爬虫随笔(1):Spyder(Python 2.7)环境搭建 & 爬虫初体(ru)验(keng)
一、前言
今天说起大数据已经不陌生了,而做大数据分析的第一步就是拿到大量的数据。一般企业自己积累的数据不会很多,也不一定有价值。所以,万维网作为大量信息的载体,自然成了一个理想渠道。关于网络爬虫,百度百科的介绍是这样的:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 ——引用自百度百科
说来也巧,百度本身就是爬虫起家的公司,而它的前辈就是赫赫有名的谷歌搜索引擎。谷歌的创始人可以说是第一个做到数据赚钱的人了。笔者也是个本科在读小白,这个月偶然参与到一个训练营,写些记录。
二、爬虫环境搭建
首先,我们选取Anaconda来开启爬虫之旅,为什么呢?
因为Anaconda是一个开源的Python发行版本,包含180多个科学包及其依赖项。
Python本身是一门严重依赖依赖的语言,如果你在学习之初没有很好的规划,后面可能会有点乱(版本、包)。
笔者是这样的:前期安装Anaconda2.7版本,各种环境和包配置在其自带的Python27上,后面转用pycharm可以选择继续使用这套环境,只要导入就行了。
好的,那么首先是Anaconda的安装。
###安装Anaconda
首先,根据系统情况下载对应的anaconda:
清华镜像:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
南方科大镜像:http://mirrors.sustc.us/
官网:https://www.anaconda.com/download/
Python2.7下载anaconda2-5.0以上版本
接下来安装过程中,注意以下几点:
- Advanced Options中两项都要勾选,将anaconda加入到系统环境变量中,并把当前anaconda作为系统默认Python环境。
- 跳过vscode的安装
- 安装完成后,在Windows的窗口中搜索anaconda,打开anaconda navigator,进入anaconda
- 如果打开导航后无法进入anaconda界面,则检查电脑中是否安装visual c++ redistributable;如果未安装,需安装visual c++ Redistributable。
- Visual Redistributable c++ 2015下载地址
接下来,只要进入anaconda navigator后点击启动Spyder就可以开始编程啦。
还有一步设置anaconda国内镜像的,在CMD执行
# 添加Anaconda的TUNA镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
###安装爬虫需要的包
在命令行窗口执行:
> pip install requests
> pip install scrapy
> pip install beautifulsoup
三、实现访问网站
大多数人有这样一条必由之路:某天突然踏入爬虫的领域,没有学院式的指导,你开始试着用Resquests库勉强开发了一个能跑得动的爬虫:访问网站,下载源码,挣扎在BeautifulSoup中,提取数据,拙劣的反爬手段……第一次写的程序跑起来很慢,也有很多细节没处理好,于是你让它整夜地跑,最终大部分数据拿到手了。而下一次,当你对爬虫的工作流程非常熟练了,你会直奔Scrapy——优雅的框架,这是后话了。
如果没接触过前端开发,那你可能要去补一下知识。我也没系统接触过前端Web,但对于网络连接的基础知识还是能理解。事实上爬虫也就是用机器模拟人的行为去访问网站而已,而我们编写程序需要做的也就是根据Web编写的规律去有效的抓取我们需要的东西。所以我们至少要知道访问网站的时候发生了什么。
###request和response
关于response的介绍 在CSDN上已经有了介绍。当web服务器收到客户端的http请求,会针对每一次请求,分别创建一个用于代表请求的request对象、和代表响应的response对象。也许说到这里还是有点迷,那我们先来看一下代码。
###requests模块
说明一下,我使用的是python2.7。首先安装好requests这个模块:CMD下pip install requests。接下来,我们随便选择一个网站来抓取咨询,我这里用的是
CSDN的网站主页:https://www.csdn.net/
东方财富网的某个新闻页面:http://finance.eastmoney.com/news/cywjh.html
安装完requests包后,我们先看一下源码,了解一下这个模块
"""
Requests HTTP Library
~~~~~~~~~~~~~~~~~~~~~
Requests is an HTTP library, written in Python, for human beings. Basic GET
