Python爬取京东回力鞋购买情况看看码数比例
背景
突然想起前阵子看到一篇爬bar并统计女生罩杯情况的文章,心想。我擦,这么好的题材让别人先写了我风暴哭泣。心想,算了,人家本来就比我优秀。然后随便去京东逛了逛。看到回力旗舰店给我推了,那我也来搞搞吧。
一、思路
爬虫,其实目的就是把网站上想要的数据盘下来。过程很简单,所有人都可以手动完成:进去网站,拿掉数据,保存下来。只不过当我们想要反复的进行这些操作,就不愿意了而已,所以要借助计算机的力量。因此,实现的大体思路:观察->发起请求->服务器反馈数据->找到数据->获取数据
虽说爬虫大体的思路很简单,但是找数据,获取数据的过程可不是那么简单的欸。重要的一点是观察,而且很多网站都有反爬的机制,因此在爬虫过程中的思路千变万化,只能结合事实来做改变。
二、实现
1.观察
在进行代码编写前,必定要先对网站进行观察。首先观察想要的数据在哪?数据是静态的还是动态的?如果是静态数据,经常使用BeautifulSoup库对数据进行标签过滤爬取,如果是动态,我们就找出动态数据的url在哪,再作进一步打算。
我爬的网页是https://item.jd.com/5480090.html#comment ,目标是评论以及购买的码数,颜色。
第一,定位数据位置。
定位好数据之后观察数据是静态还是动态。在我翻到评论的下一页时,整个页面并没有改变,只是局部的数据在发生变化。因此我猜测很有可能是通过js获取动态数据的。紧接着点开网络分析。

果然有发现,打开看看!

是它是它就是它!
于是乎打开了几个url看看。
![]()
看到了吧!翻页的规律又发现了咯。
2.发起请求,求反馈信息
观察完之后就可以开始编写代码了:
先写一个:
import requests
htmlshow = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=5480090&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1').text
print(htmlshow)
好了,请求回来的数据包含了我们想要的数据。
3.获取数据:
import requests
import json
htmlshow = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=5480090&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1').text
# print(htmlshow)
data = json.loads(htmlshow[20:-2]) #页面上的数据看起来跟json十分相似,因此,将数据转换成json再筛选我们所需要的数据
for i in range(len(data['comments'])):
print('颜色:'+data['comments'][i]['productColor']+' \n码数:'+data['comments'][i]['productSize']+' \n评论:'+data['comments'][i]['content'])
print(f"---------------------第{i+1}条-----------------------------")
效果:

4.继续获取更多数据并存入数据库
上面只是获取了一个页面的数据,我们的目标岂能如此之小?继续盘!
import requests
import json
import pymysql
connn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='123',
port=3306,
db='huilipa',
charset='utf8',
)
cur = connn.cursor()
num = 0
for i in range(0,500):
url1 = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=5480090&score=0&sortType=5&page='
url2 = str(i)
url3 = '&pageSize=10&isShadowSku=0&rid=0&fold=1'
htmlshow = requests.get(url1+url2+url3).text
data = json.loads(htmlshow[20:-2])
for j in range(len(data['comments'])):
num = num+1
yanse = data['comments'][j]['productColor']
mashu = data['comments'][j]['productSize']
pinglun = data['comments'][j]['content']
cur.execute("insert into huilidata(yanse,mashu,pinglun) value (%s,%s,%s)",(yanse,mashu,pinglun))
connn.commit()
print(f'颜色:{yanse}\n码数:{mashu}\n评论:{pinglun}')
print(f'---------------{num}条-------------------------------------')
看到评论数量有6w多,所以我打算爬5千条的,结果跑到1千就停止了,一开始以为出了什么问题,后来一看评论只显示了100页。。。
效果:

一共爬了一千条数据,并且存进mysql里面。
5.做个小分析吧
就是看看1000个人里面34-44码数的人各有多少个,大概的估算出比例。大家不要笑这个方法哈哈哈,这是最简单粗暴的计算方式,本来想写的简单一点的,但是写之前家人说准备吃饭了,然后就快速写一个吧!!
import pymysql
connn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='123',
port=3306,
db='huilipa',
charset='utf8',
)
mashu34 = 0
mashu35 = 0
mashu36 = 0
mashu37 = 0
mashu38 = 0
mashu39 = 0
mashu40 = 0
mashu41 = 0
mashu42 = 0
mashu43 = 0
mashu44 = 0
cur = connn.cursor()
cur.execute("select mashu from huilidata ;")
for i in cur.fetchall():
for j in i :
k =range(34,45)
if str(k[0]) in j:
mashu34 = mashu34 + 1
if str(k[1]) in j:
mashu35 = mashu35 + 1
if str(k[2]) in j:
mashu36 = mashu36 + 1
if str(k[3]) in j:
mashu37 = mashu37 + 1
if str(k[4]) in j:
mashu38 = mashu38 + 1
if str(k[5]) in j:
mashu39 = mashu39 + 1
if str(k[6]) in j:
mashu40 = mashu40 + 1
if str(k[7]) in j:
mashu41 = mashu41 + 1
if str(k[8]) in j:
mashu42 = mashu42 + 1
if str(k[9]) in j:
mashu43 = mashu43 + 1
if str(k[10]) in j:
mashu44 = mashu44 + 1
print(f"34码的人数:{mashu34}")
print(f"35码的人数:{mashu35}")
print(f"36码的人数:{mashu36}")
print(f"37码的人数:{mashu37}")
print(f"38码的人数:{mashu38}")
print(f"39码的人数:{mashu39}")
print(f"40码的人数:{mashu40}")
print(f"41码的人数:{mashu41}")
print(f"42码的人数:{mashu42}")
print(f"43码的人数:{mashu43}")
print(f"44码的人数:{mashu44}")
print(f"总人数:{mashu34+mashu35+mashu36+mashu37+mashu38+mashu39+mashu40+mashu41+mashu42+mashu43+mashu44}")
结果:
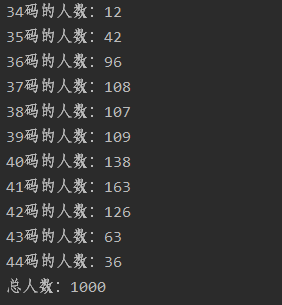
比例应该一眼就看出来了吧,34-44分别是1.2%、4.2%、9.6%、10.8%、10.7%、10.9%、13.8%、16.3%、12.6%、6.3%、3.6%
(小声bb:我也是给41上票的一个人哈哈)
结束
Python爬取京东回力鞋购买情况并做简单的数据分析到此就结束啦,本篇文的程序还是极为简单的哈。总之爬虫的思路千变万化,要看爬取数据的网站情况,并且这里提醒一下大家,不要去触碰到法律了哈。不然真应了那句:爬虫写的好,坐牢坐到老。