使用Python,创建你的第一个实用型入门机器学习项目(下)
注:本文分上、下两部分,本章是教程的下半部分。
4. 可视化数据集
我们现在对数据有一个基本的想法,我们需要用一些可视化来扩展它。
我们要看看两种类型的情节:
使用单变量绘图以更好地理解各个属性
使用多变量绘图以更好地理解各个属性之间的关系
4.1 单变量情节
我们从一些单变量图开始,即每个变量的图。
鉴于输入变量是数字,我们可以创建每个变量的箱-线图。
# 箱-线图
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()
这使我们对输入属性的分布有了更清晰的认识:
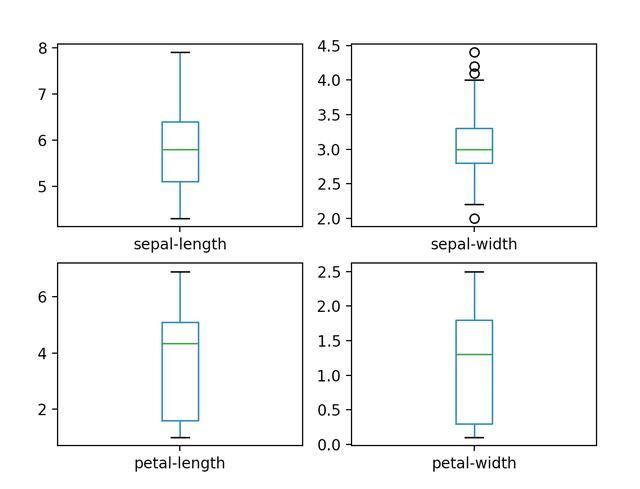
箱-线图
我们还可以创建每个输入变量的直方图(即矩阵图),以了解分布情况。
# 直方图
dataset.hist()
plt.show()
看起来似乎两个输入变量有一个高斯分布,这点很有用,因为我们可以使用算法来验证这种假设。

直方图
4.2 多变量图
现在我们可以看看变量之间的相互作用。
首先,我们来看看所有对属性的散点图, 这有助于发现输入变量之间的结构关系。
# 散点图矩阵
scatter_matrix(dataset)
plt.show()
请注意一些属性对的对角线分组,这表明高度相关性和可预测的关系。

散点图矩阵
5 评估算法
现在是时候创建一些数据模型,并估计它们对未查看数据的准确性。
以下是我们将在此步骤中涵盖的内容:
分离出验证数据集。
设置测试工具以使用10倍交叉验证。
建立5种不同的模型来预测花朵测量的物种
选择最好的模型。
5.1 创建一个验证数据集
我们将使用统计方法来估计我们在看不见的数据上创建的模型的准确性, 我们还希望通过对实际看不见的数据进行评估,更准确地估计未见数据的最佳模型的准确性,我们需要知道我们创建的模型是好的。
也就是说,我们将阻止一些算法无法看到的数据,我们将使用这些数据获得第二个独立的想法,即最佳模型实际可能有多准确。我们将加载的数据集分成两部分,其中80%用于训练我们的模型,20%用作验证数据集。
# 拆分验证数据集
array=dataset.values
X=array[:,0:4]
Y=array[:,4]
validation_size=0.20
seed=7
X_train,X_validation,Y_train,Y_validation=model_selection.train_test_split(X,Y,test_size=validation_size,random_state=seed)
您现在已经在X_train和Y_train中准备了用于准备模型的训练数据以及稍后可以使用的X_validation和Y_validation集。
5.2 测试
我们将使用10倍交叉验证来估计准确性。
这将把我们的数据集分成10个部分,在9上进行训练并在1上进行测试,并对列车测试分组的所有组合进行重复。
#测试选项和评估指标
seed=7
scoring='accuracy'
我们正在使用“准确度”度量来评估模型。 这是正确预测的实例数量除以数据集中的实例总数乘以100得到的百分比(例如95%准确)的比率。 当我们运行构建并接下来评估每个模型时,我们将使用评分变量。
5.3 构建模型
我们不知道哪种算法在这个问题上很好,或者使用哪种配置。 我们从这些图中得到一些想法,即某些类在某些维度上可以部分线性分离,所以我们期望通常会有很好的结果。
我们来评估6种不同的算法:
Logistic回归(LR)
线性判别分析(LDA)
K-最近邻居(KNN)。
分类和回归树(CART)。
高斯朴素贝叶斯(NB)。
支持向量机(SVM)。
这是简单线性(LR和LDA),非线性(KNN,CART,NB和SVM)算法的良好混合。 我们在每次运行之前重置随机数种子,以确保使用完全相同的数据拆分执行每个算法的评估。 它确保结果可以直接比较。
让我们来构建和评估我们的五个模型:
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
5.4 选择最佳模型
我们现在有6个模型和准确度估计值。 我们需要将模型相互比较并选择最准确的模型。
运行上面的例子,我们得到以下原始结果:
LR: 0.966667 (0.040825)
LDA: 0.975000 (0.038188)
KNN: 0.983333 (0.033333)
CART: 0.975000 (0.038188)
NB: 0.975000 (0.053359)
SVM: 0.991667 (0.025000)
我们可以看到,它看起来像KNN具有最大的估计准确性。
我们还可以创建模型评估结果的图表,并比较每个模型的差异和平均准确度。 每种算法都有一组准确性度量,因为每种算法都进行了10次评估(10次交叉验证)。
# 算法比较
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
您可以看到盒子和线须块在范围的顶部被压扁,许多样品达到100%的准确度。
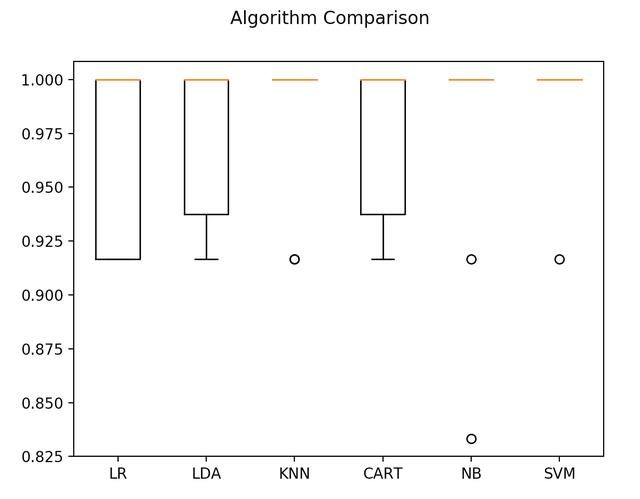
算法比较
6 预测
KNN算法是我们测试的最精确的模型。 现在我们想要了解我们验证集上模型的准确性。
这将使我们对最佳模型的准确性进行独立的最终检查。 为了防止在训练过程中发生故障(如过度训练集或数据泄漏),保留验证集非常有用。 两者都会导致过于乐观的结果。
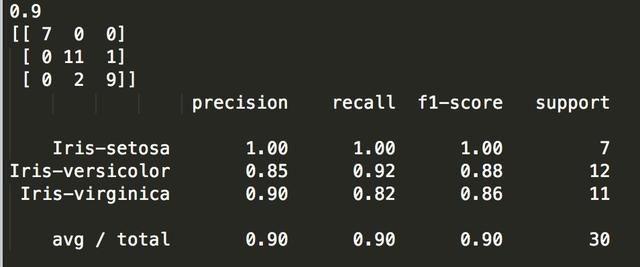
我们可以直接在验证集上运行KNN模型,并将结果汇总为最终准确度分数,混淆矩阵和分类报告。
# 在验证数据集上做预测
knn = KNeighborsClassifier()
knn.fit(X_train, Y_train)
predictions = knn.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
我们可以看到准确度为0.9或90%。 混淆矩阵提供了三个错误的指示。 最后,分类报告按精度,召回率,f1分数和支持显示出色的结果(授予验证数据集很小)提供每个类的分类。
6 你可以使用Python进行机器学习
通过上面的教程,这将需要109到20分钟,最多!你就可以对机器学习有个比较全面的了解!
你不需要了解一切。 (至少不是现在)你的目标是贯穿教程的端到端并得到结果。你不需要了解第一遍的所有内容。当你走的时候列出你的问题。大量使用Python中的帮助(“FunctionName”)帮助语法来了解您正在使用的所有功能。
你不需要知道算法是如何工作的。了解限制和如何配置机器学习算法是很重要的。但是关于算法的学习可能会晚一些。您需要在很长一段时间内慢慢建立这种算法知识。今天,首先要让平台变得舒适。
你不需要成为一名Python程序员。如果你是新手,Python语言的语法可以是直观的。就像其他语言一样,关注函数调用(例如function())和赋值(例如a =“b”)。这会让你获得最大的成就。你是一名开发人员,你知道如何快速掌握一门语言的基础知识。刚开始,稍后再深入细节。
你不需要成为机器学习专家。您可以稍后了解各种算法的优点和局限性,并且您可以稍后阅读大量文章,以了解机器学习项目的步骤以及使用交叉验证评估准确性的重要性。
机器学习项目中的其他步骤如何?我们没有涵盖机器学习项目中的所有步骤,因为这是您的第一个项目,我们需要关注关键步骤。即,加载数据,查看数据,评估一些算法并做出一些预测。
结束语
在这篇文章中,你逐步发现了如何用Python完成你的第一个机器学习项目。
您发现从加载数据到做出预测完成一个小型的端到端项目是熟悉新平台的最佳途径。