Tensorflow并行计算:多核(multicore),多线程(multi-thread),计算图分割(Graph Partition)
Github下载完整代码:https://github.com/rockingdingo/tensorflow-tutorial/tree/master/mnist
目录
简介
一、多核并行:CPU多核的运算和资源调用
二、多线程,设置Multi-threads
三、分割计算图模型Graph:将Tensorflow的图运算分配到不同计算单元
简介
利用tensorflow训练深度神经网络模型需要消耗很长时间,因为并行化计算就为提升运行速度提供了重要思路。Tensorflow提供了多种方法来使程序的并行运行,在使用这些方法时需要考虑的问题有:选取的计算设备是CPU还是GPU,每个CPU多少核的资源并行计算,构建计算图Graph时消耗资源如何分配等等问题。下面我们以Linux多核CPU的环境为例介绍几种常见方法来提升你的tensorflow程序的运行速度。
一、多核并行:CPU多核的运算和资源调用
在Tensorflow程序中,我们会经常看到”with tf.device("/cpu:0"): “ 这个语句。单独使用这个语句,而不做其他限制,实际上默认tensorflow程序占用所有可以使用的内存资源和CPU核,比如如果你的linux服务器是8核CPU,那么该程序会迅速占用可以使用的任意CPU,使用接近100%,最终结果就是影响整台服务器的其他程序。因此我们会想到需要限制使用的CPU核的个数和资源。(本次测试是在windows10服务器上,一共有两块CPU,每一块CPU分别都是16核)

运行convolutional.py代码,可以看到CPU1中16核全开,但是有些核的使用率很低!!!

在构建tf.Session() 变量时,可以通过传入tf.ConfigProto() 参数来改变一个tensorflow的session会话所使用的CPU核的个数以及线程数等等。
代码1
config = tf.ConfigProto(device_count={"CPU": 4}, # limit to num_cpu_core CPU usage 限制CPU使用的核的个数
inter_op_parallelism_threads = 1,
intra_op_parallelism_threads = 1,
log_device_placement=True)
with tf.Session(config = config) as sess:
# To Do例如,在上面代码中我们通过 “device_count={"CPU": 4}” 参数来构建一个ConfigProto() 类,传入tf.Session()来使每个会话分配相应的资源,这里我们给tensorflow程序共分配了4个CPU core。
实例
我们对tensorflow tutorial中的MNIST的CNN模型convolutional.py进行适当的修改,使得他限制在4个CPU core上运行,得到convolutional_multicore.py: 运行结果,平均每个step计算一个batch的时间为610 ms左右:(这里测试的是770ms)
Step 0 (epoch 0.00), 26.7 ms
Minibatch loss: 12.054, learning rate: 0.010000
Minibatch error: 90.6%
Validation error: 84.6%
Step 100 (epoch 0.12), 9.5 ms
Minibatch loss: 3.304, learning rate: 0.010000
Minibatch error: 6.2%
Validation error: 7.3%
Step 200 (epoch 0.23), 7.6 ms
Minibatch loss: 3.473, learning rate: 0.010000
Minibatch error: 12.5%
Validation error: 3.5%
...
...
...
Step 8400 (epoch 9.77), 7.7 ms
Minibatch loss: 1.596, learning rate: 0.006302
Minibatch error: 0.0%
Validation error: 0.8%
Step 8500 (epoch 9.89), 7.7 ms
Minibatch loss: 1.612, learning rate: 0.006302
Minibatch error: 1.6%
Validation error: 0.9%
Test error: 0.8%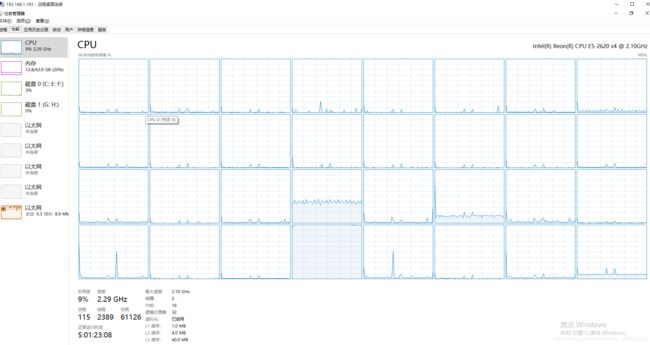
图1: 4 CPU core Single Thread
二、多线程,设置Multi-threads
在进行tf.ConfigProto()初始化时,我们也可以通过设置intra_op_parallelism_threads参数和inter_op_parallelism_threads参数,来控制每个操作符op并行计算的线程个数。二者的区别在于:
(1)intra_op_parallelism_threads 控制运算符op内部的并行:
当运算符op为单一运算符,并且内部可以实现并行时,如矩阵乘法,reduce_sum之类的操作,可以通过设置intra_op_parallelism_threads 参数来并行, intra代表内部。
(2)inter_op_parallelism_threads 控制多个运算符op之间的并行计算:
当有多个运算符op,并且他们之间比较独立,运算符和运算符之间没有直接的路径Path相连。Tensorflow会尝试并行地计 算他们,使用由inter_op_parallelism_threads参数来控制数量的一个线程池。
代码2
我们还是修改上面的MNIST卷积的例子 convolutional_multicore.py,将参数如下:
config = tf.ConfigProto(device_count={"CPU": 4}, # limit to num_cpu_core CPU usage 限制CPU使用的核的个数
inter_op_parallelism_threads = 1,
intra_op_parallelism_threads = 4,
log_device_placement=True)
with tf.Session(config = config) as sess:
# To Do
实例(原测试)
实例比较,下面我们比较线程数为2和4,平均每个batch的运行时间:
当参数为intra_op_parallelism_threads = 2时, 每个step的平均运行时间从610ms降低到380ms。
当参数为intra_op_parallelism_threads = 4时, 每个step的平均运行时间从610ms降低到230ms。
总结,在固定CPUcore的资源限制下,通过合理设置线程thread个数可以明显提升tensorflow程序运行速度。
(本地测试过程中,发现增加线程数后运行速度并没有提升,分析原因是,这程序代码并不需要占用太多CPUcore的资源,所以增加线程对运行速度也并没有什么提升。请大神们指教纠正!!!)