usage:
>>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True
... or POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('http://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
"""
这里告诉我们,这个包是一个HTTP Library,我们可以用它来连接某个网站的url进而获取数据。并且给出了使用方法,所以我么你可以很简单写出:
# -*- coding: utf-8 -*-
import requests
req=requests.get('https://www.csdn.net')
简单的一行代码,如果你在命令行输入req查看这个req的内容,你会得到req.+Tab查看。例如输入req.content 就会输出该页面的全部源代码。
四、解析源码、获取内容
前面我们已经把整个页面的源码都拿下来,那么接下来我么你需要解析一下这个源码,寻找我们想要的内容对应的web标签在哪个地方。首先页面的内容分为HTML ,JavaScript,CSS,首先我们先用DOM树解析法把源码根据标签来划分树,接下来观察前端开发编码的规则来进行定位。
首先我们需要说明一下网页的源码、标签分别是什么。打开一个浏览器(以谷歌浏览器为例),按下F12键便可以查看网页源码;右键点击网页上任意版块并选择检查,源码中对应的代码块就会高亮显示。每个标签的属性有:id、class、text、interhtml
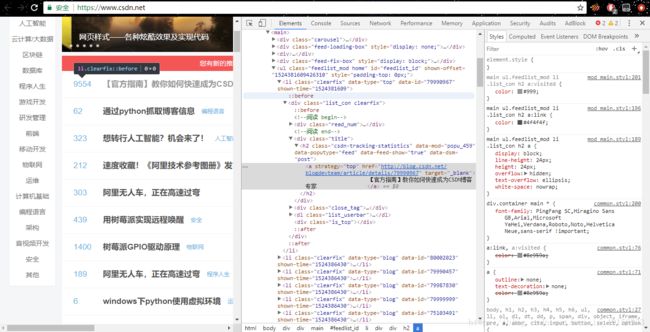
观察源码不难看出,源码中存在很多的、、 ,分别是万能标签、段落标签、超链接。移动鼠标停在不同的代码段上,就能看出其规律。
如果你觉得上述的网页内容太复杂了,没关系,试试这个网页:http://example.com/
###解析源码
根据前面的思路,我们现在来解析这个源码。首先需要安装一个包pip install BeautifulSoup ,接下来一样的查看BeautifulSoup这个包的源码+说明文档。
Beautiful Soup uses a pluggable XML or HTML parser to parse a (possibly invalid) document into a tree representation. Beautiful Soup provides methods and Pythonic idioms that make it easy to navigate,search, and modify the parse tree.
可以知道,这个包的功能就是使用解析器来解析文档到树结构中。根据说明文档我们可以写出如下代码来建立这个解析树:
from bs4 import BeautifulSoup
bs=BeautifulSoup(req.content,'html.parser')
依旧是简单的一行代码,就将这个树建立好了,接下来我们可以用这个包的方法从树上根据我们需要的标签特点来定位到相关的代码块。
###定位所需内容的标签
还是上面那张网页源码的截图,可以发现每一条
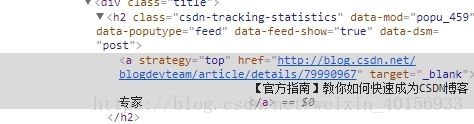
对比其它标题你会发现,每一个li 标签中 之外的结构和内容基本是一样的,也就是说每个标题的信息就包含在这个代码块中。发现了这个规律后,我们只要通过这个标签的属性把所有h2 标签的代码块都从树上拿出来,就可以来获取标题的内容了。
h2_title=bs.find_all('h2',attrs={'class':'csdn-tracking-statistics'})
此时你输出h2_title时,则会显示到相应的代码块了。但是到这一步你还是无法获取到标题的文字内容。想一下,如果你平时自己操作的话,要怎么做?一般都是点击进去,然后把页面的标题复制下来。所以同样的道理,我们要进入该链接继续解析。
###获取内容
执行如下代码,便可以获取到所有标题内容啦,循环体里面做的事跟上面的原理是完全一样的。
for info in h2_title:
url=info.a.get('href') #获取链接
req=requests.get(url) #对该网址发出请求连接
bs1=BeautifulSoup(req.content,'html.parser') #以html解释方式建立DOM树
title=bs1.find('h1') #寻找标题对应的代码块
h1_all=bs1.find_all('h1',attrs={'class':'csdn_top'})
print title #显示每一个标题
下面给出另一个网页的解析代码和执行结果,可以对比着看,很容易模仿。
