论文阅读(一)CVPR2019 AANet: Attribute Attention Network for Person Re-Identifications
文章地址:http://openaccess.thecvf.com/content_CVPR_2019/papers/Tay_AANet_Attribute_Attention_Network_for_Person_Re-Identifications_CVPR_2019_paper.pdf
源码:谁找到了评论一下呗。
摘要:
本论文提出了一个“属性注意力网络”,这个新颖的网络结构整合了多种人体属性和一种叫做attribute attention maps的特征图,然后利用分类网络框架来处理reid的问题。许多reid模型使用身体语义信息如身体局部区域、人体姿态等等来提升reid的效果。然而人体属性信息并没有被经常用在reid任务中。本文提出的AANet模型,该模型整合身体局部区域关键的属性信息到一个同一的学习网络框架中。AANet包含三个任务:(1)全局身份鉴别任务、(2)局部区域检测任务、(3)关键属性检测任务。通过测试评估单个属性和集成属性(AAM)的分类效果,发现有很强烈的区别表现。其中使用Duke数据集,AANet的表现比用resnet-50的mAP高出3.36%,Rank-1高出3.12%。用Market1501数据集使用re-rank,AANet达到mAP:92.38%,rank-1:95.10%。比使用Resnet-152的高出mAP:1.42%,Rank-1:0.47%.此外AANet能实现行人属性的预测(性别、头发长度、衣服长度...)并局部化query图像的属性。
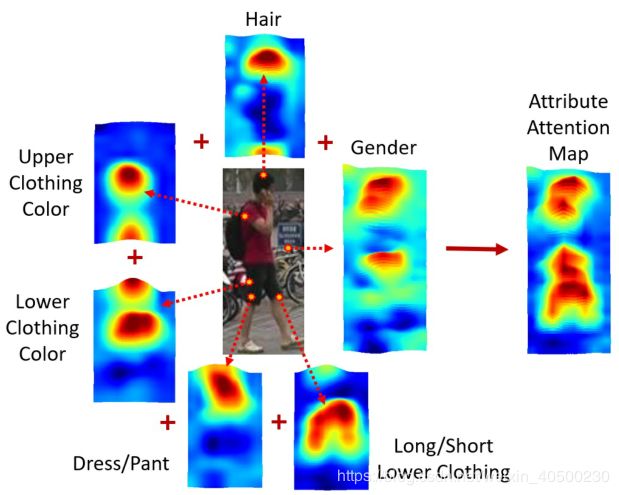
图1.将 Class-aware 热图提取并结合起来,形成一个就有判别性Attribute Attention Map (AAM)。这里显示的六个热图对应六个属性,如头发、上衣颜色、下衣颜色等。
1.介绍:
给定一个query image,行人再识别任务目的在于重新检索出一开始指定为query的哪个image。这项任务通常尝试着在短时间内的摄像头拍摄的图像集中进行重检索。这项任务使用行人基本不变的属性如:衣服和外观属性。这项任务面临着许多挑战,比如:目标的局部全部的遮挡,姿态变化,图像光线的变化,图像分辨率太低...都会对识别效果产生影响。最近基于深度学习的Reid算法的识别效果表现很好。
解决行人再识别的问题的方法大致可以分为两类:(1)采用度量学习的方法,将相似的person image距离拉近,不同的image距离拉远,其中会用到triplet loss、quadruplet loss。(2)将Reid问题构建为一个分类问题,这类方法使用Softmax loss,个人身份作为标签,通过反向传播进行训练学习。研究表明,结合语义信息(如:身体局部信息,人体姿态等)可以显著提高Reid的准确率。但是目前先进的Reid方法中人体属性(如:衣服颜色、头发长短、性别)并没有用到Reid任务中,并且人体属性在短时间内不会发生显著变化,因此该属性可以作为一个可以使用的线索,用于提高Reid性能。
在这篇文章中我们提出,将行人属性信息应用到分类框架中。由此产生了叫做属性注意网络框架(AANET),该网络将身份类别、身体局部信息、行人属性统一到一个框架中来共同学习一个具有高判别度的特征。实验结果表明网络的输出结果在多个基准数据集表现优于目前最先进的方法。