参考 tensorflow/core/protobuf/config.proto 实现
https://github.com/tensorflow/tensorflow/blob/26b4dfa65d360f2793ad75083c797d57f8661b93/tensorflow/core/protobuf/config.proto#L165
三、分割计算图模型Graph:将Tensorflow的图运算分配到不同计算单元
有时我们构建的深度网络的结构十分复杂,会出现这种情况:多个CPU core同时运行时,有的核比较空闲,有的核使用率却达到100%的情况。我们需要尽量避免这种运算符计算不均衡的情况。这时,如果我们将Graph拆分为多个部分,将每个部分(如每一层网络结构)指定到不同的CPU 核上运算,优化计算量的分配,可以使运算速度得到提升。
一个很直观的设计就是按照不同的层来划分,把运算量大的Layer分配单独的CPU,把运算量小的Layer合并分配到同一个CPU core上。
下面是我们做的一个测试,还是tensorflow官网上的 convolutional.py 例子改写,将不同层分配到不同的CPU device上,优化了计算资源,使得程序的速度得以提升,例子为convolutional_graph_partitioned.py。
声明了device_id全局变量记录已经使用的CPU的ID;
调用next_device() 函数返回下一个可用的CPU device id, 如果有可用的则分配并使全局变量device_id 加1, 最终获得的可用的device_id 不会超过在 FLAGS.num_cpu_core中定义的核的总个数。
在model()函数构建图的过程中,通过with tf.device(next_device()): 语句,来将当成的Conv, Pool等运算符分配到单独的CPU上。最终结果为每个batch 平均时间229 ms。
代码3
device_id = -1 # Global Variable Counter for device_id used
def next_device(use_cpu = True):
''' See if there is available next device;
Args: use_cpu, global device_id
Return: new device id
'''
global device_id
if (use_cpu):
if ((device_id + 1) < FLAGS.num_cpu_core):
device_id += 1
device = '/cpu:%d' % device_id
else:
if ((device_id + 1) < FLAGS.num_gpu_core):
device_id += 1
device = '/gpu:%d' % device_id
return device
with tf.device(next_device()):
# To Do Insert Your Code
conv = ...
pool = ...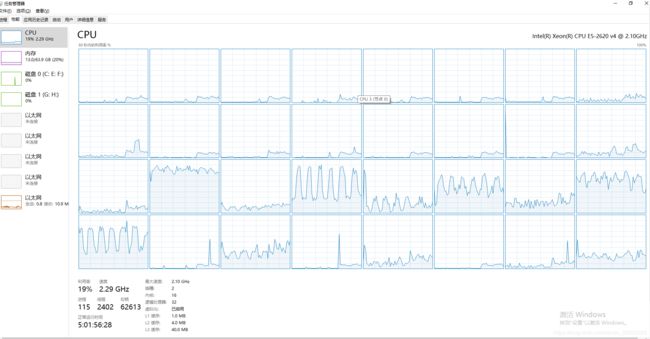
(本地测试可以发现,分割计算图模型Graph,将Tensorflow的图运算分配到不同计算单元,CPU的利用率是有所提高的,从原来的7%提高到19%,但发现运行时间是有所下降的,不知道问题出在哪了???)
延伸阅读
深语人工智能-技术博客: http://www.deepnlp.org/blog/tensorflow-parallelism/
PyPI deepnlp: Deep Learning NLP Pipeline implemented on Tensorflow https://pypi.python.org/pypi/deepnlp
Tensorflow官网的卷积神经网络MNIST的例子convolutional.py
多线程convolutional_multithread.py
分割Graph到不同Device上 convolutional_graph_partitioned.py
参考:https://blog.csdn.net/rockingdingo/article/details/55652662