利用Python爬取包图网图片和视频
目标:抓取包图网全站视频数据保存在本地,并以网站视频名命名视频文件。
网址:https://ibaotu.com/shipin/7-0-0-0-0-1.html
爬取第一步--检查 robots.txt
一般而言,大部分网站都会定义robots.txt 文件,该文件就是给 网络爬虫 了解爬取限制(一般建议遵守robots.txt 文件里面的限制)
如何查看这个 robots.txt 文件?
==在 目标网站站点域名 后面加上 robots.txt 即可。
https://ibaotu.com/shipin/7-0-0-0-0-1.html/robots.txt
我们进入网站,点击下一页:
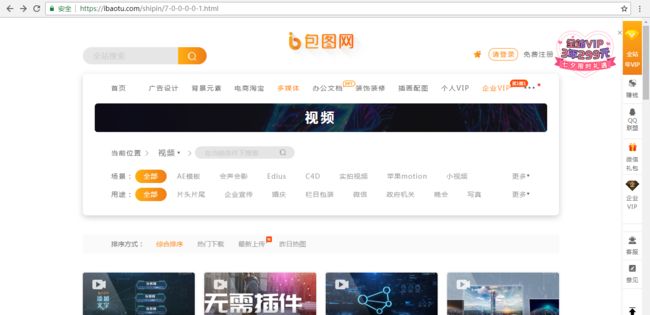
可以发现,网址变成了: https://ibaotu.com/shipin/7-0-0-0-0-2.html
所以,抓取一个网站的内容,我们需要从以下几方面入手:
1-如何抓取网站的下一页链接?
2-目标资源是静态还是动态(视频、图片等)
3-该网站的数据结构格式
所以,抓取一个网站的内容,我们需要从以下几方面入手:
1-如何抓取网站的下一页链接?
2-目标资源是静态还是动态(视频、图片等)
3-该网站的数据结构格式
原文链接:https://www.jianshu.com/p/227d53d4d77a
import requests
from lxml import etree
import threading
class Spider(object):
def __init__(self):
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"}
self.offset = 1
def start_work(self, url):
print("正在爬取第 %d 页......" % self.offset)
self.offset += 1
response = requests.get(url=url,headers=self.headers)
html = response.content.decode()
html = etree.HTML(html)
video_src = html.xpath('//div[@class="video-play"]/video/@src')
video_title = html.xpath('//span[@class="video-title"]/text()')
next_page = "http:" + html.xpath('//a[@class="next"]/@href')[0]
# 爬取完毕...
if next_page == "http:":
return
self.write_file(video_src, video_title)
self.start_work(next_page)
def write_file(self, video_src, video_title):
for src, title in zip(video_src, video_title):
response = requests.get("http:"+ src, headers=self.headers)
file_name = title + ".mp4"
file_name = "".join(file_name.split("/"))
print("正在抓取%s" % file_name)
with open(file_name, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
spider = Spider()
for i in range(0,3):
# spider.start_work(url="https://ibaotu.com/shipin/7-0-0-0-"+ str(i) +"-1.html")
t = threading.Thread(target=spider.start_work, args=("https://ibaotu.com/shipin/7-0-0-0-"+ str(i) +"-1.html",))
t.start()
代码导入以后,初步执行了一下,报了如下的错:
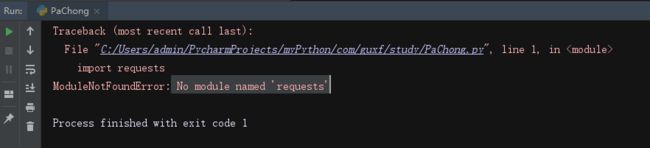
发现是缺少Python模块,类似就是缺少Java的Jar包的意思,所以解决方法如下:
找到python安装的目录,我的是E:/Python,由于是Windows系统,所以:
找到python安装的目录,我的是E:/Python,由于是Windows系统,所以:
①cmd
②cd E:/Python
③pip install requests
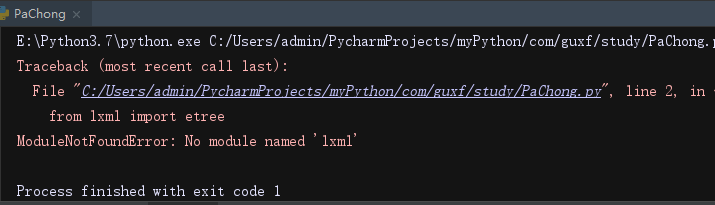
等待系统自动加载安装,安装好以后,又报了图2的错,所以再执行一次终端命令,把③改为pip install lxml,导入lxml。由于python 3.5之后的lxml模块里面不再包含etree,部分lxml模块不再支持etree方法,因此可能会报错如下:
![]()
这个报错亲试不影响代码执行,但是看着还是不舒服,故而解决办法如下,该行代码注释,换成3和4两行即可:
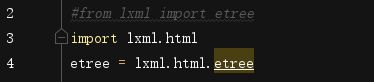
然后运行代码:
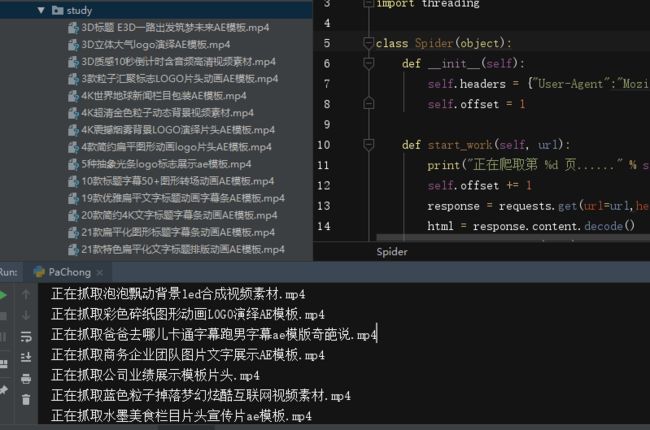
抓取成功!!!!