【文章阅读】PointPainting
前言
本文来自nuTonomy自动驾驶公司,目前已经被CVPR20接收。值得注意的是,本文并不是提出了新的结构,而是在利用额外的信息融合进之前表现SoTA的网络中,表现出了检测精度的提升。
文章地址 https://arxiv.org/pdf/1911.10150.pdf
本文主要内容概括
本文研究了一种新的image和lidar的fusion方式,在18年SOTA的baseline上都显示出精度的提升,同时对小物体优于大物体;本文的fusion方式是采用二维语义分割信息通过lidar信息和image信息的变换矩阵融合到点上,再采用baseline物体检测;可以理解为对于语义分割出的物体多了一些信息作为引导,得到更好的检测精度。
1. Abstract
- 我们知道目前做3D检测的内容按照网络输入的数据可以分为image_only,lidar_only和image_lidar_fusion的方法,但是在众多的benchmark中Lidar_only的方法精度都表现的比其余两种的要好,但是按照常识理解,image_lidar_fusion的方法应该具有更多的信息,为什么融合的精度反而不即lidar_only的方法,笔者认为目前lidar——only精度高的都是采用了two-sgate的设计,同时3D检测中点云几何结构信息肯定是在信息中占据主导地位,因为本身two-stage的方法在time cost的效果上就相较one-stage要大,如果加入image信息融合,会造成更大的time cost。融合的方式也很有讲究,最开始的方法诸如F-PointNet(CVPR18)则是先采用二维检测,再投影到三维点云中进行Bbox回归;后续的融合有PI-RCNN(AAAI20)仅仅将图像的信息作为额外信息融合进由一阶段方法提出的proposals的特征中。
- 作者表示,之前的融合方法可能都没有找到合适的融合方法,因此本文的核心内容是提出了一种新的二维信息和三维点云信息的融合方法。
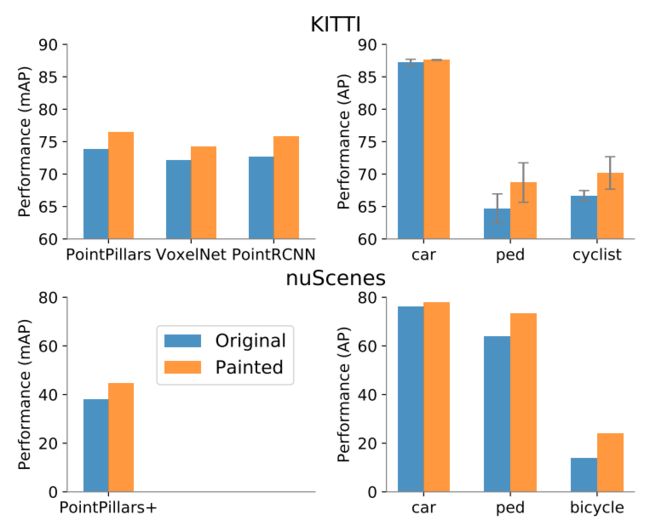
- 作者将该融合方式在19年的几个SOAT的方法(VoxelNet、pointpillars、PointRcnn)中进行测试,均表现出精度的提升。如下图所示。左上图表示了在KITTI上的提升,右上图表示在KITTI上类别的提升,可以看出在行人和自动车这种相对较小的物体检测的效果提升比较明显。(笔者猜测小物体的Lidar细节信息可能被Image补足的比较多)
2 介绍
2.1 Lidar信息对3D检测而言是否已经足够?
这是作者提出的第一个问题,给出的回答肯定是不行的,作者给出下图指出,在image中可以对杆子和行人清晰的辨认出,但是在Lidar模态中,看上去却很相似(这一点其实笔者有一点自己的想法,如果都是通过人眼去对此两种模态的信息进行感知,然后辨认出孰优孰略是否不太合适,机器感知的过程对不同模态数据未必一样,但是实验表明,对于KITTI上很多数据,的确存在将信号灯柱状物识别为行人)。第二点也就是前文笔者提到的增加信息至少不会丢失精度的。

