Python3 基础教程最全总结
在之前学习Python的过程中,有些知识没有学过,导致在现在的编程过程中,针对一个问题的解决方法有限。于是,又复习了一遍Python的教程。本文舍弃了一些比较简单的内容,但很大程度的保留了知识框架。将学习过程中,不常用或者常用但不熟悉的知识加了背景色。
系列文章
Python3 基础教程最全总结
Python3 进阶教程最全总结
一文掌握Python基础知识
一文掌握Python列表/元组/字典/集合
一文掌握Python函数用法
Python面向对象之类与对象详解
Python面向对象之装饰器与封装详解
Python面向对象之继承和多态详解
Python异常处理和模块详解
Python文件(I/O)操作详解
Python网络编程之Socket原理与基本用法
Python多线程threading模块基本用法
Python爬虫正则表达式详解 爬爬爬爬个虫子
Python爬虫实战Urllib抓取段子
Python爬虫实战抓包分析视频评论
Python爬虫实战Requests抓取博客文章
Python爬虫实战Scrapy抓取商品信息并写入数据库
文章目录
- 系列文章
- 1.基础语法
- 1.1 编码
- 1.2 标识符
- 1.3 保留字
- 1.4 注释
- 1.5 数据类型
- 1.6 字符串
- 1.7 缩进
- ==1.8 变量==
- 1.8.1 基本用法
- 1.8.2 全局变量
- 2. Python3 基本数据类型
- 2.1 Numbers(数字)
- summary
- 2.2 String(字符串)
- summary
- 2.3 List(列表)
- summary
- 2.4 ==Tuple(元组)==
- summary
- 2.5 ==Sets(集合)==
- summary
- 2.6 ==Dictionaries(字典)==
- summary
- 3. 运算符
- 3.1 算术运算符
- 3.2 比较运算符
- 3.3 赋值运算符
- 3.4 ==位运算符==
- 3.5 ==逻辑运算符==
- 3.6 ==成员运算符==
- 3.7 ==身份运算符==
- 3.8 ==运算符优先级==
- 4. 字符串
- 4.1 字符串输出
- 4.2 字符串元素操作
- 5. ==列表==
- 6. ==元组==
- 6.1 元组操作
- 6.2 元组内置函数
- 7. 字典
- 7.1 字典操作
- 7.2 ==字典内置函数&方法==
- 8.条件控制
- 9. 循环
- 9.1 while 循环
- 9.2 for循环
- 9.3 range()函数
- ==9.4 break和continue语句及循环中的else子句==
- 9.5 pass语句
- 10.==迭代器与生成器==
- 10.1 迭代器
- 10.2 生成器
- ==yield==
- 11. 函数
- 11.1 函数定义
- 11.2 变量作用域
- 11.3 ==返回值==
- 11.4 ==可变参数列表==
- 11.5 ==lambda==
- 12. ==数据结构==
- 12.1 列表
- 12.2 del语句
- 12.3 元组和序列
- 12.4 集合
- 12.5 字典
- 12.6 遍历技巧
- 13. 模块
- 13.1 import 语句
- 13.2 __name__ 属性
- 13.3 dir()
- 13.4 标准模块
- 13.5 包
- 14. 输入和输出
- 14.1 读和写文件
- 14.2 文件对象的方法
- 14.3 ==pickle模块==
- 15. File 方法
- 16. OS 文件/目录方法
- 17. 错误和异常
- 17.1 语法错误
- 17.2 异常
- 17.3 异常处理
- 18. 实例
1.基础语法
1.1 编码
默认情况下,Python 3源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指定不同的编码:
# -*- coding: cp-1252 -*-
1.2 标识符
- 第一个字符必须是字母表中字母或下划线’_’。
- 标识符的其他的部分有字母、数字和下划线组成。
- 标识符对大小写敏感。
在Python 3中,非-ASCII 标识符也是允许的了。
1.3 保留字
保留字即关键字,我们不能把它们用作任何标识符名称。Python的标准库提供了一个keyword module,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue',
'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global',
'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise',
'return', 'try', 'while', 'with', 'yield']
1.4 注释
Python中单行注释以#开头,多行注释用三个单引号(’’’)或者三个双引号(""")将注释括起来。
1.5 数据类型
python中数有四种类型:整数、长整数、浮点数和复数。
- 整数, 如 1;
- 长整数 是比较大的整数;
- 浮点数 如 1.23、3E-2;
- 复数 如 1 + 2j、 1.1 + 2.2j。
1.6 字符串
- python中单引号和双引号使用完全相同。
- 使用三引号(’’'或""")可以指定一个多行字符串。
- 转义符
\ - 自然字符串, 通过在字符串前加r或R。 如 r"this is a line with \n" 则\n会显示,并不是换行。
- python允许处理unicode字符串,加前缀u或U, 如 u"this is an unicode string"。
- 字符串是不可变的。
- 按字面意义级联字符串,如"this " "is " "string"会被自动转换为this is string。
- 默认的分切索引很有用:默认的第一个索引为零,第二个索引默认为字符串可以被分切的长度。
>>> word[:2] # 前两个字符
'He'
>>> word[2:] # 除了前两个字符之外,其后的所有字符
'lpA'
- 不同于C字符串的是,Python字符串不能被改变。向一个索引位置赋值会导致错误。
1.7 缩进
缩进指的是代码行开头的空格。在其他编程语言中,代码缩进仅出于可读性的考虑,而 Python 中的缩进非常重要。Python 使用缩进来指示代码块。
1.8 变量
Python 没有声明变量的命令。在 Python 中,变量是在为其赋值时创建的。
变量不需要使用任何特定类型声明,甚至可以在设置后更改其类型。
1.8.1 基本用法
- 字符串变量可以使用单引号或双引号进行声明:
x = "Bill"
# is the same as
x = 'Bill'
- 向多个变量赋值
Python 允许在一行中为多个变量赋值:
x, y, z = "Orange", "Banana", "Cherry"
- 可以在一行中为多个变量分配相同的值:
x = y = z = "Orange"
- 输出变量
x = "awesome"
print("Python is " + x)
- 可以使用 + 字符将变量与另一个变量相加:
x = "Python is "
y = "awesome"
z = x + y
print(z)
- 对于数字,+ 字符用作数学运算符:
x = 5
y = 10
print(x + y)
- 如果尝试组合字符串和数字,Python 会给出错误:
x = 10
y = "Bill"
print(x + y)
1.8.2 全局变量
在函数外部创建的变量(如上述所有实例所示)称为全局变量。
全局变量可以被函数内部和外部的每个功能使用。
global 关键字
通常,在函数内部创建变量时,该变量是局部变量,只能在该函数内部使用。
要在函数内部创建全局变量,您可以使用 global 关键字。
- 如果用了 global 关键字,则该变量属于全局范围:
def myfunc():
global x
x = "fantastic"
myfunc()
print("Python is " + x)
- 如果要在函数内部更改全局变量,使用 global 关键字。
x = "awesome"
def myfunc():
