利用Python进行数据分析——第8章绘图及可视化——学习笔记Python3 5.0.0
matplotlib API 入门
matplotlib API 函数(如plot和close)都位于matplotlib.pyplot模块中,通常的引入方式如下:
import matplotlib.pyplot as pltFigure和Subplot
matplotlib的图像都位于Figure对象中。可以用plt.figure创建一个新的Figure.
fig=plt.figure()这时会弹出一个空窗口。当Spyder不能弹出一个空窗口时,选择Spyder的tools下拉菜单preferences,选择IPython console窗口中Graphics,将Backend从Inline改成Qt5,注意:应用后,要重启Spyder
plt.figure有一些选项,特别是figsize,它用于确保当图片保存到磁盘时具有一定的大小和纵横比。
不能通过空Figure绘图。必须用add_subplot创建一个(add_subplot(1,1,1))或多个subplot才行。
ax1=fig.add_subplot(2,2,1)#图像是2x2的,当前选中的是4个subplot中的第一个(编号从1开始)
ax2=fig.add_subplot(2,2,2)
ax3=fig.add_subplot(2,2,3)
#这段代码需要在fig=plt.figure()的基础上绘制图像,也就是说不要把fig=plt.figure()创建的空窗口关闭
如果这时发出一条绘图命令(如plt.plot([1.5,3.5,-2,1.6])),matplotlib就会在最后一个用过的subplot上进行绘制。
from numpy.random import randn
plt.plot(randn(50).cumsum(),'k--')#“k--”是一个线型选项,用于告诉matplotlib绘制黑色虚线图
#为当前图像或最后一个使用的subplot对象绘制,所以图出现在第3个subplot中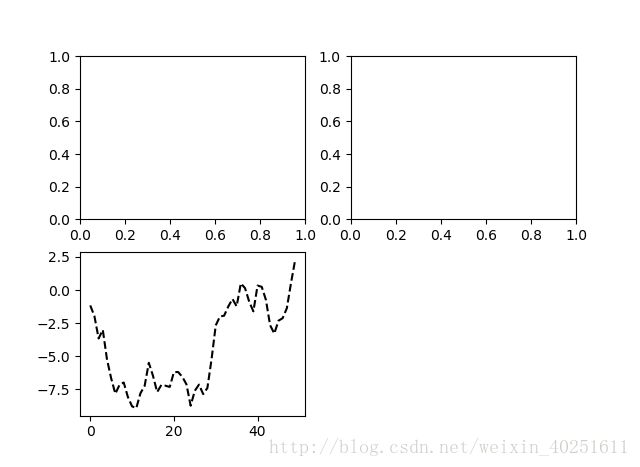
上面那些由fig.add_subplot所返回的对象是AxesSubplot对象
_=ax1.hist(randn(100),bins=20,color='k',alpha=0.3)
ax2.scatter(np.arange(30),np.arange(30)+3*randn(30))#指定某个图像对象,进行绘制
plt.subplot方法可以创建一个新的Figure,并返回一个含有已创建的subplot对象的NumPy数组
fig,axes=plt.subplots(2,3)
In [6]: axes #这个和书上的返回结果不同
Out[6]:
array([[,
,
],
[,
,
]], dtype=object) 
可以像对二维数组一样,对axes数组进行索引,例如axes[0,1],代表第1行第2个axes对象.可以通过sharex和sharey指定subplot应该具有相同的X轴或Y轴。

调整subplot周围的间距
默认情况下,matplotlib会在subplot外围留下一定的边距,并在subplot之间留下一定的间距。间距和图像的高度和宽度有关。利用Figure的subplots_adjust方法可以修改间距。
