用Python进行自然语言处理 - 语言处理与Python
最近在看《Analyzing Text with the Natural Language Toolkit》的中文翻译版本,觉得蛮有意思的,就把学习过程中的遇到的问题和一些代码的运行结果记录下来。小白一只,如有错误,请您指正,谢谢!
想要这本书资源的可以在评论区留下您的邮箱。
下面进入正题(之前我已经装好了Python3.6版本):
第1章 语言处理与Python
1.1 语言计算:文本和单词
-
NLTK入门
由于pip版本太老,先右键管理员身份打开cmd,根据提示输入 python -m pip install --upgrade pip 语句进行pip的更新。
更新完毕,输入 pip install nltk 语句进行NLTK的安装。
安装完毕,启动Python解释器。在Python提示符后输入以下命令:
>>>import nltk
>>>nltk.download()
跳出以下界面:
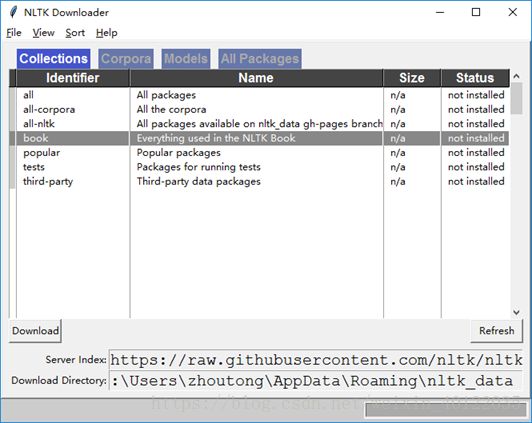
选中“book”这一行,点击“Download”。完成后,出现如下界面:
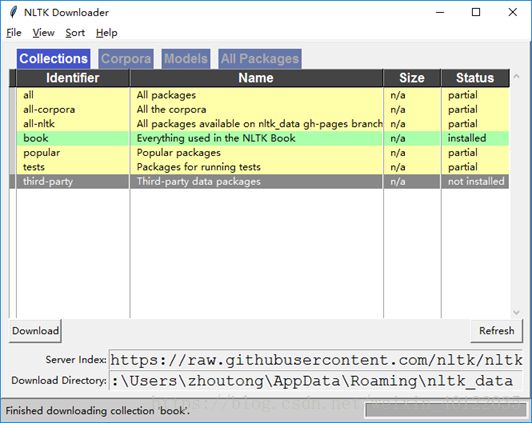
关闭窗口。此时数据已经被下载到电脑上啦,你可以使用Python解释器去加载一些要用的文本。
首先输入 from nltk.book import * ,即从NLTK的book模块加载all。

若想找到这些文本,只需在>>>后输入它们的名字即可。如:

-
搜索文本
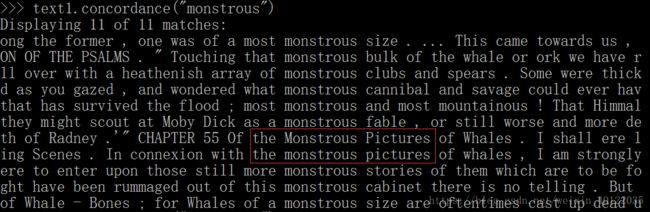
text1.concordance("monstrous") 即搜索《白鲸记》中的词monstrous:

text2.concordance("affection") 即搜索《理智与情感》中的词affection:

通过上述的词语索引,我们可以看到其上下文。如text1中的monstrous,我们可以看到 the_____pictures (见下图红框):
可以通过 文本名.similar("关键词”) 语句来查看还有哪些词出现在相似的上下文中。

common_contexts函数可以研究两个及以上的词的共同的上下文,如monstrous 和 very。
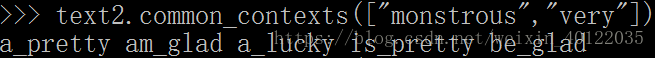
-
判断词在文本中的位置
从文本开头算起在它前面有多少个词,位置信息可以用离散图表示。图中,每一个竖线代表一个单词,每一行代表整个文本。PS:为了画图,我们需要安装Python的NumPy的Matplotlib包。如果没有安装,就会出现如下错误:
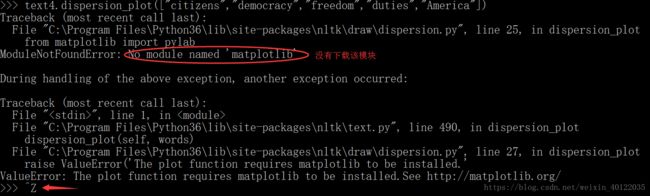
通过Ctrl+Z 退出Python 解释器,然后通过 pip install matplotlib 语句进行下载安装。