图2:AANet,主干网络采用resnet50,生成特征图X。接着将特征图前向传播输入到三个结构中分别称作:Global Feature Network(GFN), Part Feature Network (PFN) , Attribute Feature Network (AFN)。最后三个结构的输出结合,采用同方差的不确定性学习来预测行人身份(什么东西??)。
图2给出了AANET模型的大体结构。该模型包含3个子网络。第一个网络我们称之为Global Feature Networks(GFN),采用全身特征信息进行分类。第二个网络称为Part Feature Network (PFN),关注于身体局部区域检测。第三个网络称为Attribute Feature Network(AFN),从行人身体上抽取多层次的属性信息构成Attribute Attention Map (AAM),AAM如图一所示。这三个网络使用行人ID和属性标签进行分类,并且使用同方差不确定性来学习优化三个子网络的权重,该权重会用于损失计算。
因为AANet网络将人属性分类作为网络学习的一部分,因此它要为每个query和gallery做属性预测。这样在gallery属性进行匹配时可以通过查询图像进行检索,也可以不通过查询图像进行检索。
本文主要贡献有两个:
-
提供了一种新的网络架构,将属性特性与身份和身体部位分类集成在一个统一的学习框架中
- 在多个基准数据集上超越了现有的最先进的Re-ID方法,并为Person Re-ID提出了最先进解决方案。
论文的其余部分组织如下。第2节概述了相关工程。在第3节中,我们描述了所提议的AANET框架。实验结果分别在4和5节。第6节做了总结。
2.相关工作
略....

图3.提出的AAM热图和GFN生成的热图比较。AAM捕捉人的属性,因此激活区域主要位于行人身体内。GFN热图受训练数据集的影响,密度较低,可能包含背景作为热图的一部分。
3. Proposed Attribute Attention Network(AANet)
提出的AANET是一个多任务网络,有三个子网络,即GFN、PFN和AFN(图2)。子网络GFN执行全局图像层次的行人ID分类任务。在分类任务之前,PFN结构检测并提取局部身体特征。AFN网络将行人属性用于分类任务,并生成Attribute Activation Map (AAM),这个在身份分类任务中起着重要作用。AAM的一些例子如图三所示,从图中可以看出,AAM提供了比ID heatmap更加有判别能力的属性。因此,当GFN、PFN、AFN一起学习时,AANET起到的效果更好。AANET的各个组件在下面的章节中详细描述。
AANET的主干网络采用Resnet50结构(图2),因为众所周知Resnet用在Reid任务中效果很好。我们去掉了主干网络的全连接层以便于更好的集成AANET的子网络。AANET中有四个分类器,分别是:它们是Global ID分类器、局部分类器、属性分类器和AAM分类器。Global ID分类器、局部分类器分别属于GFN与PFN。属性分类器和AAM分类器属于AFN。这四个分类器网络结构都比较相似,全都使用GAP降低过拟合,都用一个三层(Z、V、C)结构增加网络深度以学到更好进行特征学习,都使用Softmax normalization和Cross-entropy loss。
3.1. Global Feature Network
GFN网络结合使用query图像可实现身份分类。在图二中,通过主干网络Resnet卷积网络提取出特征图X,然后输入到GAP层。接下来进入Global ID Classifier后使用一个1x1的全卷积层将通道维度下调到V,在使用Softmax做线性变换为C之前,要对V进行BatchNorm和Relu。最后使用交叉熵损失,并反向传播。

