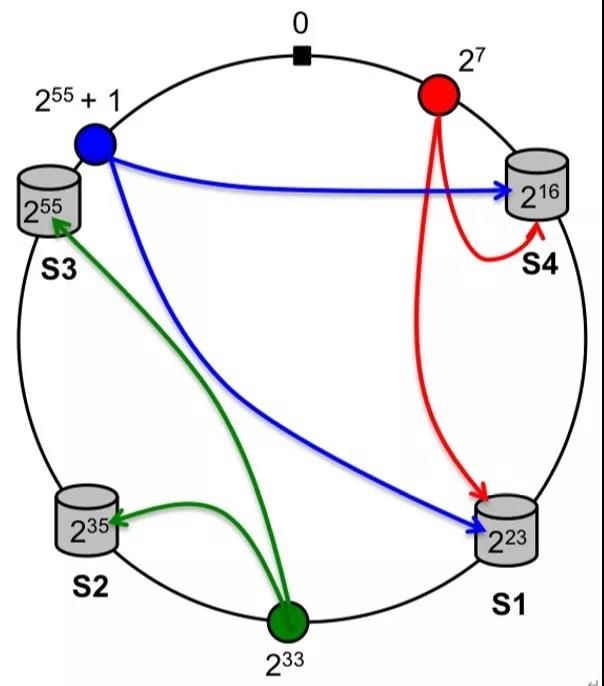
Segment 级别缓存
当前,Kylin 使用 SQL 作为缓存键,当 Kylin 收到查询请求时,如果缓存中存在结果,它将直接返回缓存的结果,且不需要查询 HBASE。当有新的片段生成或现有片段刷新时,所有相关的缓存结果都需被清除。对于一些经常被建构的 Cube,如流式 Cube (NRT Streaming 或 Real-time OLAP),缓存未击中的情况会急剧增加,这可能会降低查询性能。
对于 Kylin cube 而言,大多数历史 Segment 是不可更改的除非 segment 被更新,对历史 Segment 的相同查询出来的结果应该始终相同,所以历史 Segment 的缓存也不应该被清除。为此,我们决定实现 Segment 级别缓存,它是现有前端缓存的一个补充,其思路与操作系统中的 Level1/Level2 缓存相似。
基于签名检查的缓存失效策略
当前,对于无效的查询缓存, CacheService 将调用cleanDataCache 或 cleanAllDataCache。这两种方法都将清除所有查询缓存,这非常低效且不必要。在生产环境中,每天有数百个 Cubing 作业,这意味着查询缓存将被每几分钟全部清除一次。我们接着介绍了一种新的基于签名检查的查询缓存失效策略。
基本思路如下:
将 SQLResponse(也就是查询结果)放入缓存时,我们为每个 SQLResponse 计算签名。要计算 SQLResponse 的签名,我们选择 Cube 最后一次构建发生的时间及其 Segment 作为 SignatureCalculator 的输入。
当从缓存获取 SQL 对应的 SQLResponse 时,首先检查签名是否一致。如果不一致,则此缓存值已过期并将被删除。
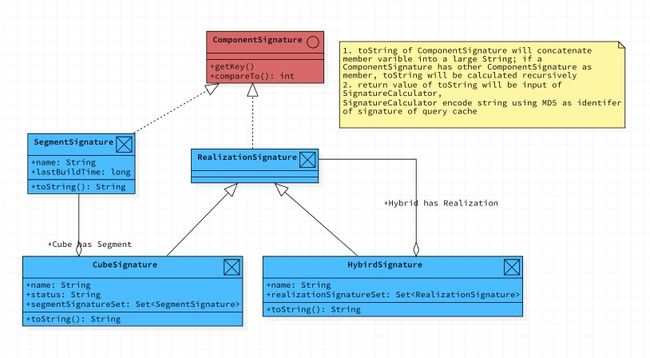
关于签名的计算,如下所示:
1. ComponentSignature 的 toString 将把成员变量连接到字符串中;如果 ComponentSignature具有其他 ComponentSignature作为成员,则将递归地计算 toString。
2. toString的返回值将输入 SignatureCalculator,SignatureCalculator 将经过MD5编码后的字符串作为查询缓存签名的标识符。
其他增强
短时间内重复查询的优化
如果不同的客户端同时向 Kylin 发送相同的请求, 在首条查询结果返回前,对于任一查询而言,就不能找到他们的查询缓存,因此必须分别计算它们。更糟糕的是,如果这些查询很复杂,它们通常会花费很长的时间,这样 Kylin 能利用缓存查询的机会就会更少;同时也会耗费大量的计算资源,使得查询服务器性能变差并对 Hbase 集群造成损害
为了减少重复的复杂查询的影响,我们可以阻塞随后出现的查询,等到首个查询获取到结果再统一返回。如果同时出现重复的复杂查询,此延迟策略会尤其有用。要使其生效,您应该将 kylin.query.lazy-query-enabled 设置为 true。另外,您也可以选择将kylin.query.lazy-query-waiting-timeout-milliseconds 设置为您认为后来的重复查询需要的等待时间,以匹配您的场景。
删除异常缓存
过去,查询缓存被分为两部分,一部分用于存储成功的查询结果,另一部分用于储存失败的查询结果,它们会分别失效。这看起来不是一个很好的分类标准,因为它不够细粒度。在引入查询缓存签名后,我们没有理由将它们分开,因此删除了异常缓存。