2.2 目前fusion精度低的可能原因
作者认为可能是数据处理的视角不一样,在lidar-based的SOTA的方法中,基本上都是在BEV的视图上进行的,但是在Image视图却是在front视图。lidar数据很容易转化为BEV视图信息,但是Image却不容易,也不精确。因此作者认为fusion的核心问题在于将BEV视角和camrea信息融合。
2.3 目前的融合方法
1.Object-centric fusion
该种融合方法是在proposals阶段进行融合,image和lidar都采用了不同的backbone,在proposals level阶段fusion
2.continuous feature fusion
在特征图上进行融合,这类融合方式最大的缺点在于“特征模糊”,这是因为在BEV视图上的一个pix对应着Image视图上的多个pixel。
3. transform the image to a BEV
第三种融合方式则是将Image转化到BEV视图表示,再在此视图上进行融合。但是转化的步骤都是time cost的
4. detection seeding
类似F-pointnet,先通过2D detector得到image检测结果,再投影到3D lidar上。
3 本文的网络结构
网络结构如下图所示,主要包括三个部分:(1)语义分割网络,Image-based语义分割计算每一个像素点的语义分割分数(2)fusion:Lidar points被语义分割的分数融合(3)3D Object Detection。
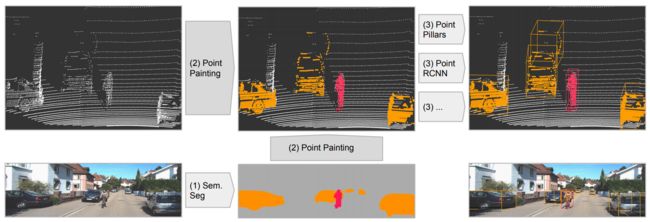
3.1 语义分割网络
作者指出采用语义分割作为融合手段有如下的几点优势:
(1)语义分割网络早于3D目标检测网络,仅仅需要对局部的每个pix进行分类
(2)比较容易训练,推理速度也快
(3)语义分割输出的信息在自动驾驶任务中,不仅仅是对3D目标检测有用,对深度估计等任务也有用的。
3.2 PointPainting
该章节则是展现了本文提出的核心思想,如何painting则是在这一小节进行讨论。
我们知道在KITTI上点云的描述表达为 ( x , y , z , r ) (x,y,z,r) (x,y,z,r),在nuscenes上表达为: ( x , y , z , t ) (x,y,z,t) (x,y,z,t),其中在KITTI上image和lidar的转化只需要三个转换矩阵就行了,但是在nuscenes上,lidar和image的频率是一致的(lidar为20HZ)。
painted的具体方法就是通过转换矩阵得到lidar2image的检索信息,首先根据将每个点得到的份语义分割分数融合到lidar的表示上;但是有些点云可以投影到两个图片中,此时作者的选择方法是随机选择一个就行。
伪代码如下:

Lidar Detection
作者选着了在18年的sota的方法,voxelnet、pointpillars和pointrcnn。
这里简单介绍一下这三个网络结构及其特点:
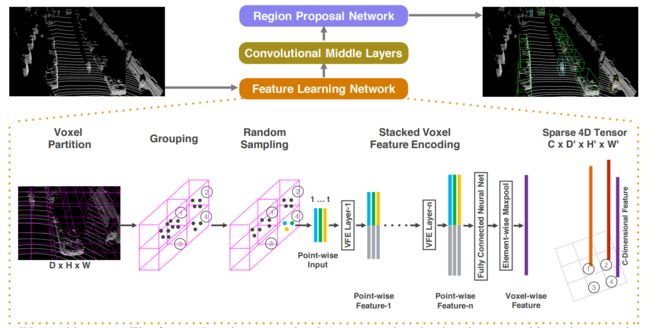
(1)VoxelNet:如下图,该网络第一个采用深度学习特征代替手工特征,也是voxel-based的方法的开山作,该结构首先对全场景体素化,然后对每个体素采用MLP特征提取,最后采用maxpooling得到voxel特征,再采用3D卷积使得H维度降维1,变为2D fea map,最后采用二维的rpn head检测出最终的结果即可。
(2)pointpillars:该结构和voxelnet不同的地方就是该网络结构将划分体素更改为了柱子划分,可以直接省略到3D卷积结构,该结构的显存占用很大。因此pointpillars的结构使得推理阶段更快,同时显存占用也大大减少。

