hbase shell及 java api的过滤器操作
一. hbase shell的filter操作
1. 不设置过滤器,全表扫描
scan '表名' //查询出某个表格内全部的数据记录
举例 : scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_22180822'
查询结果如下(截取了其中一个行键的内容) :
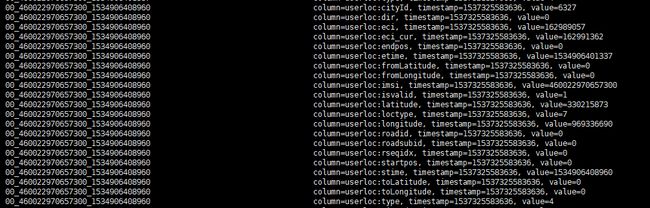
因为hbase的shell脚本操作十分不方便,并且不支持查看上下文,对我们使用者来说十分不友好,所以对于查询操作,我们使用诸如下面的操作进行"
举例 : echo "scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822'" | hbase shell
// 输出表格的查询结果到控制台,效果等同于在hbase shell脚本里进行查询
// 需要注意的是脚本里面包含""的话,前面需要加\进行转义
// 接下来的示例将使用两种方式进行举例,并且每条命令均经过验证
2. 按照value的值过滤 ValueFilter
scan '表名', FILTER=>"ValueFilter(=,'substring:value值')" //查询出某个表格内列值包含指定字符串的记录
举例: upos_city_qh_yushu:tb_detail_userloc_outdoor_22180822, FILTER=>"ValueFilter(=,'substring:6327')"
//该命令表示查询表名 upos_city_qh_yushu:tb_detail_userloc_outdoor_22180822
里面值包含6327的记录
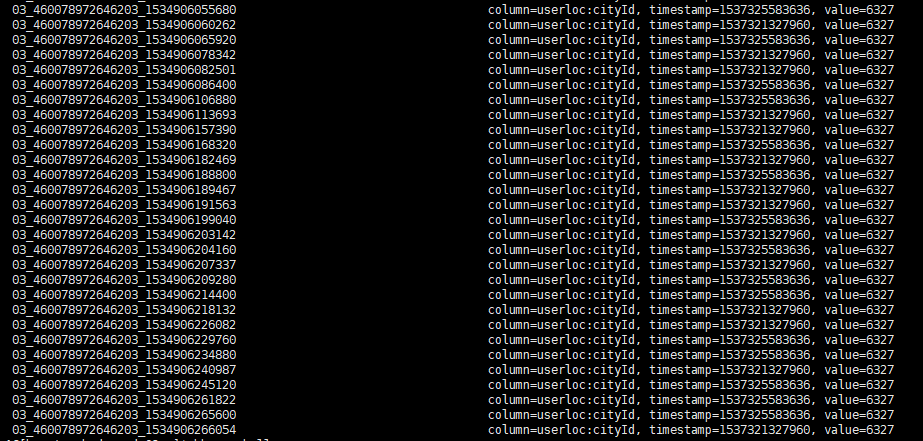
3. 按照列簇进行过滤 FamilyFilter
scan '表名', FILTER=>"FamilyFilter(=,'substring:字符串的值')" //查询出某个表名列簇包含某个字符串的记录
举例 : scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822', FILTER=>"FamilyFilter(=,'substring:l')"
echo "scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>\"FamilyFilter(=,'substring:l')\"" | hbase shell
4. 按照行键进行过滤 RowFilter
a. 过滤出行键包含某个字符串的数据记录(模糊查询)
命令 : scan '表名',FILTER=>"RowFilter(=,'substring:字符串的值')"
举例 : scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>"RowFilter(=,'substring:3040')"
echo "scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>\"RowFilter(=,'substring:3040')\"" | hbase shell
b. 按照某个确定的行键进行过滤 (<,<=,=,>,>=)
命令 : scan '表名',FILTER=>"RowFilter(=,'binary:行键值')"
举例 : scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>"RowFilter(=,'binary:00_460075097670490_1534925332480')"
echo "scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>\"RowFilter(=,'binary:00_460075097670490_1534925332480')\"" | hbase shell
查询结果如下所示 : 行键为00_460075097670490_1534925332480的全部记录
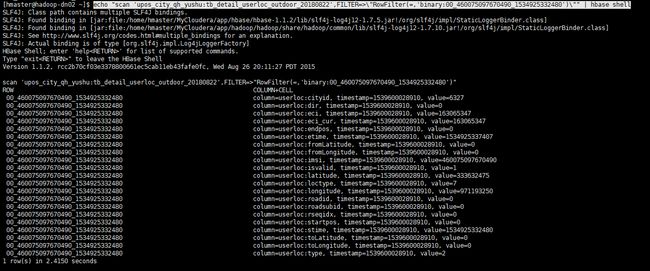
<, <=, >, >= 同理
c. 按照行键前缀进行过滤 PrefixFilter
scan '表名',FILTER=>"PrefixFilter('行键前缀')" //查询出行键以某个字符串开始的记录
scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>"PrefixFilter('00_46007509767')"
echo "scan 'upos_city_qh_yushu:tb_detail_userloc_outdoor_20180822',FILTER=>\"PrefixFilter('00_46007509767')\"" | hbase shell
二. java api的filter操作
1. 首先介绍一下 hbase过滤操作的一些参数
(1)比较运算符 CompareFilter.CompareOp
比较运算符用于定义比较关系,可以有以下几类值供选择:
EQUAL 相等
GREATER 大于
GREATER_OR_EQUAL 大于等于
LESS 小于
LESS_OR_EQUAL 小于等于
NOT_EQUAL 不等于
(2)比较器 ByteArrayComparable
通过比较器可以实现多样化目标匹配效果,比较器有以下子类可以使用:
BinaryComparator 匹配完整字节数组
BinaryPrefixComparator 匹配字节数组前缀
BitComparator
NullComparator
RegexStringComparator 正则表达式匹配
SubstringComparator 子串匹配
2. 设置hbase连接相关配置,获取hbase连接
/**
* 获取hbase连接的配置
* @param quorum 举例 : 127.0.0.1:2181
* @return
*/
private Configuration getConfiguration(String quorum)
{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", quorum);
conf.set("hbase.rootdir", "/data/hadoop/data");
conf.set("zookeeper.znode.parent", "/hbase");
return conf;
}
/**
* 获取hbase连接
* @param conf
* @return
*/
private Connection getConnection(Configuration conf)
{
Connection conn = null;
try
{
conn = ConnectionFactory.createConnection(conf);
System.out.println("获取hbase连接成功! " + conf.get("hbase.zookeeper.quorum") );
} catch (IOException e) {