subplots_adjust(left=None,bottom=None,right=None,wspace=None,hspace=None)wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距。
fig,axes=plt.subplots(2,2,sharex=True,sharey=True)#产生两行两列共4个空白子图
for i in range(2):
for j in range(2):
axes[i,j].hist(randn(500),bins=50,color='k',alpha=0.5)
plt.subplots_adjust(wspace=0,hspace=0)#各subplot之间没有间距,且标签重叠了
颜色、标记和线型
matplotlib的plot函数接受一组X和Y坐标,还可以接受一个表示颜色和线型的字符串缩写。例如,要根据x和y绘制绿色虚线。
ax.plot(x,y,'g--') #这里的ax表示某个图像对象,比如上文的as1,as2,as3ax.plot(x,y,linestyle='--',color='g') #linestyle用于指明线型这个网址给出了颜色https://stackoverflow.com/questions/22408237/named-colors-in-matplotlib
b: blue #蓝色
g: green #绿色
r: red #红色
c: cyan #青色
m: magenta #洋红或紫红
y: yellow #黄色
k: black #黑色
w: white #白色plt.plot(randn(30).cumsum(),'ko--')
plt.plot(randn(30).cumsum(),color='k',linestyle='dashed',marker='o') #dashed表示虚线,两种表达方式意思相同
标记可以参考https://stackoverflow.com/questions/8409095/matplotlib-set-markers-for-individual-points-on-a-line
data=randn(30).cumsum()
fig,axes=plt.subplots(3,3)
axes[0,0].plot(data,'g+-')#绿色的+形
axes[0,1].plot(data,'c*-')#青色的*形
axes[0,2].plot(data,'ms-')#洋红色的正方形
axes[1,0].plot(data,'rh--')#红色的六边形
axes[1,1].plot(data,'kD--')#黑色的菱形
axes[1,2].plot(data,'b^--')#蓝色的一角向上三角形
axes[2,0].plot(data,'y<:')#黄色的一角向左三角形,所以>表示一角向右三角形
axes[2,1].plot(data,color='#800080',linestyle=':',marker='x') #purple紫色的x形
axes[2,2].plot(data,color='#FF8C00',linestyle='-.',marker='o')#darkorange深橘色的圆形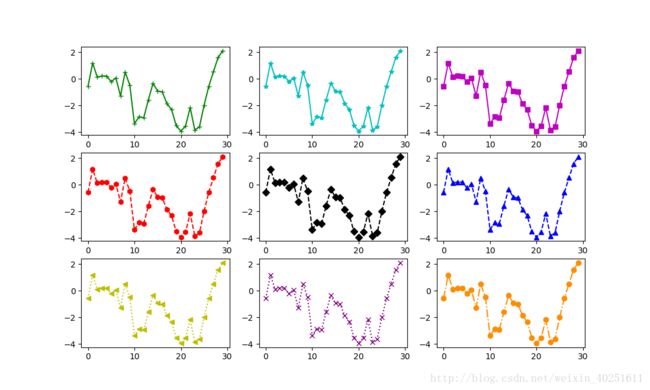