图4。PFN将特征图X分成6个ROI区域,使用的方法是峰值激活检测和池化。 这6个ROI的特征将进一步用于身份分类。
3.2. Part Feature Network
PFN网络使用同GFN中一样的Person ID标签对人体局部区域进行分类。该结构如图4所示。身体局部区域检测器将特征图X分成水平的6块,并且估计每一块的ROI区域。该估计方法通过找到X中的峰值激活区域来实现。用![]() 表示特征图X的每一个通道z的峰值激活区域,其中
表示特征图X的每一个通道z的峰值激活区域,其中![]() 。
。

其中![]() 是在第z个通道上,区域(h,w)的激活值。然后根据他们的垂直位置将这些激活的区域放到6个box,即6个ROI区域中。现在特征图就已经被分出了6个ROI区域。具体步骤如图4所示。一旦这6个ROI计算了出来,那后续的部分如classifier等部分就和GFN是一样的了。
是在第z个通道上,区域(h,w)的激活值。然后根据他们的垂直位置将这些激活的区域放到6个box,即6个ROI区域中。现在特征图就已经被分出了6个ROI区域。具体步骤如图4所示。一旦这6个ROI计算了出来,那后续的部分如classifier等部分就和GFN是一样的了。

图5,从Market1501数据集上的全局、上、中、下生成12个属性特征向量
3.3. Attribute Feature Network
在AANet结构中,子网络AFN负责获取关键的人体属性信息。AFN子网络包含两个子任务;(1)人体属性分类、(2)attribute attention map (AAM)的生成。第一个子任务对个人属性进行分类。第二个子任务利用第一个子任务的输出为每一种属性生成类别激活图(class activation map CAM)。CAM是一种定位判别性图像区域的技术,即使网络在image-level层次上训练。因此CAM非常适合AANET使用。多种不同类的属性的CAM结合起来生AAM,然后前向输入到AAM分类器中进行学习。我们将在以下段落中详细描述这两个子任务
(i)Attribute classification
AFN的第一个子任务进行属性分类。在DuketMTMC-reID和Market1501数据集上分别有10和12个可用属性。AFN的第一层是一个1x1的卷积层,将特征图X的通道数由Z降低到V。然后把特征图分成上、中、下三个部分,分别从每一个部分提取特征。众所周知分成局部提取特征的好处是可以降低背景的影响同时提升分类准确率。不同的部分关注不同的属性,例如,顶部特征图用于捕捉诸如帽子、头发、袖子和上部衣服颜色等特征。在顶部特征图中,中下部分的身体部分的特征将被忽略。如图5所示,全局、上中下特征图都经过GAP在V层生成4特征向量。这四个向量输入到全连接层C中。在Market1501中,C层可以分为4类,每一类都有自己的属性预测。