global x
x = "fantastic"
myfunc()
print("Python is " + x)
2. Python3 基本数据类型
在Python中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
Python 3中有六个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Sets(集合)
- Dictionaries(字典)
2.1 Numbers(数字)
Python 3支持int、float、bool、complex(复数)。
数值类型的赋值和计算都是很直观的,就像大多数语言一样。内置的type()函数可以用来查询变量所指的对象类型。
>>> 2 / 4 # 除法,得到一个浮点数
0.5
>>> 2 // 4 # 除法,得到一个整数
0
>>> 17 % 3 # 取余
2
>>> 2 ** 5 # 乘方
32
summary
- 1、数值的除法(/)总是返回一个浮点数,要获取整数使用//操作符;
- 2、在混合计算时,Pyhton会把整型转换成为浮点数;
2.2 String(字符串)
- Python中的字符串str用单引号(’ ')或双引号(" ")括起来,同时使用反斜杠()转义特殊字符。
>>> s = 'Yes,he doesn\'t'
>>> print(s, type(s), len(s))
Yes,he doesn't 14
- 如果你不想让反斜杠发生转义,可以在字符串前面添加一个r,表示原始字符串:
>>> print('C:\some\name')
C:\some
ame
>>> print(r'C:\some\name')
C:\some\name
- Python中的字符串有两种索引方式,第一种是从左往右,从0开始依次增加;第二种是从右往左,从-1开始依次减少。注意,没有单独的字符类型,一个字符就是长度为1的字符串。
>>> word = 'Python'
>>> print(word[0], word[5])
P n
>>> print(word[-1], word[-6])
n P
- 可以对字符串进行切片,获取一段子串。用冒号分隔两个索引,形式为变量[头下标:尾下标]。截取的范围是前闭后开的,并且两个索引都可以省略:
>>> word = 'ilovepython'
>>> word[1:5]
'love'
>>> word[:]
'ilovepython'
>>> word[5:]
'python'
>>> word[-10:-6]
'love'
- 与C字符串不同的是,Python字符串不能被改变。向一个索引位置赋值,比如word[0] = 'm’会导致错误。
summary
- 1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
- 2、字符串可以用+运算符连接在一起,用*运算符重复。
- 3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
- 4、Python中的字符串不能改变。
2.3 List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。列表是写在方括号之间、用逗号分隔开的元素列表。
- 列表中元素的类型可以不相同:
>>> a = ['him', 25, 100, 'her']
>>> print(a)
['him', 25, 100, 'her']
- 列表还支持串联操作,使用+操作符:
>>> a = ['him', 25, 100, 'her']
>>> print(a)
['him', 25, 100, 'her']
- 与Python字符串不一样的是,列表中的元素是可以改变的:
>>> a = [1, 2, 3, 4, 5, 6]
>>> a[0] = 9
>>> a[2:5] = [13, 14, 15]
>>> a
[9, 2, 13, 14, 15, 6]
>>> a[2:5] = [] # 删除
>>> a
[9, 2, 6]
summary
- 1、List写在方括号之间,元素用逗号隔开。
- 2、和字符串一样,list可以被索引和切片。
- 3、List可以使用+操作符进行拼接。
- 4、List中的元素是可以改变的。
2.4 Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号里,元素之间用逗号隔开。
- 元组中的元素类型也可以不相同:
>>> a = (1991, 2014, 'physics', 'math')
>>> print(a, type(a), len(a))
(1991, 2014, 'physics', 'math') <class 'tuple'> 4
- 元组与字符串类似,可以被索引且下标索引从0开始,也可以进行截取/切片(看上面,这里不再赘述)。其实,可以把字符串看作一种特殊的元组。
>>> tup = (1, 2, 3, 4, 5, 6)
>>> print(tup[0], tup[1:5])
1 (2, 3, 4, 5)
>>> tup[0] = 11 # 修改元组元素的操作是非法的
- 虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。构造包含0个或1个元素的tuple是个特殊的问题,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
- 元组也支持用+操作符:
>>> tup1, tup2 = (1, 2, 3), (4, 5, 6)
>>> print(tup1+tup2)
(1, 2, 3, 4, 5, 6)
summary
string、list和tuple都属于sequence(序列)。
- 1、与字符串一样,元组的元素不能修改。
- 2、元组也可以被索引和切片,方法一样。
- 3、注意构造包含0或1个元素的元组的特殊语法规则。
- 4、元组也可以使用+操作符进行拼接。
2.5 Sets(集合)
- 集合(set)是一个无序不重复元素的集。
- 基本功能:进行成员关系测试和消除重复元素。
- 可用大括号或者 set()函数创建set集合。
>>> student = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
>>> print(student) # 重复的元素被自动去掉
{'Jim', 'Jack', 'Mary', 'Tom', 'Rose'}
>>> 'Rose' in student # membership testing(成员测试)
True
>>> # set可以进行集合运算
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'b', 'c', 'd', 'r'}
>>> a - b # a和b的差集
{'b', 'd', 'r'}
>>> a | b # a和b的并集
{'l', 'm', 'a', 'b', 'c', 'd', 'z', 'r'}
>>> a & b # a和b的交集
{'a', 'c'}
>>> a ^ b # a和b中不同时存在的元素
{'l', 'm', 'b', 'd', 'z', 'r'}
summary
- 创建一个空集合必须用 set() 而不是 { },因为{ }是用来创建一个空字典。
2.6 Dictionaries(字典)
- 字典(dictionary)是Python中另一个非常有用的内置数据类型。
- 字典是一种映射类型(mapping type),它是一个无序的键 : 值对集合。
- 关键字必须使用不可变类型,也就是说
list和包含可变类型的tuple不能做关键字。 - 在同一个字典中,关键字还必须互不相同。
>>> dic = {} # 创建空字典
>>> tel = {'Jack':1557, 'Tom':1320, 'Rose':1886}
>>> tel
{'Tom': 1320, 'Jack': 1557, 'Rose': 1886}
>>> tel['Jack'] # 主要的操作:通过key查询
1557
>>> del tel['Rose'] # 删除一个键值对