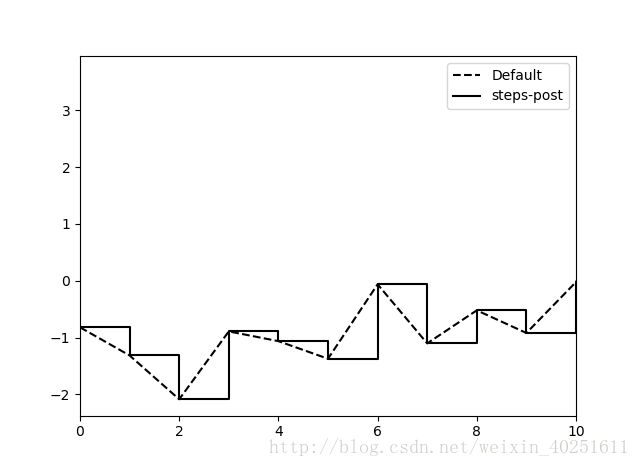
在线型图中,非实际数据点默认是按线性方式插值的。可以通过drawstyle选项修改。
data=randn(30).cumsum()
plt.plot(data,'k--',label='Default')
plt.plot(data,'k-',drawstyle='steps-post',label='steps-post')
plt.legend(loc='best')#放置图例,最佳(best)位置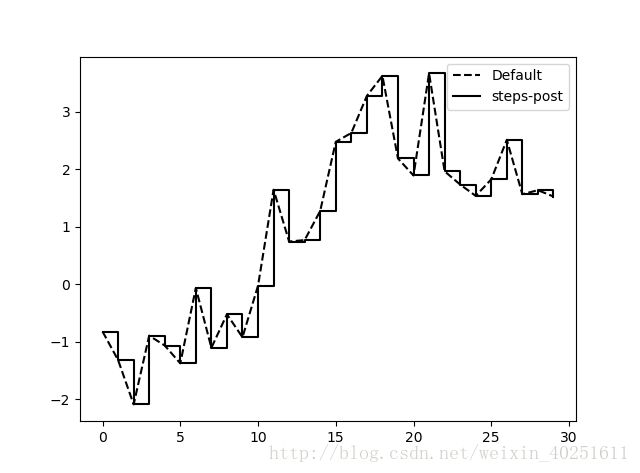
刻度、标签和图例
pyplot接口的设计目的就是交互式使用,含有诸如xlim、xticks和xticklabels之类的方法。分别控制图表的范围、刻度位置、刻度标签等。其使用方式有以下两种:
- 调用时不带参数,则返回当前的参数值。例如plt.xlim()返回当前X轴绘图范围
- 调用时带参数,则设置参数值。因此plt.xlim([0,10])会将X轴的范围设置为0到10
In [22]: plt.xlim()
Out[22]: (-1.4500000000000002, 30.449999999999999)
In [23]: plt.xlim([0,10])
Out[23]: (0, 10)
所有这些方法都是对当前或最近创建的AxesSubplot起作用。它们各自对应subplot对象上的两种方法,以xlim为例,就是ax.get_xlim和ax.set_xlim。
设置标题、轴标签、刻度、以及刻度标签
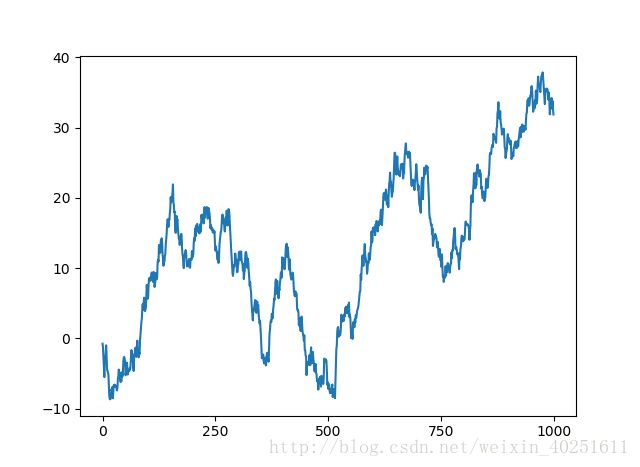
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(randn(1000).cumsum())
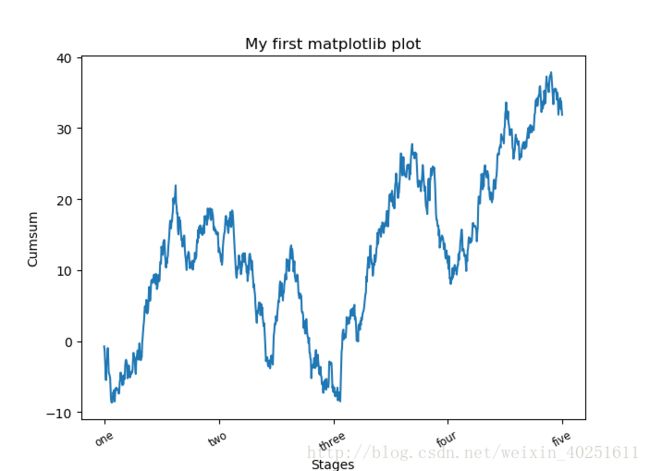
要修改X轴的刻度,最简单的办法是使用set_xticks和set_xticklabels。前者告诉matplotlib要将刻度放在数据范围中的哪些位置,默认情况下,这些位置也就是刻度标签。也可以通过 set_xticklabels设置其他标签。
ticks=ax.set_xticks([0,250,500,750,1000]) #标签的位置。默认情况下,这些数字就是标签
labels=ax.set_xticklabels(['one','two','three','four','five']) #在上面的位置上,增添标签
labels=ax.set_xticklabels(['one','two','three','four','five'],rotation=30,fontsize='small')#rotation旋转角度
ax.set_title('My first matplotlib plot')#设置标题
ax.set_xlabel('Stages')#设置X轴标签
ax.set_ylabel('Cumsum')#设置Y轴标签

添加图例
图例(legend)是另一种用于标识图表元素的重要工具。最简单的是在添加subplot的时候传入label参数,然后可以调用ax.legend()或plt.legend()来自动创建图例。