如何使用
为了做好准备,您需要安装 memcached,可以参考 https://github.com/memcached/memcached/wiki/Install. 接着您需要修改kylin.properties 和 applicationContext.xml.
kylin.properties
kylin.cache.memcached.hosts=10.1.2.42:11211kylin.query.cache-signature-enabled=truekylin.query.lazy-query-enabled=truekylin.metrics.memcached.enabled=truekylin.query.segment-cache-enabled=true
applicationContext.xml
p:configLocation="classpath:ehcache-test.xml" p:shared="true"/>p:cacheManager-ref="ehcache"/>
查询缓存配置
常规部分
| 配置键 | 配置值 | 说明 |
kylin.query.cache-enabled |
boolean,默认值为真 |
是否启用查询缓存 |
kylin.query.cache-threshold-duration |
long, 以毫秒为单位,默认值为2000 |
需要被缓存的查询的查询时间阈值 |
kylin.query.cache-threshold-scan-count |
long,默认值为10240 |
需要被缓存的查询的扫描行计数阈值 |
kylin.query.cache-threshold-scan-bytes |
long,默认值为1024 * 1024 (1MB) |
需要被缓存的查询的查询扫描字节阈值 |
Memcached部分
| 配置键 | 配置值 | 说明 |
| kylin.cache.memcached.hosts | 主机1:端口1,主机2:端口2 | memcached主机的主机列表 |
| kylin.query.segment-cache-enabled | 默认值 false | 是否启用Segment级别缓存 |
| kylin.query.segment-cache-timeout | 默认值2000 | memcached超时阈值 |
| kylin.query.segment-cache-max-size | 200 (MB) | 置入memcached的最大字节 |
缓存签名部分
| 配置键 | 配置值 | 说明 |
| kylin.query.cache-signature-enabled | 默认值 false | 是否对查询缓存使用签名 |
| kylin.query.signature-class | 默认值是org.apache.kylin.rest.signature.FactTableRealizationSetCalculator | 使用哪个类计算查询缓存的签名 |
其他优化部分
| 配置键 | 配置值 | 说明 |
| kylin.query.lazy-query-enabled | 默认值 false | 是否阻止重复的SQL查询 |
| kylin.query.lazy-query-waiting-timeout-milliseconds | long, 以毫秒为单位,默认值是60000 | 阻止重复SQL查询的最长时段 |