import requests
from bs4 import BeautifulSoup
req=requests.get('http://finance.eastmoney.com/news/cywjh.html')
bs=BeautifulSoup(req.content,'html.parser')
p_title=bs.find_all('p',attrs={'class':'title'})
for info in p_title:
url=info.a.get('href')
req=requests.get(url)
bs1=BeautifulSoup(req.content,'html.parser')
title=bs1.find('h1')
p_all=bs1.find_all('p')
print title

下面直接分享刚开始学的时候写的一个抓取CSDN主页更新文章的程序:
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 22 15:34:49 2018
@author: mfw
"""
import requests
import codecs
from bs4 import BeautifulSoup
f = codecs.open('csdn.txt', 'w', 'utf-8')
# 这个方法用来将infomation写入文件
def showtitle(url):
# 发出请求得到返回对象,如果req.status_code是200,说明访问成功
req = requests.get(url)
# 将网页的源码以HTML模式建立节点树,以便我们在树上寻找元素
bs = BeautifulSoup(req.content, 'html.parser')
# find_all()方法可以找出所有的li标签,因为文章的链接等信息就藏在这里
li_title = bs.find_all('li', {'class': 'blog-unit'})
# 从li标签中获取href即文章链接,再发送请求获取文章正文
for info in li_title:
url = info.a.get('href')
req = requests.get(url)
bs1 = BeautifulSoup(req.content, 'html.parser')
title = bs1.find('h1')
text = title.text+u'\n'
f.write(text)
# f.close()
return bs
# start
# 研究csdn主页新闻可发现其页面URL是由规律的,第一页是xxx,第二页就是xxx/list/2
# 所以我们可以通过这种方式来生成一系列页面的URL序列
URL = 'https://blog.csdn.net/blogdevteam'
BS = showtitle(URL)
for i in range(2, 28):
u = 'https://blog.csdn.net/blogdevteam/article/list/'+str(i)
b = showtitle(u)
print("The progress of the crawler:"+str(i*100/27)+'%')
print "Done!"
程序跑了之后的效果:
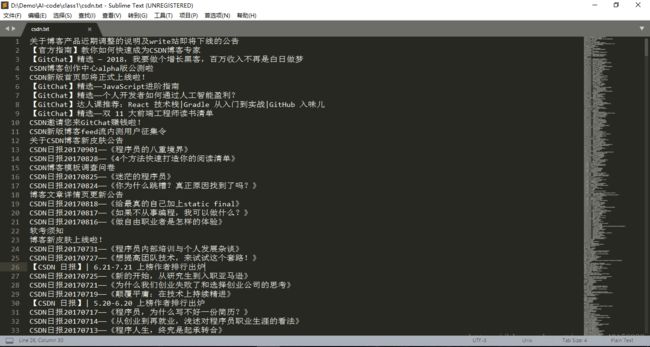
当时翻页还是利用URL的规律手动构建每一页的URL去访问,不想后头深入学习的时候还遇到另外一些很恶心的翻页方式。例如有一些是利用网站参数请求页面,这时有一下几种操作:
# 1 get请求带参数
req = requests.get(url, params={'pn': 1, 'xx': xx, ...})
# 2 post请求发送表单数据
req = requests.post(url, data = {'xx': xx, ...})
# 3 post请求发送json格式
import json
req = requests.post(url, data = json.dumps({'xx': xx, ...}))
# 4 直接利用post请求方法的json参数
url = 'https://www.xxx.com/api/user/login'
data = {'ua': '123456', 'pw': '123456', 'xx': 'xx', ...}
req = requests.post(url, json=data)
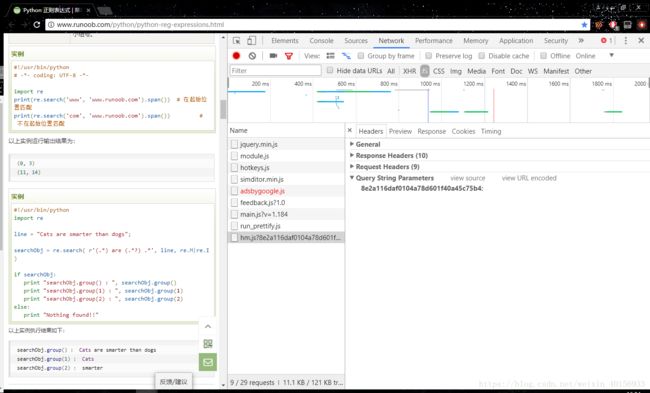
而具体要传哪些参数呢?可以在谷歌浏览器右键检查的Network中的请求参数寻找Headers下的Query String Parameters中查看。笔者只是爬新闻的,这一块其实基本很少使用。
五、伪装浏览器