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(randn(1000).cumsum(),'k',label='one')
ax.plot(randn(1000).cumsum(),'k--',label='two')
ax.plot(randn(1000).cumsum(),'k.',label='three')
ax.legend(loc='best')
loc告诉matplotlib要将图例放在哪,'best'表示一个合适的位置。要从图例中去除一个或多个元素,不传入label或传入label='_nolegend_'即可
注解以及在Subplot上绘图
注解可以通过text、arrow和annotate等函数进行添加。text可以将文本绘制在图表的指定坐标(x, y),还可以加上自定义的格式。
ax.text(x,y,'Hello world!',family='monospace',fontsize=10)
注释中可以既含有文本又含有箭头。在annotate函数中,xy=(x, y)表示被注释的地方,也就是箭头指向的位置;xytext=(x, y)表示插入文本的地方,也就是注释内容显示的起始位置;label表示添加的内容,如‘peak of the market’;arrowprops用来设置箭头,facecolor设置箭头的颜色,headlength箭头的宽度,width箭身的宽度。
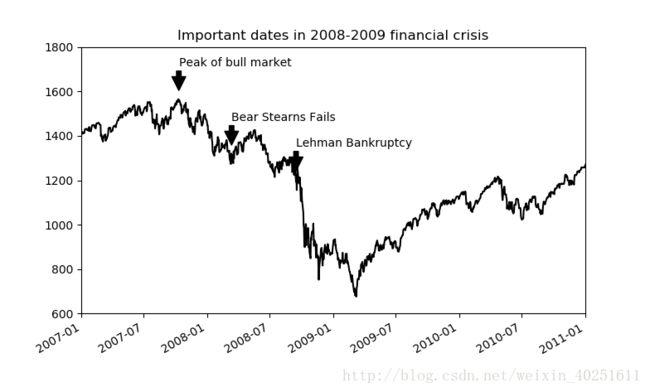
from datetime import datetime
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
data=pd.read_csv('spx.csv',index_col=0,parse_dates=True)
spx=data['SPX']
spx.plot(ax=ax,style='k-')
crisis_data=[(datetime(2007,10,11),'Peak of bull market'),
(datetime(2008,3,12),'Bear Stearns Fails'),
(datetime(2008,9,15),'Lehman Bankruptcy')]
for date,label in crisis_data:
ax.annotate(label,xy=(date,spx.asof(date)+50),xytext=(date,spx.asof(date)+200),
arrowprops=dict(facecolor='black'),horizontalalignment='left',verticalalignment='top')
ax.set_xlim(['1/1/2007','1/1/2011'])#放大到2007-2010
ax.set_ylim([600,1800])
ax.set_title('Important dates in 2008-2009 financial crisis')
图形的绘制。matplotlib有一些表示常见图形的对象。这些对象被称为块(patch)。其中有些可以在matplotlib.pyplot中找到(如Rectangle和Circle),但完整集合位于matplotlib.patches。
要在图表中添加一个图形,需要创建一个块对象shp,然后通过ax.add_patch(shp)将其添加到subplot中。