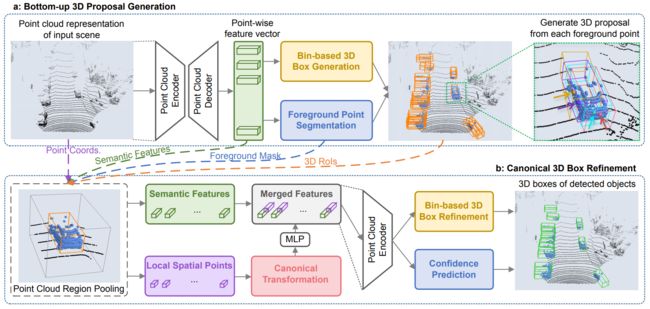
(3)point-rcnn:这一篇是第一篇lidar-based的代用point作为representation的文章,采用pointnet++作为backbone,然后对每个点都提proposals。
4. Results
4.1 KITTI
在KITTI的benchmark上效果如下,可以看出对于小物体的精度提升比大物体的大。
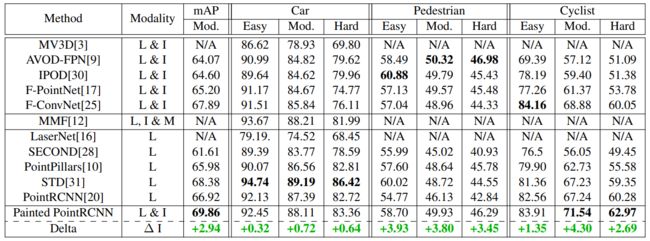
4.2 nuscenes
因为目前的方法pointRCNN对于输入点云数量比较敏感,并不能在小显存下载nuscenes这样的大数据集下跑,这里作者给出了对于pointpillars的精度提升,我们可以看出实际上页数类似行人(+9.3)和自动车(10.1)的提升比较大。

4.3 消融实验
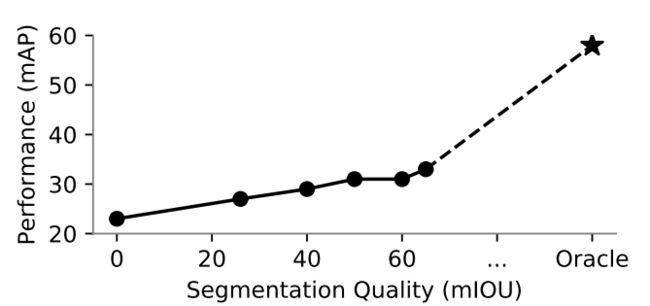
对语义分割信息的依赖程度
如下图,横坐标表示语义风格精度IOU值,纵坐标表示了3D检测精度。
Sensitivity to Timing
作者表示,如果使用当前帧之间对应融合和使用之前的图像信息融合的差距,这里作者指出因为如果采用lidar对应的当前帧会使得lidar backbone信息等待语义分割分数,又由于nuscenes本身提供的是连续帧信息,因此作者指出这样一个减少时延的设计。如下图,
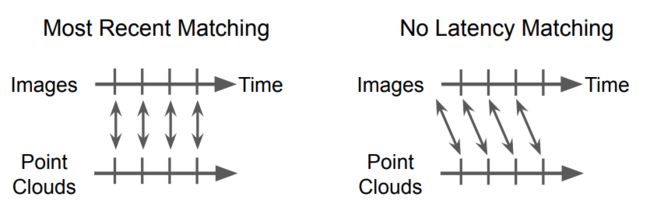
实验结果如下所示,表明采用当前帧和之前帧的信息实际没有区别。

5 笔者的思考
本文的主要贡献在于把语义分割的特征信息融合到lidar中,但是个人感觉这种方法已经有研究在之前做过,但是融合方式不是以segment的信息为主导,而是lidar的proposals的点才进行检测,但是因为本文并没有采用和最新的baseline做painted测试,实验效果是否可以进一步提升?这才是真正回答了作者在introduction中提出的当前的lidar信息是否对3D检测信息已经足够了这个问题,此外,笔者认为,融合后的实验效果显示出对小物体的精度提升比较明显,是否可以理解为这种更需要细节信息的小物体的信息从image中得到的补足比较多,而车这种的大物体,本身具有的点数就比较多,同时也不会有场景物体可以与其互相模糊。