图6,在Market1501数据集上,使用了12种属性,这里只展示最重要的8种。被红色框种的map是用来生成AAM的,第一列的也就是全局特征图由GFN获得,它的存在是为了和其他属性图进行比较。背包、手提包、包和帽子属性,这些尽管是重要的视觉提示,但并不出现在所有图像中,因此被弃用。袖子的注意力图捕捉了太多的背景信息,因此不适合AAM。
(ii)Attribute Attention Map
如图2中所示,Attribute Attention Map (AAM)输入到Attribute Classifier中,然后进行Person ID分类。AAM集成了单独类敏感激活区域。这些单独的类敏感激活区域是通过CAM从每个人体属性中提取出来的。正如前面提到的,CAM使用GAP并稍加调整来生成有判别力的图像区域。因此CAM的输出代表了图像中表示人体属性的局部区域。图6展示了类敏感激活区域合成AAM的例子。为了进行定性比较,图6第2列显示了由GFN生成的激活图。后面的列显示了各种属性(如性别、头发、袖子、上身服装颜色等)的特定类的激活区域。例如,第6列描述了上衣颜色特定类的激活区域,我们可以观察到激活区域对应于输入query图像中的上衣区域。
在Market1501中行人图像由12个属性可以用,这12个属性中使用性别、头发、上下衣服颜色、下衣服类型和长度属性用于合成AAM是比较好的选择。使用带有自适应阈值的最大值操作将单独的类激活区域合成AAM。带有阈值可以帮助去掉一些出现在类激活区域的背景部分。在图6的第二行中可以观察到这样一个例子,其中下部衣物激活图包含一些背景区域,但在阈值设定时,该区域从生成的AAM中移除。对于某一个query图像来说,不同的属性信息,AAM获得的区分度比GFN网络的效果好。如图2中所示,AAM输入到Attribute Classifier中进行ID分类,并且与GFN和PFN共享学习经验。
3.4. Loss calculation
AANet是一个多任务网络,对应的多任务损失函数定义如下:
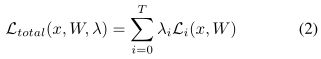
其中,x表示一系列训练图片,W是输入x对应的权重。T代表任务损失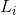 的个数(3个吧)。
的个数(3个吧)。 代表不同任务损失所占的权重,其对AANet准确率的优化起着关键的作用。如我们让都相等,那么将得不到最好的准确率。在本论文中,使用同方差不确定性学习来获得不同任务的损失的权重(接下来全是公式太难翻译,直接贴原文了,谅解,从We define...开始)
代表不同任务损失所占的权重,其对AANet准确率的优化起着关键的作用。如我们让都相等,那么将得不到最好的准确率。在本论文中,使用同方差不确定性学习来获得不同任务的损失的权重(接下来全是公式太难翻译,直接贴原文了,谅解,从We define...开始)


3.5. Implementation
我们实现了以resnet-50和resnet152为主干网的AANet,并用imagenet数据集对它们进行了预训练。训练图像被放大到384 x 128,只使用随机翻转作为数据增强方法。resnet-50的批大小设置为32,resnet-152的批大小设置为24。以随机梯度下降(SGD)为优化工具,对网络进行40个epoch的训练。对于新添加的层,学习率从0.1开始,对于预培训的resnet参数,学习率从0.01开始,并遵循20 epoch的楼梯时间表,所有参数的折减系数为0.1。在这三个子网络中,Z值为2048,V值为256。C的值取决于正在评估的数据集。对于Dukemtmc Reid,C为702,对于Market1501,C为751。
在测试过程中,我们将所有分类器(即全局身份分类器、体部分类器、属性分类器和AAM分类器)的V层输出连接起来,形成query图像的表示。Rank方面,使用L2范数,即欧式距离来计算。
4. Experimental Results
在以下实验中,我们使用DukeMTMC-reid和Market1501数据集进行训练和测试。DukeMTMC-reid是DukeMTMC数据集的一个子集,其中的图像是从8个摄像头拍摄的视频中剪辑出来的,数据集由16522张训练图像和17661张gallery图像组成,其中702张标识用于训练和测试,其中包含408个干扰ID。Lin等人共注释了23个属性,我们使用所有这23个属性,但对服装颜色属性进行了修改。我们将8个上衣颜色属性和7个下身服装颜色属性分别合并为一个上衣属性和一个下身服装属性。
对于Market1501数据集,其中有32668张图用于训练和测试,其中训练集包含751个人,测试集包含750个人。Lin等人注释了此数据集,但具有27个人属性。我们使用与DukeMTMC-reid相同的服装颜色策略,并使用所有属性来训练我们的模型。
4.1. Comparison with existing methods
作者在Duke和market1501上分别和其他几个目前最先进的方法进行比较。