>>> tel['Mary'] = 4127 # 添加一个键值对
>>> tel
{'Tom': 1320, 'Jack': 1557, 'Mary': 4127}
>>> list(tel.keys()) # 返回所有key组成的list
['Tom', 'Jack', 'Mary']
>>> sorted(tel.keys()) # 按key排序
['Jack', 'Mary', 'Tom']
>>> 'Tom' in tel # 成员测试
True
>>> 'Mary' not in tel # 成员测试
False
另外,字典类型也有一些内置的函数,例如clear()、keys()、values()等。
summary
- 1、字典是一种映射类型,它的元素是键值对。
- 2、字典的关键字必须为不可变类型,且不能重复。
- 3、创建空字典使用{ }。
3. 运算符
3.1 算术运算符
假设 a=10,b=21。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 返回商的整数部分 | 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
3.2 比较运算符
假设 a=10,b=21。
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。 | 注意,这些变量名的大写。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
3.3 赋值运算符
假设a=10,变量b=20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
3.4 位运算符
假设 a = 60,b = 13。
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| |
按位或运算符:只要对应的两个二进位有一个为1时,结果位就为1。 | (a|b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移位运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移位运算符:把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
十进制转二进制的方法:整数部分采用“除基取余法”;小数部分采用“乘基取整法”
二进制转十进制的方法: 引用知乎用户回答中的一张图:
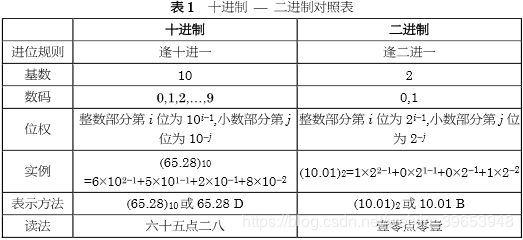
3.5 逻辑运算符
假设变量 a =10, b = 20
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
3.6 成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
3.7 身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is是判断两个标识符是不是引用自一个对象 | x is y, 如果 id(x) 等于 id(y) , is 返回结果 1 |
| is not | is not是判断两个标识符是不是引用自不同对象 | x is not y, 如果 id(x) 不等于 id(y). is not 返回结果 1 |
3.8 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
^ | |
位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not or and | 逻辑运算符 |
4. 字符串
4.1 字符串输出
- 以下使用 反斜线(\) 来续行:
hello = "This is a rather long string containing\n\
several lines of text just as you would do in C.\n\
Note that whitespace at the beginning of the line is\
significant."
print(hello)
注意,其中的换行符仍然要使用 \n 表示——反斜杠后的换行符被丢弃了。以上例子将如下输出:
This is a rather long string containing
several lines of text just as you would do in C.
Note that whitespace at the beginning of the line is significant.
- 或者,字符串可以被 “”" (三个双引号)或者 ‘’’ (三个单引号)括起来。使用三引号时,换行符不需要转义,它们会包含在字符串中。以下的例子使用了一个转义符,避免在最开始产生一个不需要的空行。
print("""\
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
""")
其输出如下:
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
4.2 字符串元素操作
- 字符串可以被索引;就像 C 语言一样,字符串的第一个字符的索引为 0。没有单独的字符类型;一个字符就是长度为一的字符串。就像Icon编程语言一样,子字符串可以使用分切符来指定:用冒号分隔的两个索引。
>>> word = 'Help' + 'A'
>>> word
'HelpA'
>>> word[4]
'A'
>>> word[0:2]
'Hl'
>>> word[2:4]
'ep'
- 默认的分切索引很有用:默认的第一个索引为零,第二个索引默认为字符串可以被分切的长度。
>>> word[:2] # 前两个字符
'He'
>>> word[2:] # 除了前两个字符之外,其后的所有字符
'lpA'
- 不同于C字符串的是,Python字符串不能被改变。向一个索引位置赋值会导致错误:
>>> word[0] = 'x'
Traceback (most recent call last):
File "", line 1, in ?
TypeError: 'str' object does not support item assignment
>>> word[:1] = 'Splat'
Traceback (most recent call last):
File "", line 1, in ?
TypeError: 'str' object does not support slice assignment
- 然而,用组合内容的方法来创建新的字符串是简单高效的:
>>> 'x' + word[1:]
'xelpA'
>>> 'Splat' + word[4]
'SplatA'
在分切操作字符串时,有一个很有用的规律: s[:i] + s[i:] 等于 s.
>>> word[:2] + word[2:]
'HelpA'
>>> word[:3] + word[3:]
'HelpA'
- 对于有偏差的分切索引的处理方式也很优雅:一个过大的索引将被字符串的大小取代,上限值小于下限值将返回一个空字符串。
>>> word[1:100]
'elpA'
>>> word[10:]
>>> word[2:1]
- 在索引中可以使用负数,这将会从右往左计数。
>>> word[-1] # 最后一个字符
'A'
>>> word[-2] # 倒数第二个字符
'p'
>>> word[-2:] # 最后两个字符
'pA'
>>> word[:-2] # 除了最后两个字符之外,其前面的所有字符
'Hel'
# 但要注意, -0 和 0 完全一样,所以 -0 不会从右开始计数!
>>> word[-0] # (既然 -0 等于 0)
'H'
- 超出范围的负数索引会被截去多余部分,但不要尝试在一个单元素索引(非分切索引)里使用:
>>> word[-100:]
'HelpA'
>>> word[-10] # 错误
Traceback (most recent call last):
File "", line 1, in ?