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
rect=plt.Rectangle((0.2,0.75),0.4,0.15,color='k',alpha=0.3)
circ=plt.Circle((0.7,0.2),0.15,color='b',alpha=0.3)
pgon=plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.6]],color='g',alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)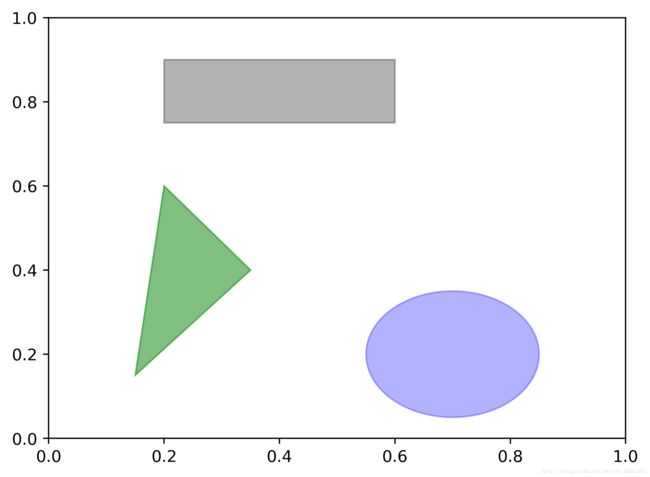
将图表保存到文件
利用plt.savefig可以将当前图表保存到文件。该方法相当于Figure对象的实例方法savefig。例如,要将图表保存为SVG文件,只需输入:
plt.savefig('figpath.svg')文件类型是通过文件扩展名推断出来的。因此,如果你使用的是.pdf,就会得到一个PDF文件。有两个重要的选项是dpi(控制“每英寸点数”分辨率)和bbox_inches(可以剪除当前图表周围的空白部分)。要得到一张带有最小白边且分辨率为400DPI的PNG图片,可以:
plt.savefig('figpath.png',dpi=400,bbox_inches='tight')
savefig并非一定要写入磁盘,也可以写入任何文件型的对象,比如SrtingIO,这对在Web上提供动态生成的图片很实用
from io import StringIO #没试验成功
buffer=StringIO()
plt.savefig(buffer)
plot_data=buffer.getvalue()
matplotlib配置
matplotlib自带一些配色方案,以及为生成出版质量的图片而设定的默认配置信息。几乎所有默认行为都能通过一组全局参数进行自定义,他们可以管理图像大小、subplot边距、配色方案、字体大小、网格类型等。操作matplotlib配置系统的方式主要有两种。第一种是Python编程方式,即利用rc方法。比如说要将全局的图像默认大小设置为10x10.
plt.rc('figure',figsize=(10,10))
font_options={'family':'monospace','weight':'bold','size':'small'}
plt.rc('font',**font_options)pandas中的绘图函数
线型图
Series和DataFrame都有一个用于生成各类图表的plot方法。默认情况下,它们生成的是线型图。
s=Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10))
s.plot()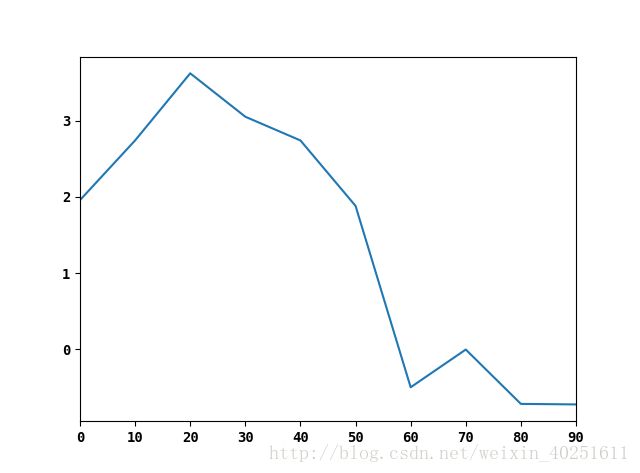
该Series对象的索引会被传给matplotlib,并用以绘制X轴。可以通过use_index=False禁止用该功能。X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim。