System.out.println("获取hbase连接失败 " + e.getMessage());
}
return conn;
}
3. 获取scan对象,设置过滤条件
Table table = connection.getTable(TableName.valueOf(tableName));
// 通过上一步操作获取到的连接, 和想要查询的表名来获取table对象
Scan scan = new Scan(); // 获取scan对象, 通过该对象来进行查询
接下来就要设置过滤器来进行过滤查询:
如果过滤条件只有一种,直接使用各种Filter对象即可
过滤条件有多种,使用 :
FilterList filters = new FilterList(); // 过滤器集合
然后使用 scan.setFilter(filters); //将过滤器添加到进去
最后使用 ResultScanner rs = table.getScanner(scan); //即可获取结果集
java api的过滤器操作 :
a. 基于列簇的过滤器FamilyFilter
构造函数:
FamilyFilter(CompareFilter.CompareOp familyCompareOp, ByteArrayComparable familyComparator)
FamilyFilter familyFilter = new FamilyFilter(CompareOp.EQUAL , new BinaryComparator(Bytes.toBytes("info")));
//返回有列簇info的数据
b. 基于列的过滤器QualifierFilter
b1. 基于列名过滤
构造函数:
QualifierFilter(CompareFilter.CompareOp op, ByteArrayComparable qualifierComparator)
举例 :
QualifierFilter qualifierFilter = new QualifierFilter(
CompareOp.EQUAL , new BinaryComparator(Bytes.toBytes("eci")));
// 返回包含eci列的数据
b2. 基于列名前缀过滤
构造函数:
ColumnPrefixFilter(byte[] prefix)
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("i"));
//返回列名以i开头的全部数据
b3. 基于多个列名前缀过滤 MultipleColumnPrefixFilter
byte[][] bytes = new byte[][] {Bytes.toBytes("i"), Bytes.toBytes("eci")};
MultipleColumnPrefixFilter multipleColumnPrefixFilter = new MultipleColumnPrefixFilter(bytes);
//返回所有行中以i或者eci打头的列的数据
c.基于行键的过滤器RowkeyFilter(主要)
c1. 行键比较过滤器
Filter filter = null;
String filterStr = "00_460075097670490_1534925332480";
行键相等过滤器 :
filter = new PrefixFilter(Bytes.toBytes(filterStr.trim())); //返回行键内容为该指定行键的全部内容
行键不等过滤器 :
filter = new RowFilter(CompareOp.NOT_EQUAL, new BinaryComparator(filterStr.trim().getBytes()));
//返回行键不等于该指定行键的全部内容
行键小于过滤器 :
filter = new RowFilter(CompareOp.LESS, new BinaryPrefixComparator(filterStr.trim().getBytes()));
//返回行键前缀小于等于指定行键的全部内容
行键小于等于过滤器 :
filter = new RowFilter(CompareOp.LESS_OR_EQUAL, new BinaryPrefixComparator(filterStr.trim().getBytes()));
// 返回行键前缀小于等于该指定行键的全部内容
行键大于过滤器 :
filter = new RowFilter(CompareOp.GREATER, new BinaryPrefixComparator(filterStr.trim().getBytes()));
// 返回行键前缀大于等于指定行键的全部内容
行键大于等于过滤器 :
filter = new RowFilter(CompareOp.GREATER_OR_EQUAL, new BinaryPrefixComparator(filterStr.trim().getBytes()));
// 返回行键大于等于指定行键的全部内容
c2. 行键包含过滤器
行键包含过滤器 :
filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(filterStr.trim()));
// 过滤出行键包含指定字符串的全部数据
c3. 通过startkey和 endkey来进行过滤
相比以上的过滤器,在结果集的数据条数大致相同的情况下,这种过滤方式的效率明显更高
在我们的业务场景里应用的最为广泛
这种方式就不是使用Filter对象了 :
代码如下 :
String startkey = "00_460075097670490_1534925332480";
String endkey = "00_460075097670490_1534925432480"
Scan scan = new Scan();
scan.setStartRow(startkey.trim().getBytes());
scan.setStopRow(endkey.trim().getBytes());
// 查询从起始行键到结束行键的全部记录数
// 注意 : 包括起始行键和结尾行键!!
4. 根据之前获取到的ResultScanner对象, 遍历结果集并输出结果:
ResultScanner rs = table.getScanner(scan);
for (Result result : rs) {
List<Cell> cells= result.listCells();
for (Cell cell : cells) {
String row = Bytes.toString(result.getRow());
String family1 = Bytes.toString(CellUtil.cloneFamily(cell));
String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println("[row:"+row+"],[family:"+family1+"],[qualifier:"+qualifier+"]"
+ ",[value:"+value+"],[time:"+cell.getTimestamp()+"]");
}
}
参考的博客链接: