python---爬取英雄联盟皮肤图片
爬LOL的皮肤高清图片的大致步骤就是用selenium去爬取英雄联盟所以英雄的皮肤的url地址,然后在用requests库去将图片下载到本地。
爬取的第一步,先去分析网站。
皮肤图片的位置在官网的资料库,然后点击英雄进入英雄界面

这里就是皮肤的获取地了。
按F12然后定位到图片位置的代码

然后这里就有第一个坑:
一开始他不会显示所有皮肤的代码出来,你要点击其他的皮肤后它才会显示出全部的代码.
![]()
然后点进去看,里面就有我们需要的url代码,和图片的名称了。
![]()
代码:
def get_pic_url(mapath):
time.sleep(10)
namepath = '//ul[@id="skinNAV"]/li'
name_list = browser.find_elements_by_xpath(namepath)#小框
while len(name_list)<=1:
browser.refresh()
time.sleep(5)
name_list = browser.find_elements_by_xpath(namepath)
name_list[1].click()
time.sleep(2)
lipath = '//*[@id="skinBG"]/li'
li_list = browser.find_elements_by_xpath(lipath)#大图的
for i in range(len(li_list)):
imgpath = '//li['+str(i+1)+']/img'
x = li_list[i].find_element_by_xpath(imgpath)
if i ==0:
name = x.get_attribute('alt')
picpath = mapath + os.sep + str(name)
if not os.path.exists(picpath):
os.makedirs(picpath) #创建存放图片的文件夹
else:
print('文件夹已存在!!')
pic_name = x.get_attribute('alt').replace('/','')
pic_url = x.get_attribute('src')
pic = requests.get(pic_url).content
with open(picpath+os.sep+pic_name+'.png','wb') as p:
p.write(pic)
定位的方法是用xpath定位的,在F12里可以复制xpath地址
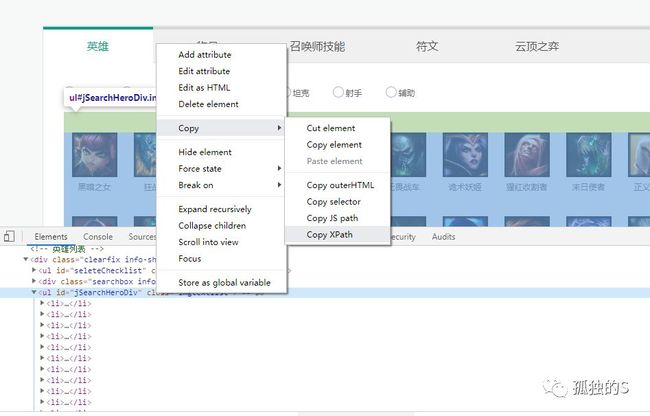
然后在后面加/li,便是获取所有的li里面的数据了。
代码就是先获取这里的地址:
![]()
然后实现点击下一个,然后在获取大图的内容。并用
get_attribute
提取出数据名和url,有一些英雄的名字有斜杆的,所有要替换掉,否则会报错,有的时候会刷新不出来网页,就获取不到数据,紧接着报错,加个循环如果获取不到数据就重新获取即可。
然后就是做循环爬取所有的英雄的图片
一开始打算用英雄的url实现循环,仔细一看,后面几个的英雄并不是叠加尾数,用url不能循环操作,所有利用selenium的自动化的便利性,做点击,获取图片,然后返回英雄选择界面,再点击下一个等等,这样子做循环。
if __name__ == '__main__':
cwpath = os.getcwd()
mpath = cwpath+os.sep+'LOL'
if not os.path.exists(mpath):
os.makedirs(mpath)
else:
print('文件夹已存在!!')
browser.get(mainurl)
time.sleep(5)
h_path = '//*[@id="jSearchHeroDiv"]/li'
h_list = browser.find_elements_by_xpath(h_path)
i = 74
while i
对文件夹的操作,我这里直接保存到项目文件夹下面,用os.getcwd()获取当前路径,也可以相应选择你喜欢的位置,只需要换成绝对路径即可,还有就是文件夹下面的文件夹的时候记得添加一个os.sep,
下面贴上os的常用操作
os.path.sep:#路径分隔符
os.path.altsep: #根目录
os.path.curdir:#当前目录,其实就是一个.。
os.path.pardir:#父目录,其实是两个.。
os.path.abspath(path):#绝对路径
os.path.join(): #常用来链接路径,这个才是最重要的方法。
os.path.split(path): #把path分为目录和文件两个部分,以列表返回
最后爬取的效果就是这样的:
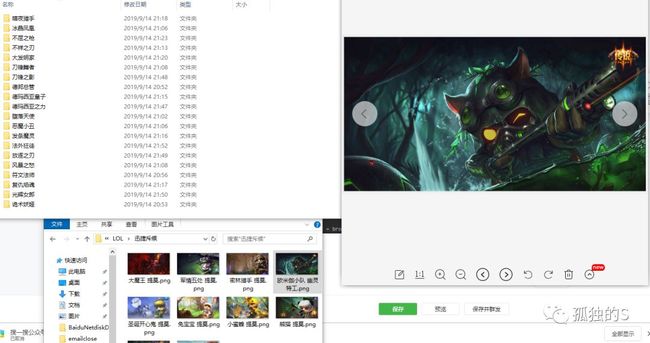
唯一不足的就是爬取的速度很慢,因为加上太多的等待时间和浏览器操作的时间,不过效果还是可以的。