pandas的大部分绘图方法都有一个可选ax参数,它可以是一个matplotlib的subplot对象,能够在网格布局中更为灵活的处理subplot的位置。
DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例。
df=DataFrame(np.random.randn(10,4).cumsum(0),columns=['A','B','C','D'],index=np.arange(0,100,10))
df.plot()
DataFrame还有一些用于对列进行灵活处理的选项,例如,是要将所有列都绘制到一个subplot中还是创建各自的subplot。
DataFrame.plot(x=None, y=None,kind='line', ax=None, subplots=False, sharex=None,sharey=False,layout=None,
figsize=None, use_index=True, title=None, grid=None, legend=True, style=None,logx=False,logy=False,loglog=False
xticks=None, yticks=None, xlim=None, ylim=None,rot=None,fontsize=None,colormap=None,table=False, yerr=None, xerr=None, secondary_y=False, sort_columns=False, **kwds)
柱状图
在生成线型图的代码中加上kind='bar'(垂直柱状图)或kind='barh'(水平柱状图)即可生成柱状图。这时,Series和DataFrame的索引将会被用作X(bar)或Y(barh)刻度。
fig,axes=plt.subplots(2,1) #生成两行一列的图像
data=Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot(kind='bar',ax=axes[0],color='k',alpha=0.7)#axes[0]表示第一个图像对象
data.plot(kind='barh',ax=axes[1],color='k',alpha=0.7)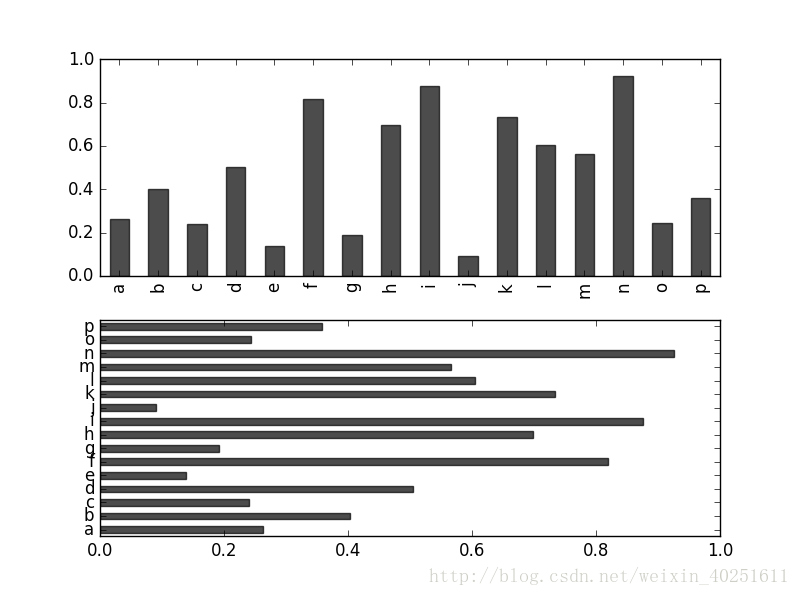
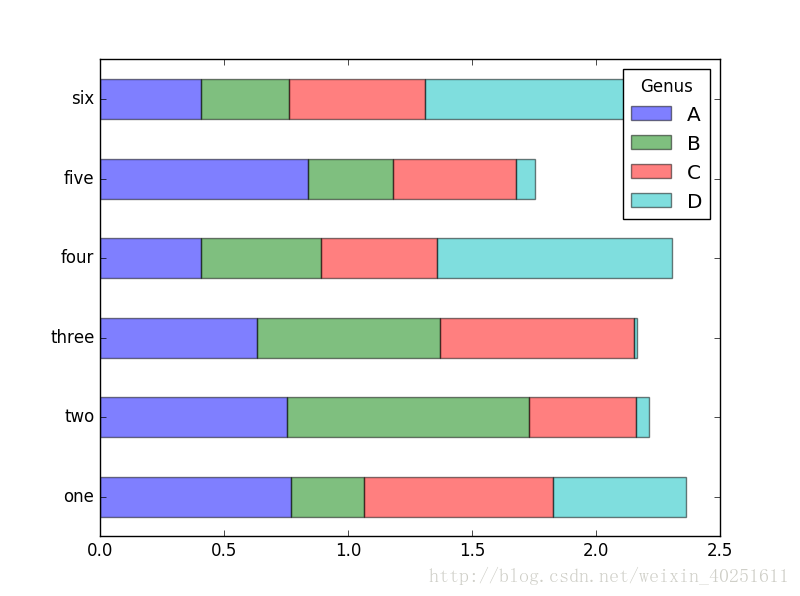
对于DataFrame,柱状图会将每一行的值分为一组。DataFrame各列的名称“Genus”被用作了图例的标题。
df=DataFrame(np.random.rand(6,4),index=['one','two','three','four','five','six'],
columns=pd.Index(['A','B','C','D'],name='Genus'))
df.plot(kind='bar')
#设置stacked=True即可为DataFrame生成堆积柱状图,这样每行的值就会被堆积在一起。
df.plot(kind='barh',stacked=True,alpha=0.5)

柱状图有一个不错的用法,利用value_counts图形化显示Series中各值的出现频率,比如s.value_counts().plot(kind='bar').
s=Series([1,2,1,3,4,5,6,4,3,3,2,2,2])
s.value_counts().plot(kind='bar')
关于小费的堆积柱状图
tips=pd.read_csv('tips.csv')
party_counts=pd.crosstab(tips['day'],tips['size'])
#crosstab第一个参数指定index,第二个参数指定columns,按照指定的行和列统计分组频数
#书上原文是party_counts=pd.crosstab(tips.day,tips.size)
#按照书上的代码会得到一个汇总的数据In [110]: pd.crosstab(tips['day'],tips['size'])
Out[110]:
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
In [117]: pd.crosstab(tips.day,tips.size)
Out[117]:
col_0 1464
day
Fri 19
Sat 87
Sun 76
Thur 62party_counts=party_counts.ix[:,2:5]
party_pcts=party_counts.div(party_counts.sum(1).astype(float),axis=0)
#按行归一,即先对一行数据求和,得到一个sum值,然后用该行的每一个数据去除这个sum值,得到一个比值In [115]: party_pcts
Out[115]:
size 2 3 4 5
day
Fri 0.888889 0.055556 0.055556 0.000000
Sat 0.623529 0.211765 0.152941 0.011765
Sun 0.520000 0.200000 0.240000 0.040000
Thur 0.827586 0.068966 0.086207 0.017241party_pcts.plot(kind='bar',stacked=True)

直方图是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
小费占消费总额百分比的直方图
tips['tip_pct']=tips['tip']/tips['total_bill']
#新增一列tip_pct,tip_pct的数值是tip列除以total_bill列
tips['tip_pct'].hist(bins=50)
#分成面元数为50
密度图通过计算“可能会产生观测数据的连续概率分布的估计”而产生的。一般的过程是将该分布近似为一组核(即诸如正态(高斯)分布之类较为简单的分布)。因此,密度图也被称为KDE(核密度估计)图。调用plot时加上kind=‘kde’即可生成一张密度图(标准混合正态分布KDE)。

这两种图常常会被画在一起。直方图以规格化形式给出(以便给出面元化密度),然后再在其上绘制核密度估计。
一个由两个不同的标准正态分布组成的双峰分布。
comp1=np.random.normal(0,1,size=200)#N(0,1)
comp2=np.random.normal(10,2,size=200)#(10,4)
values=Series(np.concatenate([comp1,comp2]))
values.hist(bins=100,alpha=0.3,color='k',normed=True)
values.plot(kind='kde',style='k--')
散布图(scatter plot)是观察两个一维数据序列之间的关系的有效手段。matplotlib的scatter方法是绘制散布图的主要方法。
macro=pd.read_csv('macrodata.csv')
data=macro[['cpi','m1','tbilrate','unemp']]#从macro中选出四列数据
trans_data=np.log(data).diff().dropna()#np.log()取对数,diff()一阶差分
trans_data[-5:]In [139]: trans_data[-5:]
Out[139]:
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560plt.scatter(trans_data['m1'],trans_data['unemp'])
plt.title('Changes in log %s vs. log %s' %('m1','unemp'))

散布图矩阵(scatter plot matrix),可以同时观察一组变量的散布图。pandas提供了一个能从DataFrame创建散布图矩阵的scatter_matrix函数。他还支持在对角线上放置各变量的直方图或密度图。
pd.scatter_matrix(trans_data,diagonal='kde',color='k',alpha=0.3)