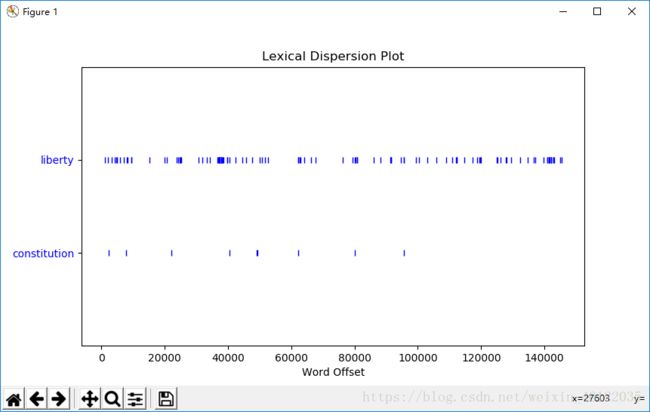
安装之后,进入Python解释器,记得导入nltk book模块的所有文本。然后输入如下语句(见黄框):

然后弹出一张图:

关闭图片窗口后,输入另一条语句:
![]()
弹出如下图片:
-
generate函数
不再适用,暂时没有替代的函数。如果有,希望哪位大佬可以告知。
-
计数词汇
使用len函数获取长度。(以文本中出现的词和标点符号为单位算出文本从头到尾的长度。)

使用set函数获得词汇表。
使用sorted(set(文本名称))得到一个词汇项的排序表

再用len来获得这个数值。

对文本词汇丰富度进行测量(需确保Python使用的是浮点除法):
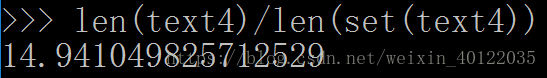
计数一个词在文本中出现的次数,计算一个特定的词在文本中占据的百分比。

-
定义函数
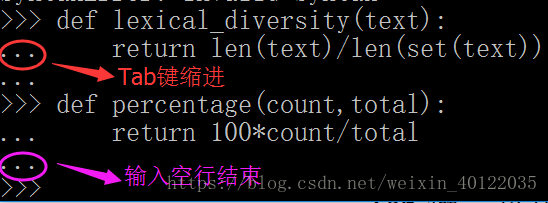
用关键字def定义新函数:
使用这些函数:

1.8 练习
1、尝试使用 Python 解释器作为一个计算器,输入表达式,如 12/(4+1)。
![]()
2、26 个字母可以组成 26 的 10 次方或者 26**10 个 10 字母长的字符串。也就是 1411 67095653376L(结尾处的 L 只是表示这是 Python 长数字格式)。100 个字母长度的 字符串可能有多少个?
![]()
3、Python 乘法运算可应用于链表。当你输入['Monty', 'Python'] * 20 或者 3 * sent1 会发生什么?

![]()
4、复习 1.1 节关于语言计算的内容。在 text2 中有多少个词?有多少个不同的词?

5、比较表格 1-1 中幽默和言情小说的词汇多样性得分,哪一个文体中词汇更丰富?

言情小说的词汇更丰富。
6、制作《理智与情感》中四个主角:Elinor,Marianne,Edward 和 Willoughby 的分布图。 在这部小说中关于男性和女性所扮演的不同角色,你能观察到什么?你能找出一对夫妻 吗?

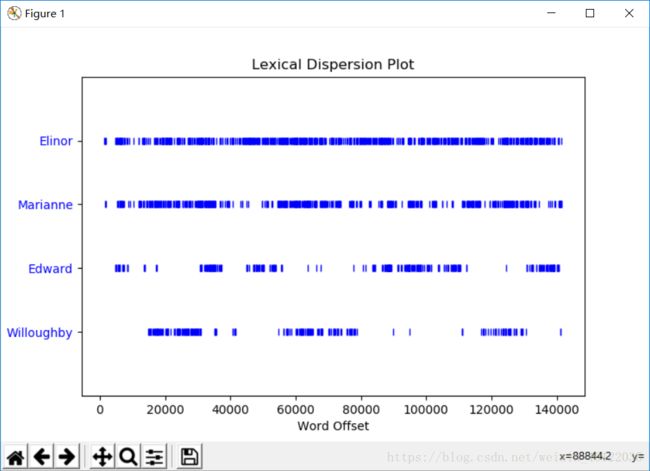
可以看出Elinor和Marianne出现的频率很高,且近乎贯穿全文,所以我认为两者是主角。
个人原以为Elinor和Marianne是cp,但参考百度之后,发现她俩是姐妹关系,Elinor和Edward才是cp。(我猜是我忽视了性别,前两位是女,后两位是男。如果有大佬知道怎么从图上看出来的请告诉我)附上剧情简介。

