python爬虫入门练习:正则表达式爬取猫眼电影TOP100排行榜,openpyxl保存本地excel文件
使用requests爬取猫眼电影TOP100排行榜
网址:https://maoyan.com/board/4
方法:Python3,requests.get()获取网页,正则表达式re.findall匹配目标内容
目标:爬取猫眼电影TOP100排行榜,排名,电影名称,主演,上映时间,评分,并保存至本地文件
如何爬取:打开目标网页,鼠标右键查看网页源代码,发现每个电影信息都是以如下形式表示,每个
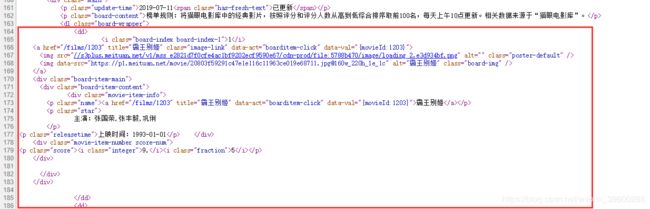
编码思路:为爬取目标,大体上可分为三步,登录-爬取-保存
第一步:
# coding=utf-8
import requests
import re, json
from time import ctime #测试用,返回当前时间
# 定义登录函数,判断返回码
def login(url):
req = requests.get(url)
if req.status_code == 200:
return req.content.decode('utf-8')
else:
return None
第二步:
# 获取页面,正则表达式匹配内容
data = []
def page(text):
html = re.findall(
'([0-9]+).*?<.*?>(.*?)
.*?(.*?)
.*?(.*?)
.*?([0-9\.]+)([0-9]+)',
text, re.S)
#re.S支持换行符;“数字.”中小数点需要转义[0-9\.]+;
for l in html:
datalist = {'排名': l[0], '电影名称': l[1], '主演': l[2].strip()[3:], '上映时间': l[3].strip()[5:],
'评分': l[4] + l[5]}
#strip()去除头尾空格;[3:]截取,目的是去除爬到内容中的“主演:”,[5:]去除“上映时间:”
data.append(datalist)
第三步:
# 打开本地文件,写入
def writefile(localfile,text):
#传入地址和内容
with open(localfile, 'a', encoding='utf-8') as file:
file.write(json.dumps(text, ensure_ascii=False))
#使用with open()打开文件,使用完毕自动关闭;'a'追加模式;json.dumps转换为字符串格式;ensure_ascii=False输出中文
第四部:
#编写主流程,需要爬取的10个页面,只有最后的offset=?的值不同
def main(i):
for i in range(0, 10):
#把前面写的三步曲使用起来,传入具体的值
html = login('https://maoyan.com/board/4?offset=' + str(10 * i))
text=page(html)
writefile('C:\\Users\\ll\\Desktop\\film.txt',text)
第五步:
# 执行起来
if __name__ == '__main__':
main()
由此,大功告成,执行一下,就可以输出到本地文件了!
进一步优化,引入多线程,修改如下内容
import threading
def main(i):
print(i, '线程开始:', ctime())#测试效果用
html = login('https://maoyan.com/board/4?offset=' + str(10 * i))
page(html)
print(i, '线程结束:', ctime())#测试效果用
if __name__ == '__main__':
Threadtest=[threading.Thread(target=main,args=(i,)) for i in range(10)]
for t in Threadtest:
t.start()
time.sleep(1)#睡眠1秒,测试效果更明显
t.join()
writefile('C:\\Users\\ll\\Desktop\\film.txt',data)
奉上多进程方法
from multiprocessing import Process
from multiprocessing import Pool
# 进程方式执行
processes = [Process(target=main,args=(i,) ) for i in range(10)] # 用列表生成式 生成10个线程
for p in processes:
p.start() # 启动刚刚创建的10个进程
p.join() # 子进程全部结束 主进程才结束
print('process finished')
#进程池 多进程的方式来爬取
def end(arg):# 单个进程结束执行的方法
print("process finish")
pool = Pool(5)
for i in range(10):
pool.apply(main,args=(i,)) #串行执行
# pool.apply_async(func=main, args=(i*10,), callback=end) # 并行执行,callback,是进程结束后的回调,是主进程调用的回调。
pool.close() # 需先close,再join
pool.join() # join: 等待子进程,主线程再结束
print('main process finished')
如果觉得存储的txt文本内容杂乱,不方便查看,可以改成使用excel存储,更改如下:
import openpyxl
def writeexcel(localfile, text):
excel = openpyxl.load_workbook(localfile)
sheet = excel['Sheet1']
sheet['A1'] = '排名'
sheet['B1'] = '电影名称'
sheet['C1'] = '主演'
sheet['D1'] = '上映时间'
for i in range(len(text)):
# len(text)条数据,Excel首行为列名,从第二行开始写入
sheet['A' + str(i + 2)] = text[i]['排名']
sheet['B' + str(i + 2)] = text[i]['电影名称']
sheet['C' + str(i + 2)] = text[i]['主演']
sheet['D' + str(i + 2)] = text[i]['上映时间']
excel.save(localfile)
相应的调用更改为writeexcel(),传入本地excle文件地址
if __name__ == '__main__':
Threadtest = [threading.Thread(target=main, args=[i, ]) for i in range(10)]
for t in Threadtest:
t.start()
t.join()
#filepath = 'C:\\Users\\ll\\Desktop\\film.txt'
#writefile(filepath, data)
excelpath = 'C:\\Users\\ll\\Desktop\\film.xlsx'
writeexcel(excelpath, data)
补充一下可能遇到的问题:
报错
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1056)
这个错误是https的ssl认证导致的,解决办法如下,verify=False去除ssl认证:
def login(url):
req = requests.get(url, verify=False)
修改后可以执行成功,但是日志会输出大量的Warning信息:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
如果想把这些报错信息去掉,只需要在请求的地方加上requests.packages.urllib3.disable_warnings() 就可以解决
def login(url):
requests.packages.urllib3.disable_warnings()
req = requests.get(url, verify=False)
报错:PermissionError: [Errno 13] Permission denied
1.已经打开了这个文件,关闭这个文件即可
2.输入的不是一个文件地址,可能是文件夹或者目录
报错:DeprecationWarning: Call to deprecated function get_sheet_by_name (Use wb[sheetname])
使用了get_sheet_by_name() 方法获取sheet页,新版已不建议使用,需要使用wb[sheetname]方式,即文中excel[‘Sheet1’]来实现
下一篇介绍BeautifulSoup的匹配方式,pandas数据处理,传送门:【python爬虫入门练习】BeautifulSoup爬取猫眼电影TOP100排行榜,pandas保存本地excel文件