BoW词袋模型原理学习及Python实现
文章目录
- BoW词袋模型原理
- 为什么要用BoW模型描述图像
- 构建BoW码本步骤
- 编码
- 测试
BoW词袋模型原理
BoW(Bag of Words)词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
为什么要用BoW模型描述图像
SIFT特征虽然也能描述一幅图像,但是每个SIFT矢量都是128维的,而且一幅图像通常都包含成百上千个SIFT矢量,在进行相似度计算时,这个计算量是非常大的,通行的做法是用聚类算法对这些矢量数据进行聚类,然后用聚类中的一个簇代表BoW中的一个视觉词,将同一幅图像的SIFT矢量映射到视觉词序列生成码本,这样每一幅图像只用一个码本矢量来描述,这样计算相似度时效率就大大提高了
构建BoW码本步骤
1、 假设训练集有M幅图像,对训练图象集进行预处理。包括图像增强,分割,图像统一格式,统一规格等等。
2、提取SIFT特征。对每一幅图像提取SIFT特征(每一幅图像提取多少个SIFT特征不定)。每一个SIFT特征用一个128维的描述子矢量表示,假设M幅图像共提取出N个SIFT特征。
3、用K-means对2中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
4、构造码本。码本矢量归一化因为每一幅图像的SIFT特征个数不定,所以需要归一化。测试图像也需经过预处理,提取SIFT特征,将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。
编码
整个过程一共三件事情
1、首先提取对n幅图像分别提取SIFT特征.
2、然后对提取的整个SIFT特征进行KMeans聚类得到k个聚类中心作为视觉单词表(或者说是词典).
3、最后对每幅图像以单词表为规范对该幅图像的每一个SIFT特征点计算它与单词表中每个单词的距离,最近的+1,便可得到该幅图像的码本。
首先编写searchFeatures.py
import argparse as ap
import cv2
import numpy as np
import os
from sklearn.externals import joblib
from scipy.cluster.vq import *
from sklearn import preprocessing
# Get the path of the training set
parser = ap.ArgumentParser()
parser.add_argument("-t", "--trainingSet", help="Path to Training Set", required="True")
args = vars(parser.parse_args())
# Get the training classes names and store them in a list
train_path = args["trainingSet"]
#
training_names = os.listdir(train_path)
numWords = 1000
# Get all the path to the images and save them in a list
# image_paths and the corresponding label in image_paths
image_paths = []
for training_name in training_names:
image_path = os.path.join(train_path, training_name)
image_paths += [image_path]
# Create feature extraction and keypoint detector objects
fea_det = cv2.FeatureDetector_create("SIFT")
des_ext = cv2.DescriptorExtractor_create("SIFT")
# List where all the descriptors are stored
des_list = []
for i, image_path in enumerate(image_paths):
im = cv2.imread(image_path)
print "Extract SIFT of %s image, %d of %d images" %(training_names[i], i, len(image_paths))
kpts = fea_det.detect(im)
kpts, des = des_ext.compute(im, kpts)
des_list.append((image_path, des))
# Stack all the descriptors vertically in a numpy array
descriptors = des_list[0][1]
for image_path, descriptor in des_list[1:]:
descriptors = np.vstack((descriptors, descriptor))
# Perform k-means clustering
print "Start k-means: %d words, %d key points" %(numWords, descriptors.shape[0])
voc, variance = kmeans(descriptors, numWords, 1)
# Calculate the histogram of features
im_features = np.zeros((len(image_paths), numWords), "float32")
for i in xrange(len(image_paths)):
words, distance = vq(des_list[i][1],voc)
for w in words:
im_features[i][w] += 1
# Perform Tf-Idf vectorization
nbr_occurences = np.sum( (im_features > 0) * 1, axis = 0)
idf = np.array(np.log((1.0*len(image_paths)+1) / (1.0*nbr_occurences + 1)), 'float32')
# Perform L2 normalization
im_features = im_features*idf
im_features = preprocessing.normalize(im_features, norm='l2')
joblib.dump((im_features, image_paths, idf, numWords, voc), "bof.pkl", compress=3)
将上面的文件保存为serachFeatures.py,前面主要是一些通过parse使得可以在敲命令行的时候可以向里面传递参数,后面就是提取SIFT特征,然后聚类,计算TF和IDF,得到单词直方图后再做一下L2归一化。一般在一幅图像中提取的到SIFT特征点是非常多的,而如果图像库很大的话,SIFT特征点会非常非常的多,直接聚类是非常困难的(内存不够,计算速度非常慢),所以,为了解决这个问题,可以以牺牲检索精度为代价,在聚类的时候先对SIFT做降采样处理。最后对一些在在线查询时会用到的变量保存下来。对于某个图像库,我们可以在命令行里通过下面命令生成BoF。
python serachFeatures.py -t ../dataset/test/
之后进行查找,本程序只能每次查找一张图片,并返回与之匹配度(递减)最接近的6张图片
编写query.py如下
import argparse as ap
import cv2
from sklearn.externals import joblib
from scipy.cluster.vq import *
from sklearn import preprocessing
from pylab import *
from PIL import Image
# Get the path of the training set
parser = ap.ArgumentParser()
parser.add_argument("-i", "--image", help="Path to query image", required="True")
args = vars(parser.parse_args())
# Get query image path
image_path = args["image"]
# Load the classifier, class names, scaler, number of clusters and vocabulary
im_features, image_paths, idf, numWords, voc = joblib.load("bof.pkl")
# Create feature extraction and keypoint detector objects
fea_det = cv2.FeatureDetector_create("SIFT")
des_ext = cv2.DescriptorExtractor_create("SIFT")
# List where all the descriptors are stored
des_list = []
im = cv2.imread(image_path)
kpts = fea_det.detect(im)
kpts, des = des_ext.compute(im, kpts)
des_list.append((image_path, des))
# Stack all the descriptors vertically in a numpy array
descriptors = des_list[0][1]
test_features = np.zeros((1, numWords), "float32")
words, distance = vq(descriptors,voc)
for w in words:
test_features[0][w] += 1
# Perform Tf-Idf vectorization and L2 normalization
test_features = test_features*idf
test_features = preprocessing.normalize(test_features, norm='l2')
score = np.dot(test_features, im_features.T)
rank_ID = np.argsort(-score)
# Visualize the results
figure()
gray()
fig=subplot(3,3,1)
imshow(im[:,:,::-1])
title("Query: "+image_path[-9:-4])
axis('off')
for i, ID in enumerate(rank_ID[0][0:6]):
img = Image.open(image_paths[ID])
gray()
subplot(3,3,i+4)
imshow(img)
title("Detected:"+str(i+1)+" "+image_paths[ID][-9:-4])
axis('off')
show()
对某幅图像进行查询时,只需在命令行里输入:
python query.py -i ../dataset/test/img01.ppm
测试
选取十张照片进行测试,每次搜索返回6张相似度(按递减排序)最接近图片,结果如下