4.2. Network Analysis
这一节分析了三个子网络的损失权重和主干网络的尺寸对Reid的效果的影响,并介绍了一些训练参数。
Ablation Study(消融研究:消融研究通常指的是移除模型或算法的某些“特征”,并观察其如何影响性能。):
在表3中,我们使用DukeMTMC-Reid数据集,展示了不同损失权重对准确率的影响。将global ID任务、part任务、属性分类任务、AAM任务标记为![]() ,
,![]() ,
,![]() ,和
,和![]() 。我们分别将这些任务加到网络中,准确率都得到提升,表明这些任务对网络有效果。当我们使用homosce-dastic uncertainty learning获得
。我们分别将这些任务加到网络中,准确率都得到提升,表明这些任务对网络有效果。当我们使用homosce-dastic uncertainty learning获得![]() ,
,![]() ,
,![]() 损失权重的时候,mAP和Rank-1再次得到显著提升,单单这个结果就已经比Resnet5效果好了,当吧AAM任务加到网络中后,提升效果更明显。(具体数值看表3)
损失权重的时候,mAP和Rank-1再次得到显著提升,单单这个结果就已经比Resnet5效果好了,当吧AAM任务加到网络中后,提升效果更明显。(具体数值看表3)

Effect of Backbone Network
主干网络的深度影响着Reid的准确率。由表1表2可以看出,网络深了准确率提高了。表2中最后一行的Rank-1:95.10%就是在Market1501上用Resnet-152实现的。
Effect of Training Parameters
很多文献中有许多设置参数的技巧来提高准确性。比如在一篇文章中,作者使用了十个数据集来训练和测试,这样生成了大约111K张图,17K个身份。还有方法如在网络不同阶段使用不同图像尺寸。在另一篇文章中,作者使用了一些技巧,如:使用预训练网络,使用大尺寸图片、使用hard triplet mining、和较深的主干网络,这些方法都比较有用。然而本文中AANet的训练,使用了较小图像尺寸、较为简单的训练步骤和较浅的Resnet50网络(不是也用深得Resnet了吗???)
5. Experimental Results Using Attribute
本节主要说明行人属性是如何优化Reid检测效果的。

5.1. Retrieval results
在图7中展示AANet的三个识别示例,虽然这三个图都受到了汽车或者行人的遮挡,但AANet得检索依然非常正确没有问题。

图8,举了三个行人属性是如何提高检索准确率得例子。使用了3个很由挑战性得query,结果就返回了许多错误得结果,由于因为AANet返回每一个带有预测得属性query和gallery,它为用户提供了一个选项,可以使用属性匹配来过滤掉不需要的检索图像。有用的属性包括性别。衣服颜色、背包等。绿色框表示与query相同的ID。红色框表示不同于query的ID。(都遮挡成那样了还能检索。。。NB)
在图8中列举了一些使用检测严重遮挡得query时得例子,可以看出,检索精度受到影响。图8展示了,使用AANet如何使用属性信息过滤掉错误检索的。给出了三个例子,每个例子都有不同的检索难题。第一个例子,半个人都被行人遮挡了,大多数方法应该都会选错,图中也一样,全是选错的红色框。但是通过AANet的属性匹配方法,错误的图片被轻松过滤了,第一行后面这5个图在第一次没使用AANet时检索排序为1,19,38,79,172,可见使用AANet的效果。例子2,3给出了其他检索困难,但也使用AANet轻松被化解了。

5.2. Attribute Classification Performance
表4对比了APR(Lin等人提出的,Lin等人在数据集上对属性做了标注)与AANet-152的属性分类准确率,因为AANet使用局部属性特征加强网络学习,所以效果比APR好。
6. Conclusions
本文提出了一种新的体系结构,将服装颜色、头发、背包等基于物理外观的属性融入到基于分类的个人识别框架中。提出的AANet采用了端到端学习,并且使用同方差不确定性学习获得损失权重用于多任务损失融合。由此产生的网络在多个基准数据集上的效果优于现有的最先进的Reid方法。
Acknowledgement
答谢。。。
本文以人工翻译辅以机器翻译,若有不妥之处还请指正。该文为第一次自己亲手翻译文章,虽说稍有耗时,但阅读的更加透彻。若本文可以对您有些帮助,请帮我点个赞,我会很开心的。同时Reid方面的话题也欢迎交流沟通,共同学习进步。