HBase系统简介
网上看到一篇HBase原理分享的文章,解决了很多疑惑,很赞,原文连接:https://www.jianshu.com/p/20aff7d85e95,在此转载记录。
点击原文链接查看更清晰!!!!
一、HBase简介
Hbase是什么
HBase是一种构建在HDFS之上的分布式、面向列、多版本、非关系型的数据库。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。HBase 是Google Bigtable 的开源实现。
HBase的特点
大:一个表可以有上亿行,上百万列。
面向列:面向列(组)的存储和权限控制,列(组)独立检索。
稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型,存储在hbase上的都是字节数组。
二、HBase数据模型
HBase 以表的形式存储数据。表由行和列组成。列划分为若干个列族(row family),如下图所示。
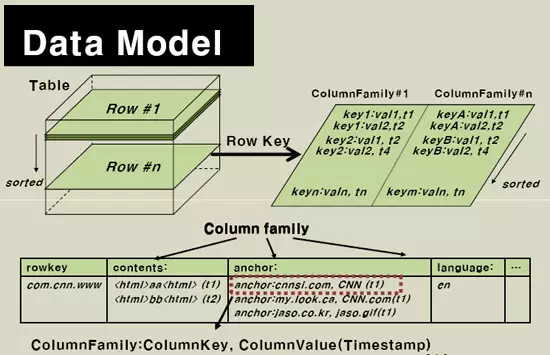
1) HBase的逻辑数据模型
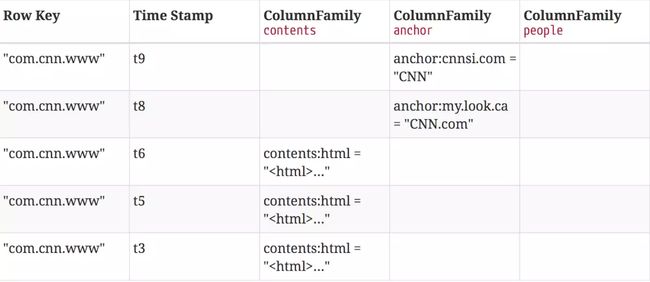
image.png
2) HBase的物理数据模型
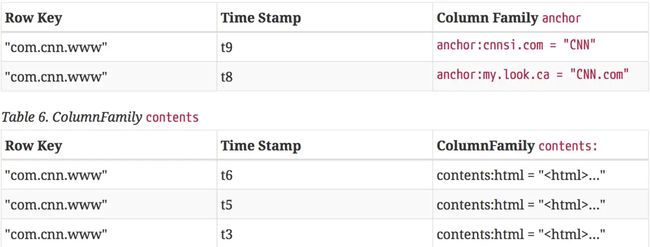
image.png
逻辑数据模型中空白cell在物理上是不存储的,因此若一个请求为要获取t8时间的contents:html,他的结果就是空。相似的,若请求为获取t9时间的anchor:my.look.ca,结果也是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回
-
Row Key
与 NoSQL 数据库一样,Row Key 是用来检索记录的主键。几种访问 HBase table 中的行方式:
1)通过单个 Row Key 访问。
2)通过 Row Key 的 range 全表扫描。
3)Row Key 可以使任意字符串(最大长度是64KB,实际应用中长度一般为 10 ~ 100bytes),在HBase 内部,Row Key 保存为字节数组。 -
列族
HBase 表中的每个列都归属于某个列族。列族是表的 Schema 的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀,例如 courses:history、courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。在实际应用中,列族上的控制权限能帮助我们管理不同类型的应用, 例如,允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、 一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。 -
Cell
时间戳HBase 中通过 Row 和 Columns 确定的一个存储单元称为 Cell。每个 Cell 都保存着同一份数据的多个版本。 版本通过时间戳来索引,时间戳的类型是 64 位整型。时间戳可以由HBase(在数据写入时自动)赋值, 此时时间戳是精确到毫秒的当前系统时间。时间戳也 可以由客户显示赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 Cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的管理(包括存储和索引)负担,HBase 提供了两种数据版本回收方式。 一是保存数据的最后 n 个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
3) HBase物理存储
Table 在行的方向上分割为多个HRegion,每个HRegion分散在不同的RegionServer中。

每个HRegion由多个Store构成,每个Store由一个memStore和0或多个StoreFile组成,每个Store保存一个Columns Family
三、HBase系统架构
1) HBase架构图

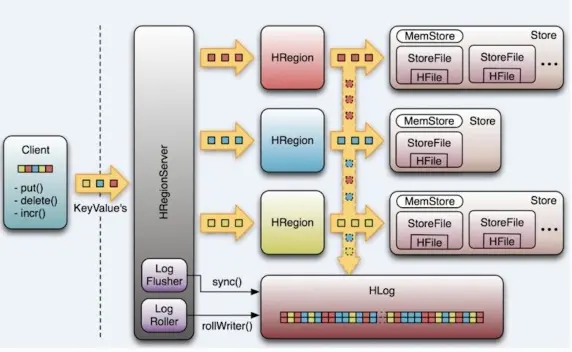
从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,接下来介绍他们的作用。
HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
-
Client
包含访问HBase的接口,并维护cache来加快对HBase的访问。 -
Zookeeper
HBase依赖Zookeeper,默认情况下HBase管理Zookeeper实例(启动或关闭Zookeeper),Master与RegionServers启动时会向Zookeeper注册。
保证任何时候,集群中只有一个master