爬虫确实是一种能高效收集数据的技术,然而有些网站并不希望自己的数据太容易被获取,所以自爬虫诞生之日就有了反爬虫,接下去又有了反反爬虫。。。见过最凶的反爬虫是蜜罐,网站源码中会加入一些误导机器的隐形标签,对人不可见,但对机器就很容易中套,一旦入罐直接封杀ip。当然最有效的反爬虫还是验证码!
那么为了降低被反爬虫的风险,我们可以让电脑伪装成一个浏览器,模仿浏览器的行为,而这个过程中最重要的就是User-Agent的使用。所谓User-Agent也就是用户代理,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。实现代码如下:
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
import random
url='http://www.whatyouwant.net'
headers={'User-Agent':random.choice(USER_AGENTS)}
req=requests.get(url,headers=headers)
至于伪装ip的,需要使用高匿性且稳定的ip代理,要求较高,反而会降低速度。一般的ip代理可以在西池代理网站上找,以下是一个批量获取的代码:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup as BS
def get_web_ips(num,crawl_url): # 参数为想要获取的ip数和测试ip
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0)Gecko/20100101 Firefox/43.0'
headers={'User-Agent':User_Agent}
counter=0
useful_ips=[]
for i in range(1,10):
# 从西池代理网站爬取ip列表
url='http://www.xicidaili.com/nn/'+str(i)
req=requests.get(url,headers=headers)
req.encoding=req.apparent_encoding
bs=BS(req.content,'html.parser')
trs=bs.find_all('tr')
ips=[]
for i in range(1,len(trs)):
ip=trs[i]
tds=ip.find_all('td')
http=tds[5].text
http=str(http).lower()
ip_str=http+'://'+tds[1].text+':'+tds[2].text
ip_str=str(ip_str)
ips.append({'ip':ip_str})
# 测试ip是否可用
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko'}
for proxies in ips:
try :
req=requests.get(crawl_url,headers=headers,proxies=proxies)
if req.status_code==200:
counter=counter+1
useful_ips.append(proxies)
print ('get ',counter)
if counter==num:
return useful_ips
except Exception as e:
print('unuseful')
def get_txt_ips(file_name):
with open(file_name,'r') as f:
lines=f.readlines()
lines=[line.strip() for line in lines]
#print ('get ips num ',len(lines))
ips=[]
for line in lines:
ip=eval(line)
ips.append(ip)
return ips
if __name__=='__main__':
crawl_url='http://www.baidu.com' # 用于测试的url
ips=get_web_ips(100,crawl_url)
with open('fake_ips_100.txt','w') as f:
for line in ips:
f.write(str(line)+'\n')
至于ip代理的使用很简单,如下:
url = ''
ip = '[从某渠道获取的ip]'
html = requests.get(url,proxies=ip)
Requests主要是在入门,后面更多时候使用商业框架,不过网页获取以及检查定位这个能力却是重要的基础功。后面不管你框架搭得多厉害,一个有用的爬虫永远需要做一些必要的搬砖工作,也就是页面检索定位。