IndexError: string index out of range
- 有一个方法可以让您记住分切索引的工作方式,想像索引是指向字符之间,第一个字符左边的数字是 0。接着,有n个字符的字符串最后一个字符的右边是索引n,例如:
+---+---+---+---+---+
| H | e | l | p | A |
+---+---+---+---+---+
0 1 2 3 4 5
-5 -4 -3 -2 -1
第一行的数字 0…5 给出了字符串中索引的位置;第二行给出了相应的负数索引。分切部分从 i 到 j 分别由在边缘被标记为 i 和 j 的全部字符组成。
对于非负数分切部分,如果索引都在有效范围内,分切部分的长度就是索引的差值。例如, word[1:3] 的长度是2。
- 内置的函数 len() 用于返回一个字符串的长度:
>>> s = 'supercalifragilisticexpialidocious'
>>> len(s)
34
5. 列表
Python囊括了大量的复合数据类型,用于组织其它数值。最有用的是列表,即写在方括号之间、用逗号分隔开的数值列表。列表内的项目不必全是相同的类型。
>>> a = ['spam', 'eggs', 100, 1234]
a
['spam', 'eggs', 100, 1234]
squares = [1, 4, 9, 16, 25]
squares
[1, 4, 9, 16, 25]
squares[0] # 索引返回的指定项
1
squares[-1]
25
squares[-3:] # 切割列表并返回新的列表
[9, 16, 25]
- 所有的分切操作返回一个包含有所需元素的新列表。如下例中,分切将返回列表 squares 的一个拷贝:
>>> squares[:]
[1, 4, 9, 16, 25]
- 列表还支持拼接操作:
>>> squares + [36, 49, 64, 81, 100]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
- Python 字符串是固定的,列表可以改变其中的元素:
>>> cubes = [1, 8, 27, 65, 125]
4 3
64
cubes[3] = 64 # 修改列表值
cubes
[1, 8, 27, 64, 125]
- 可以通过使用append()方法在列表的末尾添加新项:
>>> cubes.append(216) # cube列表中添加新值
cubes.append(7 3) # cube列表中添加第七个值
cubes
[1, 8, 27, 64, 125, 216, 343]
- 可以修改指定区间的列表值:
>>> letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
letters
['a', 'b', 'c', 'd', 'e', 'f', 'g']
#替换一些值
letters[2:5] = ['C', 'D', 'E']
letters
['a', 'b', 'C', 'D', 'E', 'f', 'g']
#移除值
letters[2:5] = []
letters
['a', 'b', 'f', 'g']
#清除列表
letters[:] = []
letters
[]
- 内置函数 len() 用于统计列表:
>>> letters = ['a', 'b', 'c', 'd']
len(letters)
4
- 可以使用嵌套列表(在列表里创建其它列表),例如:
>>> a = ['a', 'b', 'c']
n = [1, 2, 3]
x = [a, n]
x
[['a', 'b', 'c'], [1, 2, 3]]
x[0]
['a', 'b', 'c']
x[0][1]
'b'
6. 元组
**Python 的元组与列表类似,不同之处在于元组的元素不能修改。**元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
6.1 元组操作
- 创建空元组
tup1 = ();
- 元组中只包含一个元素时,需要在元素后面添加逗号
tup1 = (50,);
- 访问元组
tup1 = ('Google', 'W3CSchool', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print ("tup1[0]: ", tup1[0])
print ("tup2[1:5]: ", tup2[1:5])
输出为:
tup1[0]: Google
tup2[1:5]: (2, 3, 4, 5)
- 修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2;
print (tup3)
以上实例输出结果:
(12, 34.56, 'abc', 'xyz')
- 删除元祖
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
tup = ('Google', 'W3CSchool', 1997, 2000)
del tup;
- 元组索引,截取
>>> L = ('Google', 'Taobao', 'W3CSchool')
>>> L[2]
'W3CSchool'
>>> L[-2]
'Taobao'
>>> L[1:]
('Taobao', 'W3CSchool')
6.2 元组内置函数
- len(tuple)
>>> tuple1 = ('Google', 'W3CSchool', 'Taobao')
>>> len(tuple1)
3
>>>
- max(tuple)
>>> tuple2 = ('5', '4', '8')
>>> max(tuple2)
'8'
>>>
- min(tuple)
>>> tuple2 = ('5', '4', '8')
>>> min(tuple2)
'4'
>>>
- tuple(seq)
>>> list1= ['Google', 'Taobao', 'W3CSchool', 'Baidu']
>>> tuple1=tuple(list1)
>>> tuple1
('Google', 'Taobao', 'W3CSchool', 'Baidu')
7. 字典
7.1 字典操作
- 创建字典
dict0 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
dict1 = { 'abc': 456 };
dict2 = { 'abc': 123, 98.6: 37 };
- 访问字典元素
dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'}
print ("dict['Name']: ", dict['Name'])
print ("dict['Age']: ", dict['Age'])
输出:
dict['Name']: W3CSchool
dict['Age']: 7
- 修改字典
dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8; # 更新 Age
dict['School'] = "W3Cschool教程" # 添加信息
- 删除字典元素
dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'}
del dict['Name'] # 删除键 'Name'
dict.clear() # 删除字典
del dict # 删除字典
- 字典键的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
- 1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Name': 'W3CSchool', 'Age': 7, 'Name': '小菜鸟'}
print ("dict['Name']: ", dict['Name'])
输出:
dict['Name']: 小菜鸟
- 2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
dict = {['Name']: 'W3CSchool', 'Age': 7}
print ("dict['Name']: ", dict['Name'])
输出:
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'W3CSchool', 'Age': 7}
TypeError: unhashable type: 'list'
7.2 字典内置函数&方法
- len(dict)
计算字典元素个数,即键的总数。
>>> dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'}
>>> len(dict)
3
- str(dict)
输出字典以可打印的字符串表示。
>>> dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'}
>>> str(dict)
"{'Name': 'W3CSchool', 'Class': 'First', 'Age': 7}"
- type(variable)
返回输入的变量类型,如果变量是字典就返回字典类型。
>>> dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'}
>>> type(dict)
<class 'dict'>
| 序号 | 函数 | 描述 |
|---|---|---|
| 1 | radiansdict.clear() | 删除字典内所有元素 |
| 2 | radiansdict.copy() | 返回一个字典的浅复制 |
| 3 | radiansdict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | radiansdict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| 5 | key in dict | 如果键在字典dict里返回true,否则返回false |
| 6 | radiansdict.items() | 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | radiansdict.keys() | 以列表返回一个字典所有的键 |
| 8 | radiansdict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | radiansdict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| 10 | radiansdict.values() | 以列表返回字典中的所有值 |
8.条件控制
- 一般结构:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
- 以下为if中常用的操作运算符:
| 操作符 | 描述 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| > | 大于 |
| >= | 大于或等于 |
| == | 等于,比较对象是否相等 |
| != | 不等于 |
9. 循环
9.1 while 循环
- Python中while语句的一般形式:
while 判断条件:
statements
- 以下实例使用了 while 来计算 1 到 100 的总和:
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("Sum of 1 until %d: %d" % (n,sum))
执行结果如下:
Sum of 1 until 100: 5050
9.2 for循环
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
- for循环的一般格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>
- 实例:
>>> languages = ["C", "C++", "Perl", "Python"]
>>> for x in languages:
... print (x)
...
C
C++
Perl
Python
>>>
9.3 range()函数
- 如果需要遍历数字序列,可以使用内置range()函数。它会生成数列,例如:
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
- 可以使用range指定区间的值:
>>> for i in range(5,9) :
print(i)
5
6
7
8
>>>
- 也可以使range以指定数字开始并指定不同的增量(甚至可以是负数;有时这也叫做‘步长’):
>>> for i in range(0, 10, 3) :
print(i)
0
3
6
9
>>>
- 可以结合range()和len()函数以遍历一个序列的索引,如下所示:
>>> a = ['Mary', 'had', 'a', 'little', 'lamb']
>>> for i in range(len(a)):
... print(i, a[i])
...
0 Mary
1 had
2 a
3 little
4 lamb
9.4 break和continue语句及循环中的else子句
break语句可以跳出for和while的循环体。如果你从for或while循环中终止,任何对应的循环else块将不执行。
continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
循环语句可以有else子句;它在穷尽列表(以for循环)或条件变为假(以while循环)循环终止时被执行,但循环被break终止时不执行。如下查寻质数的循环例子:
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0:
... print(n, 'equals', x, '*', n//x)
... break
... else:
... # 循环中没有找到元素
... print(n, 'is a prime number')
...
2 is a prime number
3 is a prime number
4 equals 2 * 2
5 is a prime number
6 equals 2 * 3
7 is a prime number
8 equals 2 * 4
9 equals 3 * 3
9.5 pass语句
pass语句什么都不做。它只在语法上需要一条语句但程序不需要任何操作时使用。例如:
>>> while True:
... pass # 等待键盘中断 (Ctrl+C)
10.迭代器与生成器
10.1 迭代器
- 1.迭代是Python最强大的功能之一,是访问集合元素的一种方式。
- 2.迭代器是一个可以记住遍历的位置的对象。
- 3.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 4.迭代器有两个基本的方法:iter() 和 next()。
- 字符串,列表或元组对象都可用于创建迭代器:
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
>>>
- 迭代器对象可以使用常规for语句进行遍历:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
执行以上程序,输出结果如下:
1 2 3 4
- 也可以使用 next() 函数:
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
执行以上程序,输出结果如下:
1
2
3
4
10.2 生成器
- 1.在 Python 中,使用了 yield 的函数被称为生成器(generator)。
- 2.跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 3.在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回yield的值。并在下一次执行 next()方法时从当前位置继续运行。
以下实例使用 yield 实现斐波那契数列:
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
执行以上程序,输出结果如下:
0 1 1 2 3 5 8 13 21 34 55
yield
引用一位博主的解释:
yield是python的一个关键字,一个带有yield的函数就是一个生成器generator.当你使用一个yield的时候,对应的函数就是一个生成器了。生成器的功能就是在yield的区域进行迭代进行。
yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行。return 的作用:如果没有 return,则默认执行至函数完毕,返回的一 般是 yield的变量
在python的函数(function)定义中,只要出现了yield表达式(Yield expression),那么事实上定义的是一个generator function, 调用这个generator function返回值是一个generator。这根普通的函数调用有所区别,例如:
def gen_generator():
yield 1
def gen_value():
return 1
if __name__ == '__main__':
ret = gen_generator()
print(ret, type(ret)) #
ret = gen_value()
print(ret, type(ret)) # 1 从上面的代码可以看出,gen_generator函数返回的是一个generator实例,generator有以下特别:
- 遵循迭代器(iterator)协议,迭代器协议需要实现iter、next接口;
- 能过多次进入、多次返回,能够暂停函数体中代码的执行。
11. 函数
11.1 函数定义
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表):
函数体
11.2 变量作用域
函数变量作用域
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
通过以下实例,你可以清楚了解Python函数变量的作用域:
a = 4 # 全局变量
def print_func1():
a = 17 # 局部变量
print("in print_func a = ", a)
def print_func2():
print("in print_func a = ", a)
print_func1()
print_func2()
print("a = ", a)
以上实例运行结果如下:
in print_func a = 17
in print_func a = 4
a = 4
11.3 返回值
Python的函数的返回值使用return语句,可以将函数作为一个值赋值给指定变量:
def return_sum(x,y):
c = x + y
return c
res = return_sum(4,5)
print(res)
也可以让函数返回空值:
def empty_return(x,y):
c = x + y
return
res = empty_return(4,5)
print(res)
11.4 可变参数列表
一个最不常用的选择是可以让函数调用可变个数的参数.这些参数被包装进一个元组(查看元组和序列).在这些可变个数的参数之前,可以有零到多个普通的参数:
def arithmetic_mean(*args):
sum = 0
for x in args:
sum += x
return sum
print(arithmetic_mean(45,32,89,78))
print(arithmetic_mean(8989.8,78787.78,3453,78778.73))
print(arithmetic_mean(45,32))
print(arithmetic_mean(45))
print(arithmetic_mean())
上实例输出结果为:
244
170009.31
77
45
0
11.5 lambda
lambda 函数是一种小的匿名函数。lambda 函数可接受任意数量的参数,但只能有一个表达式。
- 语法
lambda arguments : expression
- 实例
一个 lambda 函数,它把参数 a、b 和 c 相加并打印结果:
x = lambda a, b, c : a + b + c
print(x(5, 6, 2))
- 为何使用 Lambda 函数?
如果在短时间内需要匿名函数,可使用 lambda 函数。当把 lambda 用作另一个函数内的匿名函数时,会更好地展现 lambda 的强大能力。
假设有一个带一个参数的函数定义,并且该参数将乘以未知数字:
def myfunc(n):
return lambda a : a * n
使用该函数定义来创建一个总是使所发送数字加倍的函数:
def myfunc(n):
return lambda a : a * n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11))
print(mytripler(11))
运行结果为:
22
33
12. 数据结构
12.1 列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
- 以下是 Python 中列表的方法:
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x)会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置删除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被删除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
下面示例演示了列表的大部分方法:
>>> a = [66.25, 333, 333, 1, 1234.5]
>>> print(a.count(333), a.count(66.25), a.count('x'))
2 1 0
>>> a.insert(2, -1)
>>> a.append(333)
>>> a
[66.25, 333, -1, 333, 1, 1234.5, 333]
>>> a.index(333)
1
>>> a.remove(333)
>>> a
[66.25, -1, 333, 1, 1234.5, 333]
>>> a.reverse()
>>> a
[333, 1234.5, 1, 333, -1, 66.25]
>>> a.sort()
>>> a
[-1, 1, 66.25, 333, 333, 1234.5]
- 将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。例如:
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]
- 将列表当作队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])
-
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
>>> vec = [2, 4, 6]
>>> [3*x for x in vec]
[6, 12, 18]
现在我们玩一点小花样:
>>> [[x, x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
这里我们对序列里每一个元素逐个调用某方法:
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip() for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
我们可以用 if 子句作为过滤器:
>>> [3*x for x in vec if x > 3]
[12, 18]
以下是一些关于循环和其它技巧的演示:
>>> vec1 = [2, 4, 6]
>>> vec2 = [4, 3, -9]
>>> [x*y for x in vec1 for y in vec2]
[8, 6, -18, 16, 12, -36, 24, 18, -54]
>>> [x+y for x in vec1 for y in vec2]
[6, 5, -7, 8, 7, -5, 10, 9, -3]
>>> [vec1[i]*vec2[i] for i in range(len(vec1))]
[8, 12, -54]
列表推导式可以使用复杂表达式或嵌套函数:
>>> [str(round(355/113, i)) for i in range(1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']
- 嵌套列表解析
Python的列表还可以嵌套。以下实例展示了3X4的矩阵列表:
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]
以下实例将3X4的矩阵列表转换为4X3列表:
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
以下实例也可以使用以下方法来实现:
>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
另外一种实现方法:
>>> transposed = []
>>> for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
12.2 del语句
**使用 del 语句可以从一个列表中依索引而不是值来删除一个元素。**这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表(我们以前介绍的方法是给该切割赋一个空列表)。例如:
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]
也可以用 del 删除实体变量:
>>> del a
12.3 元组和序列
元组由若干逗号分隔的值组成,例如:
>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
如你所见,元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可能有或没有括号, 不过括号通常是必须的(如果元组是更大的表达式的一部分)。
12.4 集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号({})创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典,下一节我们会介绍这个数据结构。
以下是一个简单的演示:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in either a or b
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in either a or b
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}
集合也支持推导式:
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
12.5 字典
另一个非常有用的 Python 内建数据类型是字典。
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}。这是一个字典运用的简单例子:
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'guido': 4127, 'irv': 4127, 'jack': 4098}
>>> list(tel.keys())
['irv', 'guido', 'jack']
>>> sorted(tel.keys())
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
>>> 'jack' not in tel
False
构造函数 dict() 直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
此外,字典推导可以用来创建任意键和值的表达式词典:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'jack': 4098, 'guido': 4127}
12.6 遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversesd() 函数:
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear
13. 模块
在前面的几个章节中我们脚本上是用python解释器来编程,如果你从Python解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用python标准库的方法。下面是一个使用python标准库中模块的例子。
#!/usr/bin/python3
# Filename: using_sys.py
import sys
print('命令行参数如下:')
for i in sys.argv:
print(i)
print('\n\nPython 路径为:', sys.path, '\n')
执行结果如下所示:
$ python using_sys.py 参数1 参数2
命令行参数如下:
using_sys.py
参数1
参数2
Python 路径为: ['/root', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
- 1、import sys引入python标准库中的sys.py模块;这是引入某一模块的方法。
- 2、sys.argv是一个包含命令行参数的列表。
- 3、sys.path包含了一个Python解释器自动查找所需模块的路径的列表。
13.1 import 语句
如果要使用Python源文件,只需在另一个源文件里执行import语句,import语句语法如下:
import module1[,module2[, ... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如果想要导入模块 support,需要把命令放在脚本的顶端:
#!/usr/bin/python3
# Filename: support.py
def print_func( par ):
print ("Hello : ", par)
return
test.py 引入 support 模块:
#!/usr/bin/python3
# Filename: test.py
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("w3cschool")
以上实例输出结果:
$ python3 test.py
Hello : w3cschool
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?