实时监控Region server的上线和下线信息。并实时通知给master
存储HBase的schema和table元数据 -
HMaster
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region。
处理schema更新请求。 -
HRegionServer
维护master分配给他的region,处理对这些region的io请求。
负责切分正在运行过程中变的过大的region。
注意:client访问hbase上的数据时不需要master的参与,因为数据寻址访问zookeeper和region server,而数据读写访问region server。master仅仅维护table和region的元数据信息,而table的元数据信息保存在zookeeper上,因此master负载很低。 -
HRegion
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值时就会分成两个新的region。
每个region由以下信息标识:< 表名,startRowkey,创建时间>
由目录表(-ROOT-和.META.)记录该region的endRowkey -
Store
每一个region由一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个 ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者 多个StoreFile组成。 HBase以store的大小来判断是否需要切分region -
MemStore
memStore 是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认128MB)时,memStore会被flush到文 件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。 -
StoreFile
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。 -
HFile
HBase中KeyValue数据的存储格式,HFile是Hadoop的 二进制格式文件,实际上StoreFile就是对Hfile做了轻量级包装,即StoreFile底层就是HFile
HFile的存储格式如下: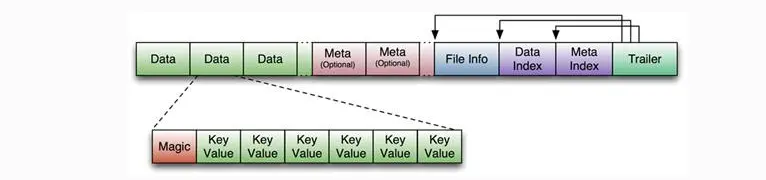
HFile由多个Data Block、Meta Block、FileInfo、Data Index、Meta Index、Trailer组成,其中Data Block是HBase的最小存储单元,在前文中提到的BlockCache就是基于Data Block的缓存的。一个Data Block由一个魔数和一系列的KeyValue(Cell)组成,魔数是一个随机的数字,用于表示这是一个Data Block类型,以快速监测这个Data Block的格式,防止数据的破坏。Data Block的大小可以在创建Column Family时设置(HColumnDescriptor.setBlockSize()),默认值是64KB,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。Meta块是可选的,FileInfo是固定长度的块,它纪录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index纪录了每个Data块和Meta块的其实点、未压缩时大小、Key(起始RowKey?)等。Trailer纪录了FileInfo、Data Index、Meta Index块的起始位置,Data Index和Meta Index索引的数量等。其中FileInfo和Trailer是固定长度的。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:
上图可知,开始是两个固定长度的数值,分别表示key的长度和alue的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有那么复杂的结构,就是纯粹的二进制数据。 -
HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的sequence number。 Sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue。
上图中是HLog文件的结构,其实HLog文件就是一个普通的Hadoop Sequence File,Sequence File的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和Region名字外,同时还包括sequence number和timestamp,timestamp是”写入时间”,sequence number 的起始值为0,或者是最近一次存入文件系统中的sequence number。