7、查找 text5 中的搭配

8、思考下面的 Python 表达式:len(set(text4))。说明这个表达式的用途。描述在执行 此计算中涉及的两个步骤。
这个表达式的用途是统计text4文本中有多少个不同的标识符。
此计算涉及两个步骤,一是获得text4的词汇表,二是求取词汇表的长度
9、复习 1.2 节关于链表和字符串的内容。
a. 定义一个字符串,并且将它分配给一个变量,如:my_string = 'My String'(在字符串中放一些更有趣的东西)。用两种方法输出这个变量的内容,一种是通过简 单地输入变量的名称,然后按回车;另一种是通过使用 print 语句。

b. 尝试使用 my_string+ my_string 或者用它乘以一个数将字符串添加到它自身, 例如:my_string* 3。请注意,连接在一起的字符串之间没有空格。怎样能解决这个问题?
![]()
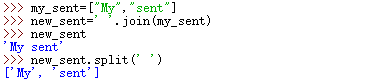
10、使用的语法 my_sent=["My", "sent"],定义一个词链表变量 my_sent(用你自己的词或喜欢的话)。
a. 使用' '.join(my_sent)将其转换成一个字符串。
b. 使用 split()在你指定的地方将字符串分割回链表。
11、定义几个包含词链表的变量,例如:phrase1,phrase2 等。将它们连接在一起组成不同的组合(使用加法运算符),最终形成完整的句子。len(phrase1 + phrase2) 与 len(phrase1) + len(phrase2)之间的关系是什么?

len(phrase1 + phrase2) = len(phrase1) + len(phrase2)
12、考虑下面两个具有相同值的表达式。哪一个在 NLP 中更常用?为什么?
a. "Monty Python"[6:12]
b. ["Monty", "Python"][1]
b在NLP中更常用,因为NLP的操作是基于词汇的。
13、我们已经看到如何用词链表表示一个句子,其中每个词是一个字符序列。sent1[2][2] 代表什么意思?为什么?请用其他的索引值做实验。
sent1[2][2]代表text1文本第一句的第三个词汇的第三个字符,即‘‘h’’

sent5[3][4] 代表text5文本的第一句话的第四个词汇的第五个字符,即“l”

14、 在变量 sent3 中保存的是 text3 的第一句话。在 sent3 中 the 的索引值是 1,因为 sent3[1]的值是“the”。sent3 中“the”的其它出现的索引值是多少?

15、复习1.4节讨论的条件语句。在聊天语料库(text5)中查找所有以字母 b 开头的词。 按字母顺序显示出来。

16、 在Python解释器提示符下输入表达式 range(10)。再尝试 range(10, 20), range (10, 20, 2)和 range(20, 10, -2)。在后续章节中我们将看到这个内置函数的多用用途。



17、使用 text9.index()查找词 sunset 的索引值。你需要将这个词作为一个参数插入到圆括号之间。通过尝试和出错的过程中,找到完整的句子中包含这个词的切片。
![]()
18、 使用链表加法、set 和 sorted 操作,计算句子 sent1...sent8 的词汇表。
![]()
19、 下面两行之间的差异是什么?哪一个的值比较大?其他文本也是同样情况吗?
>>> sorted(set([w.lower() for w in text1]))
>>> sorted([w.lower() for w in set(text1)]

后者的值较大,因为后者还包含一些大小写不同的单词。
20、w.isupper()和 not w.islower()这两个测试之间的差异是什么?
前者是测试w中所有字符是否都是大写字母
后者是测试w中的所有字符是否不都是小写字母,即判断是否是大小写掺杂或者全是大写。

21、写一个切片表达式提取 text2 中最后两个词。
![]()
22、 找出聊天语料库(text5)中所有四个字母的词。使用频率分布函数(FreqDist), 以频率从高到低显示这些词。
![]()
23、复习 1.4 节中条件循环的讨论。使用 for 和 if 语句组合循环遍历《巨蟒和圣杯》(text6)的电影剧本中的词,输出所有的大写词,每行输出一个。

24、写表达式找出 text6 中所有符合下列条件的词。结果应该是词链表的形式:['word 1', 'word2', ...]。
a. 以 ize 结尾
b. 包含字母 z
c. 包含字母序列 pt
d. 除了首字母外是全部小写字母的词(即 titlecase)

25、定义 sent 为词链表['she', 'sells', 'sea', 'shells', 'by', 'the', 'sea', 'shore']。 编写代码执行以下任务:
a. 输出所有 sh 开头的单词
b. 输出所有长度超过 4 个字符的词

26、下面的 Python 代码是做什么的?sum([len(w) for w in text1]),你可以用它来 算出一个文本的平均字长吗?
该代码是用来求文本中所有的字长总和。
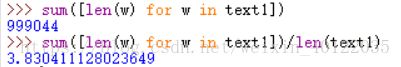
27、定义一个名为 vocab_size(text)的函数,以文本作为唯一的参数,返回文本的词汇量。

28、定义一个函数 percent(word, text),计算一个给定的词在文本中出现的频率,结果以百分比表示。

29、我们一直在使用集合存储词汇表。试试下面的 Python 表达式:set(sent3) < set(text1)。
实验在 set()中使用不同的参数。它是做什么用的?你能想到一个实际的应用吗?
sent3的词汇集合属于text1的词汇集合。
set(a)