这就涉及到Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。
这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。
搜索路径是在Python编译或安装的时候确定的,安装新的库应该也会修改。搜索路径被存储在sys模块中的path变量,做一个简单的实验,在交互式解释器中,输入以下代码:
>>> import sys
>>> sys.path
['', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
>>>
sys.path输出是一个列表,其中第一项是空串’’,代表当前目录(若是从一个脚本中打印出来的话,可以更清楚地看出是哪个目录),亦即我们执行python解释器的目录(对于脚本的话就是运行的脚本所在的目录)。
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
了解了搜索路径的概念,就可以在脚本中修改sys.path来引入一些不在搜索路径中的模块。
13.2 name 属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
运行输出如下:
$ python using_name.py
程序自身在运行
$ python
>>> import using_name
我来自另一模块
>>>
13.3 dir()
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回。
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'sys', 't']
>>>
13.4 标准模块
Python 本身带着一些标准的模块库,在 Python 库参考文档中将会介绍到(就是后面的"库参考文档")。
有些模块直接被构建在解析器里,这些虽然不是一些语言内置的功能,但是他却能很高效的使用,甚至是系统级调用也没问题。
13.5 包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 init.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
14. 输入和输出
Python两种输出值的方式:表达式语句和 print() 函数。(第三种方式是使用文件对象的 write() 方法; 标准输出文件可以用 sys.stdout 引用。)
如果你希望输出的形式更加多样,可以使用 str.format() 函数来格式化输出值。
如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
str() 函数返回一个用户易读的表达形式。repr() 产生一个解释器易读的表达形式。
>>> s = 'Hello, world.'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'The value of x is ' + repr(x) + ', and y is ' + repr(y) + '...'
>>> print(s)
The value of x is 32.5, and y is 40000...
>>> # repr() 函数可以转义字符串中的特殊字符
... hello = 'hello, world\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, world\n'
>>> # repr() 的参数可以是 Python 的任何对象
... repr((x, y, ('spam', 'eggs')))
"(32.5, 40000, ('spam', 'eggs'))"
这里有两种方式输出一个平方与立方的表:
>>> for x in range(1, 11):
... print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
... # 注意前一行 'end' 的使用
... print(repr(x*x*x).rjust(4))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
>>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
14.1 读和写文件
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
实例:
>>> f = open('/tmp/workfile', 'w')
- 第一个参数为要打开的文件名。
- 第二个参数描述文件如何使用的字符。 mode 可以是 ‘r’ 如果文件只读, ‘w’ 只用于写 (如果存在同名文件则将被删除), 和 ‘a’ 用于追加文件内容; 所写的任何数据都会被自动增加到末尾. ‘r+’ 同时用于读写。 mode 参数是可选的; ‘r’ 将是默认值。
14.2 文件对象的方法
- f.read()
为了读取一个文件的内容,调用 f.read(size),这将读取一定数目的数据,然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负,那么该文件的所有内容都将被读取并且返回。
>>> f.read()
'This is the entire file.\n'
>>> f.read()
''
- f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
>>> f.readline()
'This is the first line of the file.\n'
>>> f.readline()
'Second line of the file\n'
>>> f.readline()
''
- f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
>>> f.readlines()
['This is the first line of the file.\n', 'Second line of the file\n']
- f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
>>> f.write('This is a test\n')
15
如果要写入一些不是字符串的东西, 那么将需要先进行转换:
>>> value = ('the answer', 42)
>>> s = str(value)
>>> f.write(s)
18
-
f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。 -
f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符;
- seek(x,1) : 表示从当前位置往后移动x个字符;
- seek(-x,2):表示从文件的结尾往前移动x个字符。
from_what 值为默认为0,即文件开头。下面给出一个完整的例子:
>>> f = open('/tmp/workfile', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # 移动到文件的第六个字节
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # 移动到文件的倒数第三字节
13
>>> f.read(1)
b'd'
- f.close()
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
14.3 pickle模块
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
- 基本接口:
pickle.dump(obj, file, [,protocol])
- 有了 pickle 这个对象, 就能对 file 以读取的形式打开:
x = pickle.load(file)
- 注解:从 file 中读取一个字符串,并将它重构为原来的python对象。
file: 类文件对象,有read()和readline()接口。
实例1:
#使用pickle模块将数据对象保存到文件
import pickle
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
实例2:
#使用pickle模块从文件中重构python对象
import pprint, pickle
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()
15. File 方法
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close() 关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next() 返回文件下一行。 |
| 6 | file.read([size]) 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size]) 读取整行,包括 “\n” 字符。 |
| 8 | file.readlines([sizehint]) 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比sizeint较大, 因为需要填充缓冲区。 |
| 9 | file.seek(offset[, whence]) 设置文件当前位置 |
| 10 | file.tell() 返回文件当前位置。 |
| 11 | file.truncate([size]) 截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 | file.write(str) 将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence) 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
16. OS 文件/目录方法
| 序号 | 方法及描述 |
|---|---|
| 1 | os.access(path, mode)检验权限模式 |
| 2 | os.chdir(path)改变当前工作目录 |
| 3 | os.chflags(path, flags)设置路径的标记为数字标记。 |
| 4 | os.chmod(path, mode)更改权限 |
| 5 | os.chown(path, uid, gid)更改文件所有者 |
| 6 | os.chroot(path)改变当前进程的根目录 |
| 7 | os.close(fd)关闭文件描述符 fd |
| 8 | os.closerange(fd_low, fd_high)关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| 9 | os.dup(fd)复制文件描述符 fd |
| 10 | os.dup2(fd, fd2)将一个文件描述符 fd 复制到另一个 fd2 |
| 11 | os.fchdir(fd)通过文件描述符改变当前工作目录 |
| 12 | os.fchmod(fd, mode)改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| 13 | os.fchown(fd, uid, gid)修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| 14 | os.fdatasync(fd)强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| 15 | os.fdopen(fd[, mode[, bufsize]])通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| 16 | os.fpathconf(fd, name)返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| 17 | os.fstat(fd)返回文件描述符fd的状态,像stat()。 |
| 18 | os.fstatvfs(fd)返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| 19 | os.fsync(fd)强制将文件描述符为fd的文件写入硬盘。 |
| 20 | os.ftruncate(fd, length)裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| 21 | os.getcwd()返回当前工作目录 |
| 22 | os.getcwdu()返回一个当前工作目录的Unicode对象 |
| 23 | os.isatty(fd)如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| 24 | os.lchflags(path, flags)设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| 25 | os.lchmod(path, mode)修改连接文件权限 |
| 26 | os.lchown(path, uid, gid)更改文件所有者,类似 chown,但是不追踪链接。 |
| 27 | os.link(src, dst)创建硬链接,名为参数 dst,指向参数 src |
| 28 | os.listdir(path)返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| 29 | os.lseek(fd, pos, how)设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| 30 | os.lstat(path)像stat(),但是没有软链接 |
| 31 | os.major(device)从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| 32 | os.makedev(major, minor)以major和minor设备号组成一个原始设备号 |
| 33 | os.makedirs(path[, mode])递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| 34 | os.minor(device)从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| 35 | os.mkdir(path[, mode])以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| 36 | os.mkfifo(path[, mode])创建命名管道,mode 为数字,默认为 0666 (八进制) |
| 37 | os.mknod(filename[, mode=0600, device])创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 |
| 38 | os.open(file, flags[, mode])打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| 39 | os.openpty()打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| 40 | os.pathconf(path, name)返回相关文件的系统配置信息。 |
| 41 | os.pipe()创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| 42 | os.popen(command[, mode[, bufsize]])从一个 command 打开一个管道 |
| 43 | os.read(fd, n)从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| 44 | os.readlink(path)返回软链接所指向的文件 |
| 45 | os.remove(path)删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| 46 | os.removedirs(path)递归删除目录。 |
| 47 | os.rename(src, dst)重命名文件或目录,从 src 到 dst |
| 48 | os.renames(old, new)递归地对目录进行更名,也可以对文件进行更名。 |
| 49 | os.rmdir(path)删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| 50 | os.stat(path)获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| 51 | os.stat_float_times([newvalue])决定stat_result是否以float对象显示时间戳 |
| 52 | os.statvfs(path)获取指定路径的文件系统统计信息 |
| 53 | os.symlink(src, dst)创建一个软链接 |
| 54 | os.tcgetpgrp(fd)返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
| 55 | os.tcsetpgrp(fd, pg)设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| 56 | os.tempnam([dir[, prefix]])返回唯一的路径名用于创建临时文件。 |
| 57 | os.tmpfile()返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| 58 | os.tmpnam()为创建一个临时文件返回一个唯一的路径 |
| 59 | os.ttyname(fd)返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| 60 | os.unlink(path)删除文件路径 |
| 61 | os.utime(path, times)返回指定的path文件的访问和修改的时间。 |
| 62 | os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]])输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| 63 | os.write(fd, str)写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
17. 错误和异常
Python有两种错误很容易辨认:语法错误和异常。
17.1 语法错误
Python 的语法错误或者称之为解析错,是初学者经常碰到的,如下实例
>>> while True print('Hello world')
File "" , line 1, in ?
while True print('Hello world')
^
SyntaxError: invalid syntax
这个例子中,函数 print() 被检查到有错误,是它前面缺少了一个冒号(:)。
语法分析器指出了出错的一行,并且在最先找到的错误的位置标记了一个小小的箭头。
17.2 异常
>>> 10 * (1/0)
Traceback (most recent call last):
File "" , line 1, in ?
ZeroDivisionError: division by zero
>>> 4 + spam*3
Traceback (most recent call last):
File "" , line 1, in ?
NameError: name 'spam' is not defined
>>> '2' + 2
Traceback (most recent call last):
File "" , line 1, in ?
TypeError: Can't convert 'int' object to str implicitly
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 ZeroDivisionError,NameError 和 TypeError。
错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
17.3 异常处理
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
>>> while True:
try:
x = int(input("Please enter a number: "))
break
except ValueError:
print("Oops! That was no valid number. Try again ")
try语句按照如下方式工作;
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的except子句将被执行。最后执行 try 语句之后的代码。
- 如果一个异常没有与任何的except匹配,那么这个异常将会传递给上层的try中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。处理程序将只针对对应的try子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
pass
最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raise
try except 语句还有一个可选的else子句,如果使用这个子句,那么必须放在所有的except子句之后。这个子句将在try子句没有发生任何异常的时候执行。例如:
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到的、而except又没有捕获的异常。
异常处理并不仅仅处理那些直接发生在try子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。例如:
>>> def this_fails():
x = 1/0
>>> try:
this_fails()
except ZeroDivisionError as err:
print('Handling run-time error:', err)
Handling run-time error: int division or modulo by zero
抛出异常
Python 使用 raise 语句抛出一个指定的异常。例如:
>>> raise NameError('HiThere')
Traceback (most recent call last):
File "" , line 1, in ?
NameError: HiThere
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>> try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "" , line 2, in ?
NameError: HiThere
用户自定义异常
你可以通过创建一个新的exception类来拥有自己的异常。异常应该继承自 Exception 类,或者直接继承,或者间接继承,例如:
>>> class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
>>> try:
raise MyError(2*2)
except MyError as e:
print('My exception occurred, value:', e.value)
My exception occurred, value: 4
>>> raise MyError('oops!')
Traceback (most recent call last):
File "" , line 1, in ?
__main__.MyError: 'oops!'
在这个例子中,类 Exception 默认的 init() 被覆盖。
异常的类可以像其他的类一样做任何事情,但是通常都会比较简单,只提供一些错误相关的属性,并且允许处理异常的代码方便的获取这些信息。
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
大多数的异常的名字都以"Error"结尾,就跟标准的异常命名一样。
18. 实例
Python Hello World 实例
Python 数字求和
Python 平方根
Python 二次方程
Python 计算三角形的面积
Python 随机数生成
Python 摄氏温度转华氏温度
Python 交换变量
Python if 语句
Python 判断字符串是否为数字
Python 判断奇数偶数
Python 判断闰年
Python 获取最大值函数
Python 质数判断
Python 阶乘实例
Python 九九乘法表
Python 斐波那契数列
Python 阿姆斯特朗数
Python 十进制转二进制、八进制、十六进制
Python ASCII码与字符相互转换
Python 最大公约数算法
Python 最小公倍数算法
Python 简单计算器实现
Python 生成日历
Python 使用递归斐波那契数列
Python 文件 IO
Python 字符串判断
Python 字符串大小写转换
Python 计算每个月天数
Python 获取昨天日期
Python list 常用操作
感兴趣可以访问:https://www.w3cschool.cn/python3/python3-examples.html
参考:
https://www.w3cschool.cn/python3/
https://www.w3school.com.cn/python/python_lambda.asp