HLog Sequence File 的Value是HBase的KeyValue对象昂,即对应HFile中的KeyValue。
2) HRegion定位
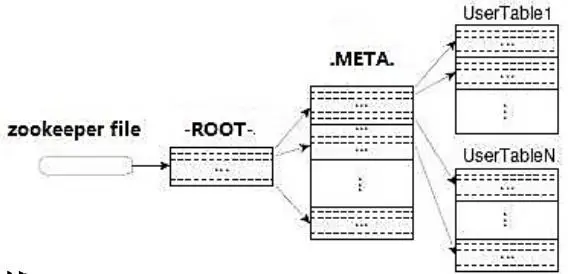
通过zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
通过-ROOT-表查找.META.表的第一个表中相应的region的位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个region 在-ROOT-表中都是一行记录。
通过.META.表找到所要的用户表region的位置。用户表中的每个region在.META.表中都是一行记录。
-ROOT-表永远不会被分隔为多个region,保证了最多需要三次跳转,就能定位到任意的region。client会将查询的位置 信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region,其中三次用来发现 缓存失效,另外三次用来获取位置信息。
提示:
-ROOT-表:表包含.META.表所在的region列表,该表只有一个Region;Zookeeper中记录了-ROOT-表的location
.META.表:表包含所有的用户空间region列表,以及Region Server的服务器地址
hbase:meta表:高版本中已经舍弃了ROOT和META表了,采用了这个表
四、HBase工作流程
HBase的流程图
-
Client
首先当一个请求产生时,HBase Client使用RPC(远程过程调用)机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写操作,Client与HRegionServer进行RPC。 -
Zookeeper
HBase Client使用RPC(远程过程调用)机制与HMaster和HRegionServer进行通信,但如何寻址呢?由于Zookeeper中存储了-ROOT-表的地址和HMaster的地址,所以需要先到Zookeeper上进行寻址。
HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点故障。 -
HMaster
当用户需要进行Table和Region的管理工作时,就需要和HMaster进行通信。HBase中可以启动多个HMaster,通过Zookeeper的Master Eletion机制保证总有一个Master运行。
管理用户对Table的增删改查操作
管理HRegionServer的负载均衡,调整Region的分布
在Region Split后,负责新Region的分配
在HRegionServer停机后,负责失效HRegionServer上的Regions迁移 -
HRegionServer
当用户需要对数据进行读写操作时,需要访问HRegionServer。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个 MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile, HFile就是实际的存储文件。因此,一个HRegion有多少个列族就有多少个Store。 一个HRegionServer会有多个HRegion和一个HLog。 -
注意:HStore存储由两部分组成:MemStore和StoreFiles。 MemStore是Sorted Memory Buffer,用户 写入数据首先 会放在MemStore,当MemStore满了以后会Flush成一个 StoreFile(实际存储在HDHS上的是HFile),当StoreFile文件数量增长到一定阀值,就会触发Compact合并操作,并将多个StoreFile合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的 读写操作*只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
五、HBase的高可用
- HDFS机架识别策略:当数据文件损坏时,会找相同机架上备份的数据文件,如果相同机架上的数据文件也损坏会找不同机架备份数据文件。
- HBase的Region快速恢复:当regionserver损坏时,master会对该regionserver上的region进行重新分配,迁移到其他可用的regionserver上并恢复region。
- Master节点的HA机制:Master为一主多备。当Master主节点宕机后,剩下的备节点通过选举,产生主节点。
六、HBase运维
- 时钟同步
- 手动majorcompact
- region hole修复
- region overlap修复
- 读写集群配置要区分
- memstore flush时机