第1次查询

第2次查询
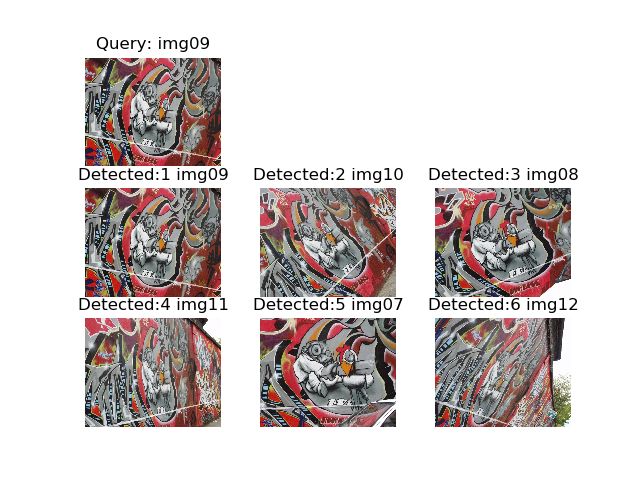
第3次查询

第4次查询

第5次查询

第6次查询

第7次查询

第8次查询

第9次查询

第10次查询
通过搜索结果我们发现,每次搜索的结果均正确,故精确率为100%,召回率为有2次为83%,8次为100%,平均值为96.6%。分析导致这一情况是由于数据集太少导致的,如果增加数据集,会让精确率和召回率更准确
github项目下载链接
CSDN项目下载链接